由于工作需要,最近开始弄k-means、KNN、GMM聚类。总结一下这两种聚类方法吧。
1. K-means
原理:这基本上是最简单也最经典的聚类方法。K是指所要聚的cluster的数量,means是指每一个cluster都有一个中心点(质心),这个质心是cluster中所有点的平均值,分别计算样本中每个点与K个质心的欧式距离,离哪个质心最近,这个点就被划到哪一类中。
K是我们预先设置的值,K-means和GMM都无法自动分出有几类,都必须由我们来设定k值。
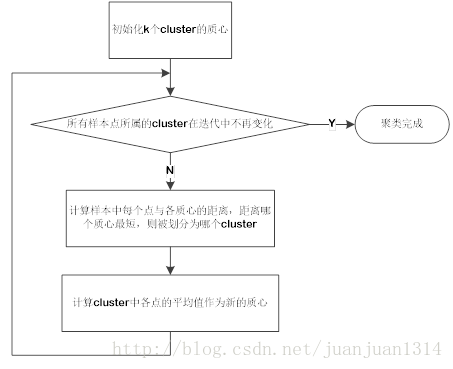
算法过程:
一开始,我们无法知道各cluster的点到底有哪些,也就无法得到各means,因此,先初始化K个质心点。初始化的方式有很多,可以随机在样本中选择k个点作为质心,也可以计算样本各维的最大值和最小值,然后在最大值与最小值之间找k个值,这样找出k个点。然后。再计算各cluster的平均值,如此不断迭代,直到所有点真的找到最短距离的质心为止。
2.GMM
GMM是高斯混合模型(或者是混合高斯模型)的简称。大致的意思就是所有的分布可以看做是多个高斯分布综合起来的结果。这样一来,任何分布都可以分成多个高斯分布来表示。
因为我们知道,按照大自然中很多现象是遵从高斯(即正态)分布的,但是,实际上,影响一个分布的原因是多个的,甚至有些是人为的,可能每一个影响因素决定了一个高斯分布,多种影响结合起来就是多个高斯分布。(个人理解)
因此,混合高斯模型聚类的原理:通过样本找到K个高斯分布的期望和方差,那么K个高斯模型就确定了。在聚类的过程中,不会明确的指定一个样本属于哪一类,而是计算这个样本在某个分布中的可能性。
高斯分布一般还要结合EM算法作为其似然估计算法。
整个模型涉及到的公式如下:
2.1高斯分布
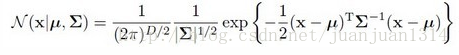
高斯分布的似然估计

EM算法涉及的公式
凸函数:f[(a+b)/2]≥[f(a)+f(b)]/2
Jensen不等式:如果f是凸函数,X是随机变量,那么f(E(X))≥E(f(x)),等号成立的条件是x=E(X),是常数,那么f也将是常数。
高斯分布的似然估计就是凸函数,因此,其极大似然估计值发生在变量值为期望值时,此时,似然估计函数为常数。
因此,当计算出来的似然估计不再变化时,即是最大的似然估计,以此时的参数最优。
算法过程:
整个算法其实就是不断计算以下3个公式的过程:
第i个样本在第k个分布中的概率
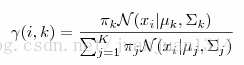
第k个分布的期望值
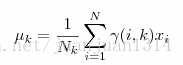
第k个分布的方差
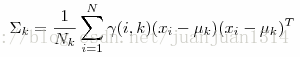
其中第一个公式是由上一次计算出来的k个分布的期望和方差分别计算样本在k分布中的概率,因此,需要初始化k个分布的期望和方差,然后进入不断的迭代中,直到似然估计值不再变化,迭代终止。
3. K近邻(KNN)
K近邻的原理:在训练数据集中找到与目标实例最邻近的k个实例,这k个实例的多数属于哪一类,就把目标实例归为哪一类。
K近邻和K-means都是以距离来度量的,但前者属于有监督类的,而后者是非监督的,自动聚类,两者都是无参数学习方法。尤其是KNN,说是训练数据集,但实际上模型本身似乎没有学习这个过程。
同前两个学习方法,KNN中的k也是一个需要预先设定的超参数。
KNN的实现:kd树
最后
以上就是喜悦西牛最近收集整理的关于k-means、GMM聚类、KNN原理概述的全部内容,更多相关k-means、GMM聚类、KNN原理概述内容请搜索靠谱客的其他文章。








发表评论 取消回复