在机器学习领域,我们可以区分为两个主要领域:监督学习和无监督学习。两者的主要区别在于数据的性质以及处理数据的方法。聚类是一种无监督学习问题,我们希望在数据集中找到具有某些共同特征的点的聚类。假设我们有这样一个机器学习数据集:
我们的工作是找到一组看起来很接近的点。在这种情况下,我们可以清楚地识别出两组点,我们将分别把它们标记成蓝色和红色:
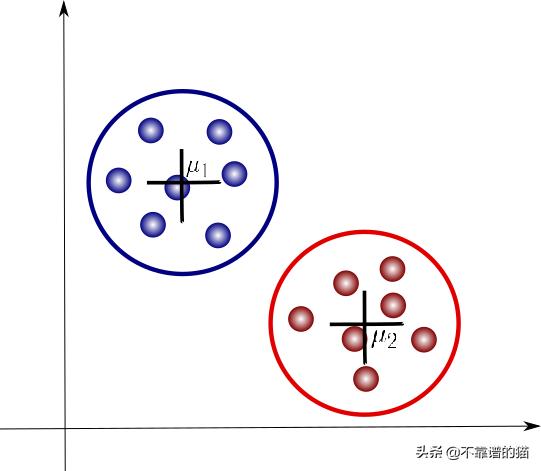
请注意,我们现在引入了一些额外的符号。这里,μ1和μ2是每个聚类的质心。一种流行的聚类算法为K-means,它将遵循迭代方法来更新每个聚类的参数。更具体地说,它将做的是计算每个聚类的均值(或质心),然后计算它们与每个数据点的距离。然后将后者标记为由其最接近的质心识别的聚类的一部分。重复此过程,直到满足某些收敛标准,例如,当我们看不到聚类分配中的进一步更改时。
K-means的一个重要特点是它是一种硬聚类方法,这意味着它将每个点关联到一个且只有一个聚类。这种方法的一个局限性在于,当有一些点过于靠近给定聚类的边界时,这些点可能会被错误地标记。那么,如何使用软聚类而不是硬聚类呢?这正是高斯混合模型(或简称为GMM)试图做的。现在
最后
以上就是朴实刺猬最近收集整理的关于高斯混合模型聚类_高斯混合模型的解释及Python实现定义初步推导在Python中实现的全部内容,更多相关高斯混合模型聚类_高斯混合模型内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复