进入主题前的一句唠叨
如果说,Delta带来的三大核心特性:
- 流批共享
- upsert/delete/overwrite等操作
- 版本回滚
让我选最核心的特性的话,我会选择第二个。在大数据领域,我们也是一步步进化的,从最早的数据存储采用纯文本,到后面ORC/Parquet等面向读的格式。但是他们都存在一个一个很大的问题,就是不可变,只增。但现实中的业务场景里太需要Upsert这个功能了。有了这个功能,对架构来说真的是如沐春风。
当然,单独的更新功能没啥值得骄傲的,像HBase,Kudu等等都有,但是Delta的更新功能是建立在流批共享表的基础上,同时还不增加额外复杂度,这种情况下就显得难能可贵了。
一起来探秘
更新有很多种类,这个章节我们只会介绍Delta是如何实现Upsert语义的操作。前面我们说,Delta表由两部分构成:
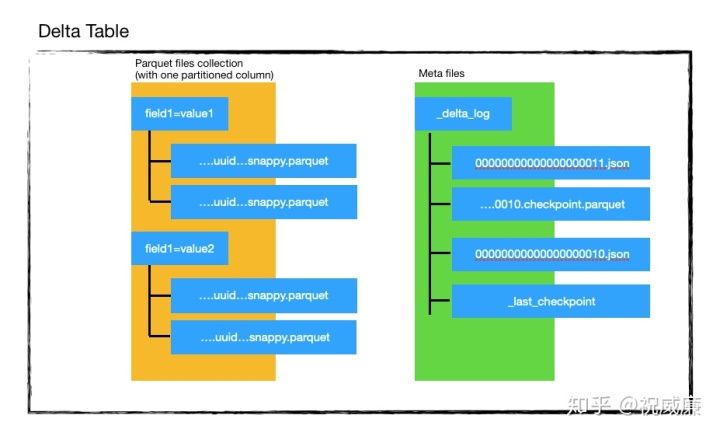
一堆的parquet文件和记录操作日志的json文件(以及checkpoint用的parquet文件)。在讲解upsert操作前,我们先看看如果要新增记录,文件的变化会是什么样子的:
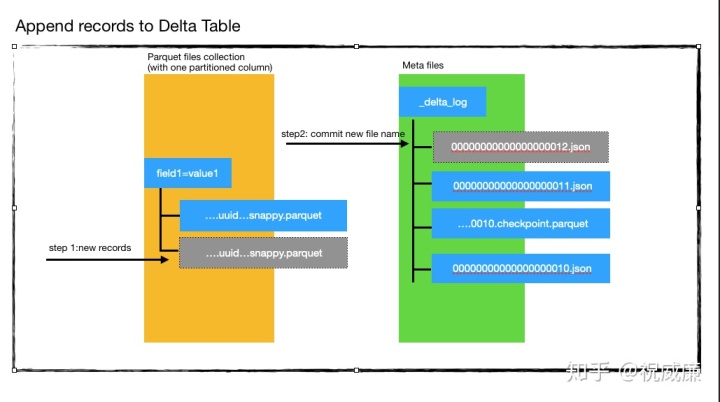
往Delta写入新数据,主要有三个步骤(如图描述):
- 将新数据保存成新的parquet文件(图中灰色部分)。
- 进行commit操作,创建一个新的json文件(形成类似000...0012.json,图中灰色部分),这个json文件会比较新增的parquet文件是哪些。
- 此时相当于新增加了一个版本,其他的reader就可以读到最新的文件了。
我们看到,新增的过程不影响其他用户读Delta表。现在让我们看看如何实现Upsert语义:
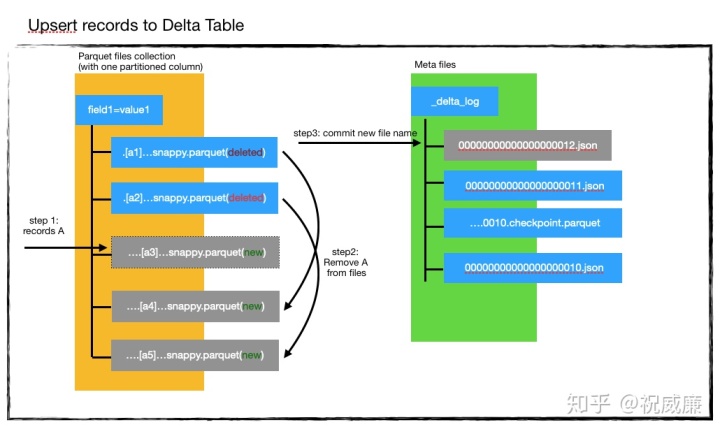
假设delta表里面已经有a1,a2两个parquet文件,然后当前的版本号是11,你看图应该很容易看出来。现在有一批数据A要进来,这批数据有部分是新增,有部分是已经存在于a1,a2中的。我们会通过如下五个步骤来完整整个Upsert操作:
- 使用进来的数据A创建一个a3文件。 这个阶段,显然有数据重复了,因为A里部分数据是a1,a2已经存在的。
- 读取a1,a2的数据,和A求差集,也就是过滤掉A中在a1,a2里出现的数据,然后创建新的文件a3,a4,a5。这个时候所有的老数据都有了一份。
- 现在,我们标记删除所有的老数据在的parquet文件,也就是a1,a2。现在目录里应该只有a3,a4,a5三个文件。a3是A集合的数据,a4,a5是去掉和A重复的数据,他们构成了完整的一个数据集。
- 现在系统会检测当前的版本号是不是11,记得我们刚开始事务的时候么我们发现版本号是11,如果现在还是11,说明没有人更改过数据,所以我们可以放心的提交。否则,我们可能需要重新执行所有流程。
- 提交数据,生成000…012.json. 该文件表示版本号为12,同时里面会标记删除了a1,a2,同时a3,a4,a5为新增的parquet文件。
这个时候其他用户已经可以读取到版本12的所有数据了。
从上面描述我们可以看到,Delta做更新操作是个比较重的操作,他需要遍历所有数据找到和当前数据不重复的数据然后生成新的文件,然后删掉老的文件。我们也有一些优化空间可以做,比如如果用户的条件包含了分区字段,那么我们只要抽取集合A涉及到的分区,然后再去读对应的delta表中的文件,这可以避免全表扫描。
我们还可以得出下面几个结论,而这几个结论也是大家非常容易困惑的地方:
- 更新一条和1000条数据对delta来说,性能可能不会有什么差别。
- Delta不适合对单条数据做upsert,因为overhead 太高。最好是能一批一批的去做upsert.这和传统的比如hbase,MySQL等是不一样的。
- Delta本质上是在不断的产生新的文件,然后又因为是比较删除,所以文件增长会非常快。
1,2是没有太大办法解决的,因为设计就是如此。 第三点应该是很多用户会明确感受到的,对此也是有解决方案的。首先我们不会保留太多版本,则意味着我们可以清理掉老版本里所有被标记删除的文件,从而实现真正的减少文件。同时,我们也可以每次commit生成的文件数,避免产生过多小文件。
乐观锁
前面我们其实回避了一个问题,就是如果有多个写同时发生怎么办?对于并发,我们肯定还是回避不了锁的问题。Delta采用了乐观锁,乐观锁的概念是什么呢?就所有准备工作都做好了,数据也搞好了,只有在最后commit的时候才会检查写冲突。检查冲突其实只有两个结果
- 运气好,没有冲突,提交成功。
- 运气不好,冲突了
运气好咱没啥说的。现在我们看看,运气不好的时候咋办。如果冲突了,则意味文件已经被更改,问题是我们乐观锁是我们在检测冲突前,就把所有的工作都做了(比如整个更新流程),相当于花了大力气,现在核心的问题是,这些工作要不要重做。要不要重做取决于你是不是依赖于读取表里的数据。对于纯新增数据操作,我们是不读取原始表的数据的,所以我们发现冲突后,只要在冲突的版本上重试申请新的版本即可,并不需要重新写数据。但是对于upsert操作,因为我们读取了原始表的数据,现在别人原始表的数据已经变化了,这就表示你之前的工作需要重做,否则就相当于你覆盖掉了别人的操作(就是抢在你之前提交了数据的人),所以你必须重新做之前做过的一整套流程,然后再进行检测,直到提交成功。
通过这里我们可以看出,乐观锁在需要读取原始数据的情况下是其实是非常不适合并发操作的。这意味着,Delta是适合写少读多的场景。前面我们提到,因为upsert是个很重的操作,所以不适合一条一条执行,要一批一批执行,这是一个原因点。还有一个就是基于并发的考虑,用户想一条一条执行,为了能执行的更快,就会放到多线程里,这个时候因为delta又不适合并发写,会导致很多任务不断重试,而每个任务又是很重的操作,导致集群资源无意义的浪费并且严重降低了吞吐。
本章结束语
到目前为止,我们看到了Delta是如何支持更新的,以及使用乐观锁来解决并发写的问题。因为我们在原理探讨了上面的问题,所以我们知道了Delta如下几个特点:
- Delta支持更新语义,但是更新操作是个很重的操作。
- Delta的更新最好是一批一批更新,不要一条一条更新。基本上一条一条更新是你可以理解为不work的。
- Delta采用乐观锁,所以适合写少读多的场景
最后
以上就是直率铃铛最近收集整理的关于更新json文件_更新操作的秘密的全部内容,更多相关更新json文件_更新操作内容请搜索靠谱客的其他文章。








发表评论 取消回复