目录
- 哨兵节点管理
- 增加
- 删除
- slave的永久下线
- slave切换为Master的优先级
- 基于哨兵集群架构下的安全认证
- 容灾演练
- master发生故障
- 故障恢复
- 总结过程
- 哨兵启动生产环境配置
哨兵节点管理
增加
增加sentinal,会自动发现,过程参考上一篇14. 【实战】在项目中重新搭建一套读写分离+高可用+多master的redis cluster集群
删除
删除sentinal的步骤
- 停止master节点 sentinal进程
SENTINEL RESET *,在所有sentinal上执行,清理所有的master状态SENTINEL MASTER mastername,在所有sentinal上执行,查看所有sentinal对数量是否达成了一致
slave的永久下线
让master摘除某个已经下线的slave:SENTINEL RESET mastername,在所有的哨兵上面执行
slave切换为Master的优先级
slave->master选举优先级:slave-priority,值越小优先级越高
基于哨兵集群架构下的安全认证
每个slave都有可能切换成master,所以每个实例都要配置两个指令
- master上启用安全认证,
requirepass - slave连接口令,
masterauth
sentinal,sentinel auth-pass <master-group-name> <pass>
容灾演练
master发生故障
-
通过哨兵看一下当前的master:
SENTINEL get-master-addr-by-name mymaster

-
把
redis master节点kill -9掉,pid文件也删除掉
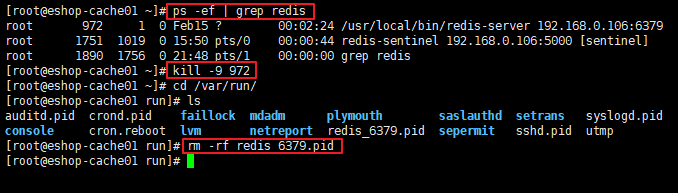
-
查看sentinel的日志,是否出现
+sdown字样,识别出了master的宕机问题;然后出现+odown客观宕机,就是指定的quorum哨兵数量都认为master宕机了。
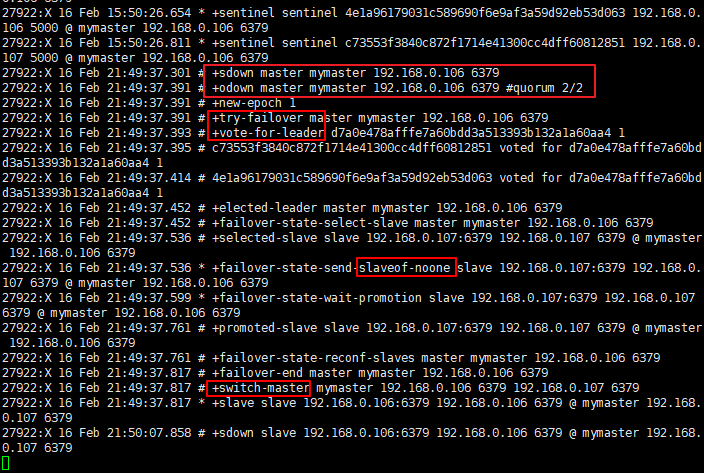
(1)三个哨兵进程都认为master是sdown了
(2)超过quorum指定的哨兵进程都认为sdown之后,就变为odown
(3)哨兵1是被选举为要执行后续的主备切换的那个哨兵
(4)哨兵1去新的master(slave)获取了一个新的config version
(5)尝试执行failover
(6)投票选举出一个slave区切换成master,每隔哨兵都会执行一次投票
(7)让salve,slaveof noone,不让它去做任何节点的slave了; 把slave提拔成master; 旧的master认为不再是master了
(8)哨兵就自动认为之前的 master 192.168.0.106:6379变成了slave了,192.168.0.107:6379变成了master了
(9)哨兵去探查了一下192.168.0.106:6379这个salve的状态,认为它sdown了
-
所有哨兵选举出了一个slave,来执行主备切换操作,如果哨兵的
majority都存活着,那么就会执行主备切换操作 -
再通过哨兵看一下原来的master:
SENTINEL get-master-addr-by-name mymaster

-
尝试连接一下新的master,查看redis 信息
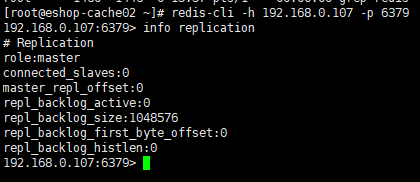
故障恢复
再将旧的master重新启动,查看是否被哨兵自动切换成slave节点
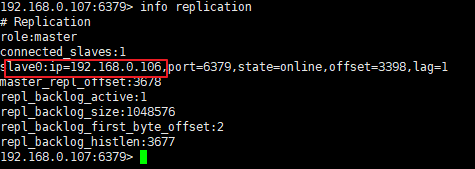
总结过程
- 手动杀掉master
- 哨兵能否执行主备切换,将slave切换为master
- 哨兵完成主备切换后,新的master能否使用
- 故障恢复,将旧的master重新启动
- 哨兵能否自动将旧的master变为slave,挂接到新的master上面去,而且也是可以使用的
哨兵启动生产环境配置
- 之前哨兵启动的时候,
redis-sentinel /etc/sentinal/5000.conf,直接显示控制台,ctrl+c会直接杀死进程,这种只适合在测试环境中; - 生产环境中配置下面:
mkdir -p /var/log/sentinal/5000
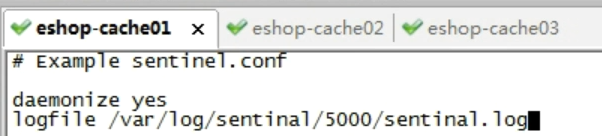
daemonize yes ## 后台方式启动
logfile /var/log/sentinal/5000/sentinal.log
最后
以上就是激动小蝴蝶最近收集整理的关于15. 哨兵节点管理以及高可用redis集群的容灾演练哨兵节点管理容灾演练哨兵启动生产环境配置的全部内容,更多相关15.内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复