本文共分为三个部分
-
第一部分:Linux环境安装
Hadoop运行在Linux环境中,虽然借助工具也可以部署在Windows上,但是还是建议在Linux环境中进行部署,第一部分将简单介绍Linux环境的安装、配置、JDK安装
-
第二部分:Hadoop本地模式安装
Hadoop本地模式只能用于本地的开发和调试,如果想要快速体验一下Hadoop,本地模式是我们的不二选择
-
第三部分:Hadoop伪分布式模式配置
Hadoop的学习一般都在伪分布式模式下进行,之所以叫伪分布式模式是因为虽然各个模块势在各个进程中分开运行的,但是只是运行在一个操作系统中,并不是真正的分布式,我们将着重介绍这部分,并尝试敲一个简单的项目
-
第四部分:结语和一个小项目
一个简单的小项目,见下一篇博客
Linux环境安装
一、安装Vmware WorkStation和下载Ubuntu安装包
Vmware WorkStation的安装和一般软件的安装没有差别,一路next就可以了。同时下载好Ubuntu的安装包备用
二、虚拟网络编辑器的设置(NAT模式设置)
NAT意为网络地址转换,是在主机和虚拟机之间架设一个地址转换服务,负责外部和虚拟机之间的网络通讯转接和IP映射,我们部署Hadoop集群要求各个虚拟机有固定的IP,可以访问外网,需要进行以下配置
- 默认NAT设置
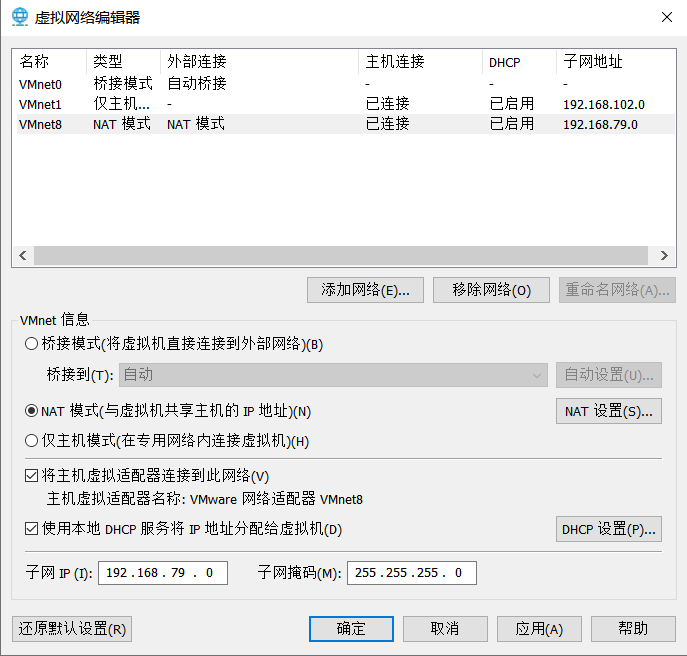
- 取消DHCP服务
默认的NAT设置是启用DHCP服务的,NAT服务会自动将IP地址分配给虚拟机,但是我们需要将各个虚拟机的IP固定下来所以取消掉这个默认设置
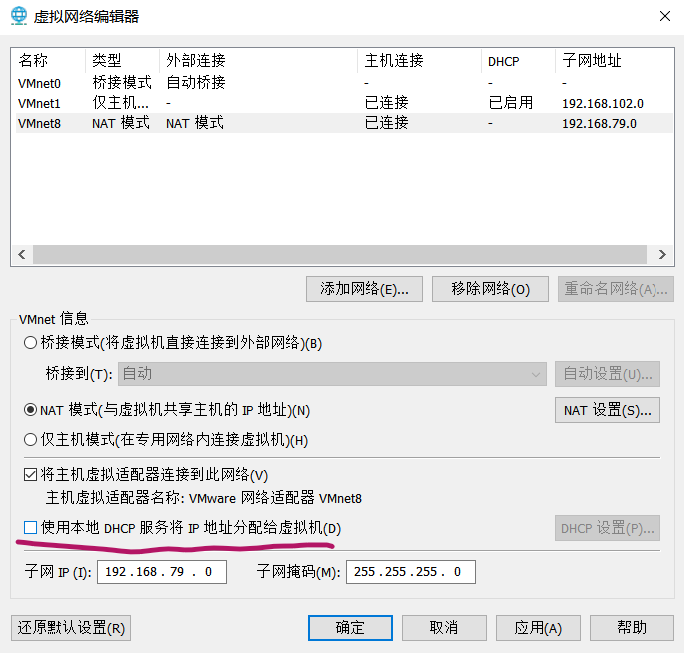
- 为机器设置一个子网网段
机器默认是192.168.136网段,我们在这里修改为192.168.79网段,将来各个虚拟机的IP就为192.168.79.***
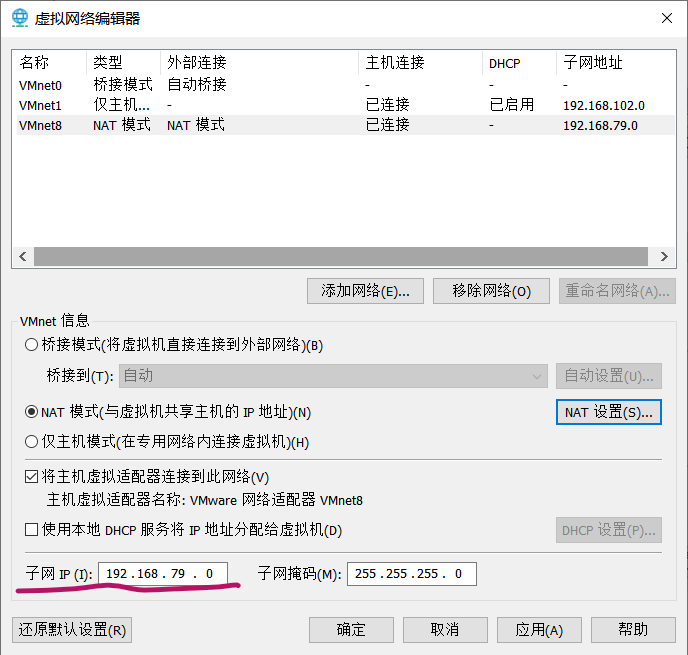
- 为机器设置DNS地址
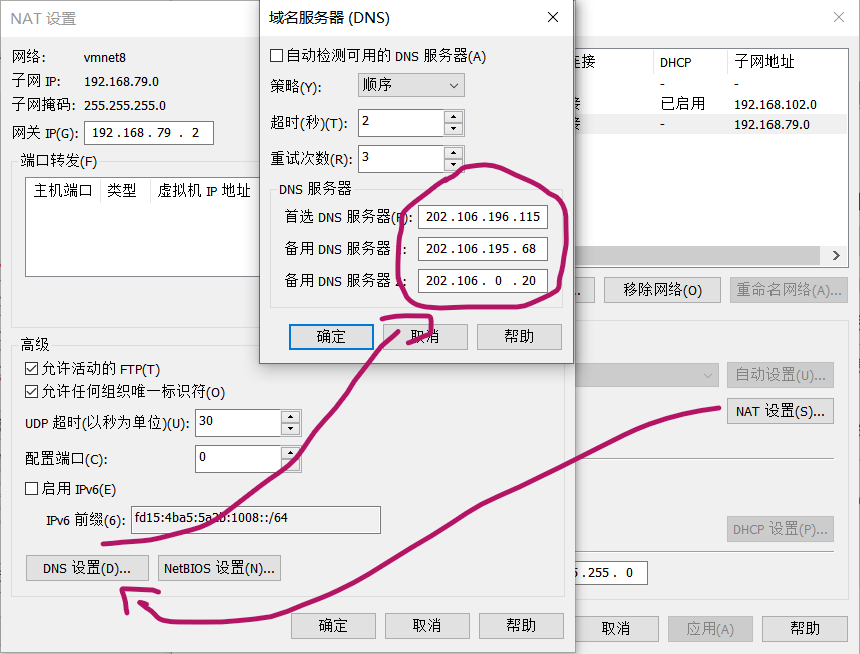
三、在Vmware WorkStation中安装Ubuntu
-
文件菜单选择新建虚拟机
-
选择经典类型安装
-
选择稍后安装操作系统
-
选择Linux系统,选择版本Ubuntu64位
-
命名虚拟机,并选择Linux系统保存在主机的哪个目录下,一个虚拟机应该独立拥有一个目录,切记不要让多个虚拟机使用同一个目录
-
指定磁盘容量,设置分配给此虚拟机的硬盘空间的大小,默认20GB,不变
-
点击完成之后,我们就已经完成了虚拟机的创建了,但是此时的虚拟机还没有操作系统,还记得我们之前下载的Ubuntu的安装包吗,到了它发挥作用的时候了
-
点击编辑虚拟机设置,点击DVD,指定操作系统ISO文件的位置,也就是Ubuntu安装包的位置
-
点击启动虚拟机,开始安装Ubuntu
-
Ubuntu的安装步骤这里就不详细展开了,网上有许多相关的教程和解答,我们直接跳到Ubuntu的网络设置
-
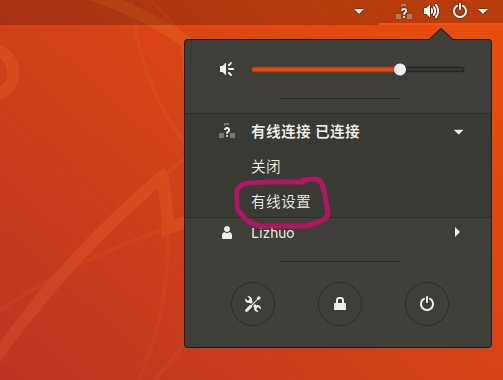
点击有线设置
-
点击有线网络开关右侧的齿轮图标
-
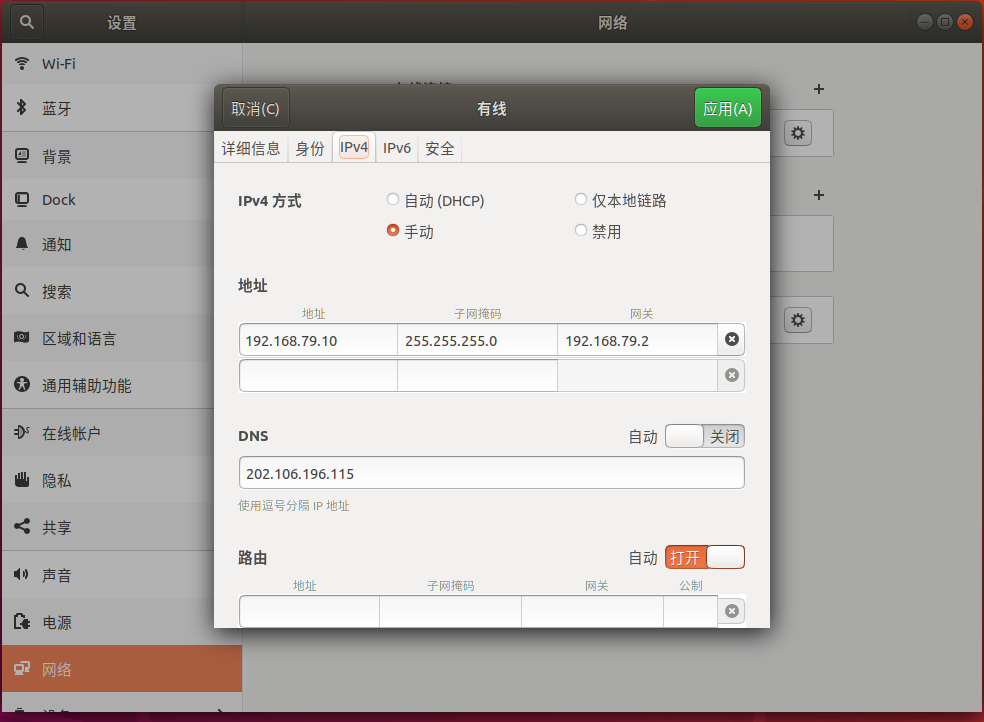
配置IP、子网掩码、网关和DNS,因为在之前的NAT设置中我们将网段设置为192.168.79.***,所以这里我们将IP设置为192.168.79.10,其余三项设置与NAT设置保持一致
-
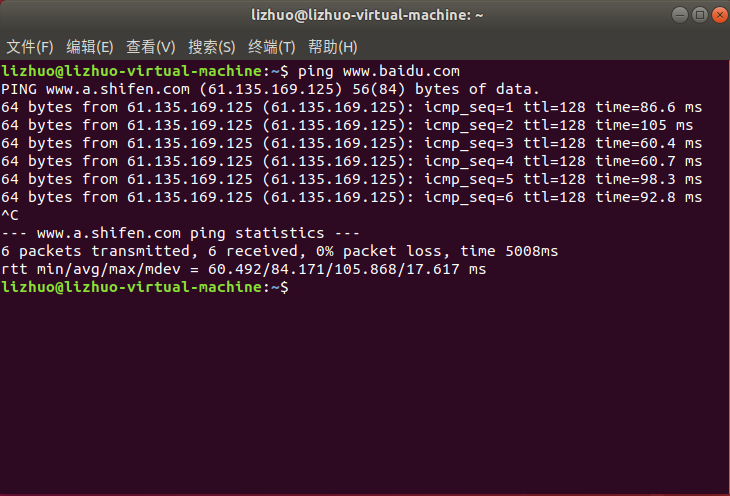
使用 ping 命令检查是否可以连接外网,如下图,连接成功
四、配置SSH
-
首先更新apt包
sudo apt-get update -
安装SSH Server
sudo apt-get install openssh-server -
输入密码登陆本机及退出
ssh localhost exit -
设置无密码登陆(对于Hadoop来说,这步是需要的),在进行了初次登陆之后,会在当前跟目录下生成一个.ssh文件家,进入该文件夹,使用rsa算法生成密钥和公钥对
cd ~/.ssh/ ssh-keygen -t rsa -
把公钥加入到授权中
cat ./id_rsa.pub >> ./authorized_keys
五、修改Hostname
-
安装VIM
sudo apt-get install vim -
修改hosts配置文件
sudo vim /etc/host -
添加hosts,使用我们之前在虚拟机有线网络设置中的IP,和你自己设置的虚拟机名字(没有接触过VIM的同学看这里:打开文件之后,键入’i’开始编辑,编辑结束之后,键入‘ESC’和’:wq’,回车退出文件)
192.168.79.10 lizhuo-virtual-machine -
关闭防火墙,在学习环境下我们可以将防火墙关闭以免造成不必要的问题
sudo ufw disable // 关闭防火墙 sudo ufw status // 查看防火墙状态
六、安装JDK
-
首先检查是否已经安装jdk
java -version -
如果没有安装,请在官网下载jdk,注意看清版本和位数,我们这里选择jdk-12.0.2_linux-x64_bin.tar.gz
-
为了方便,为其单独创建一个文件夹,然后将我们下载好的jdk放到改文件夹之下,注意这里下载好的jdk文件的路径以自己的为准
sudo mkdir -p /usr/lcoal/java sudo mv /home/lizhuo/download/jdk-12.0.2_linux-x64_bin.tar.gz -
解压,解压成功之后会在当前目录下看到jdk-12.0.2文件夹
cd /usr/local/java sudo tar xvzf jdk-12.0.2_linux-x64_bin.tar.gz -
配置环境变量,回到根目录,追加语句
sudo vim /etc/profile在文件末尾添加以下语句
export JAVA_HOME=/usr/local/java/jdk-12.0.2 export PATH=${JAVA_HOME}/bin:$PATH -
更新资源
source /etc/profile -
再次执行java -version,看到以下信息即安装成功
lizhuo@lizhuo-virtual-machine:~$ java -version java version "12.0.1" 2019-04-16 Java(TM) SE Runtime Environment (build 12.0.1+12) Java HotSpot(TM) 64-Bit Server VM (build 12.0.1+12, mixed mode, sharing)
至此,Linux环境安装完成…
二、Hadoop本地模式安装
-
下载Hadoop安装包
镜像:https://mirrors.cnnic.cn/apache/hadoop/common/
需要注意的是,我们要选择稳定版本,在stable/中有三个文件,src是源码需要编译,我们需要的是hadoop-3.2.0.tar.gz这个版本
-
解压安装包
sudo tar -zxf ~/home/lizhuo/download/hadoop-3.2.0.tar.gz -C /usr/local -
删除安装包
rm ~/home/lizhuo/download/hadoop-3.2.0.tar.gz -
修改权限,为了方便我们将目标文件夹重命名
cd /usr/local/ sudo mv ./hadoop-3.2.0 ./hadoop sudo chown -R lizhuo(你的用户名) ./hadoop -
检测是否安装成功
./usr/local/hadoop/bin/hadoop version出现以下信息即代表安装成功
lizhuo@lizhuo-virtual-machine:~$ hadoop version Hadoop 3.2.0 Source code repository https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bf Compiled by sunilg on 2019-01-08T06:08Z Compiled with protoc 2.5.0 From source with checksum d3f0795ed0d9dc378e2c785d3668f39 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.0.jar -
无需做任何修改,按照以上步骤安装成功后,Hadoop即处于默认的单机模式,Hadoop内置了许多小demo可以供我们玩耍,如果有兴趣的话,可以试一试
至此,Hadoop单机模式安装完成…
三、Hadoop伪分布式配置
配置Hadoop伪分布式部署需要修改两个配置文件,分别是core-site.xml和hdfs-site.xml,这两个文件都在/usr/local/hadoop/etc/hadoop路径下
-
登陆ssh
ssh localhost -
进入该路径
cd /usr/local/hadoop/etc/hadoop -
修改core-site.xml文件
vim core-site.xml找到configuration节点,在其中追加以下语句:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://lizhuo-virtual-machine(使用你自己的虚拟机名称):9000</value> </property> </configuration> -
修改hdfs-site.xml文件
vim hdfs-site.xml找到configuration节点,在其中添加以下语句:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>配置说明:Hadoop的运行模式是由其配置文件决定的,Hadoop每次启动的时候都会读取这些配置文件,所以如果我们想要从单机模式切换到伪分布式模式就必须要修改Hadoop的配置文件,反之亦然,如果我们想要切回单机模式需要删除core-site.xml中configuration节点中的语句.
-
格式化Namenode
回到Hadoop根目录,执行以下语句
./bin/hdfs namenode -format出现以下信息即代表namenode初始化成功
00000000 using no compression 19/03/17 11:07:16 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 320 bytes saved in 0 seconds . 19/03/17 11:07:16 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 19/03/17 11:07:16 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at lizhuo-virtual-machine/192.168.79.10 ************************************************************/ -
启动Hadoop伪分布式模式
./sbin/start-dfs.sh应出现以下内容
lizhuo@lizhuo-virtual-machine:/usr/local/hadoop$ ./sbin/start-dfs.sh Starting namenodes on [lizhuo-virtual-machine] Starting datanodes Starting secondary namenodes [lizhuo-virtual-machine] -
验证Hadoop是否启动成功
jps出现以下四项即代表Hadoop伪分布式模式启动成功
lizhuo@lizhuo-virtual-machine:/usr/local/hadoop$ jps 3027 DataNode 2868 NameNode 3256 SecondaryNameNode 3438 Jps -
Hadoop环境变量配置
如果不配置Hadoop环境变量的话,每次启动和关闭Hadoop都要进入到Hadoop的/sbin目录下,还是很麻烦的,所以建议对Hadoop的环境变量进行配置
vim /etc/profile在我们之前配置Java环境变量的语句之后追加以下语句
export HADOOP_HOME=/usr/local/hadoop export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH关闭vim命令与前面相同,这里就不赘述了
-
最后验证一下
lizhuo@lizhuo-virtual-machine:/$ hadoop version Hadoop 3.2.0 Source code repository https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bf Compiled by sunilg on 2019-01-08T06:08Z Compiled with protoc 2.5.0 From source with checksum d3f0795ed0d9dc378e2c785d3668f39 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.0.jar
至此,Hadoop伪分布式模式的配置完成…
四、结语和一个小项目
Hadoop在整个大数据技术体系中占有至关重要的地位,是大数据技术的基础和敲门砖,对Hadoop基础知识的掌握程度会在一定程度决定在大数据技术的道路上能走多远,说来惭愧,本人其实是学前端的,并不会深入学习大数据技术,但是在这个时间节点,无论是走什么技术路线的程序员都应该对大数据技术有一定的了解,这不仅是浪潮的要求,更对我们百益而无一害。道阻且长,共勉
小项目见下一篇博客~~~
最后
以上就是忧郁老师最近收集整理的关于超详细的Hadoop环境搭建(Ubuntu18.04.2)的全部内容,更多相关超详细内容请搜索靠谱客的其他文章。








发表评论 取消回复