1.输入start-dfs.sh时出现ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
解决方法(可能):修改/etc/hadoop/hadoop-env.sh
参考教程:ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation._yaoshengting的博客-CSDN博客_hdfs_namenode_user
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root //yarn的也写上,后续配置yarn的时候出错就加上这两句2.输入start-dfs.sh时出现permisssion denied:可能是因为ssh没有设置免密登录
随便搜一下应该就能找到解决方法,但是我后来修改文件的时候只修改了PermitRootLogin,把它的值改为了yes
参考博主:Ubuntu下搭建第一台hadoop输入start-dfs.sh出现Permission denied (publickey,password)的问题_zhangxiaofan2000的博客-CSDN博客3.使用jps判断hadoop是否成功启动的时候,出现error:程序'jps'已包含在下列软件包内
解决方法:很有可能是环境变量配置错了,可以先试试java -version能够正确输出,然后再看看hadoop version能否正确输出。我就是java的环境变量写完之后又被覆盖了,所以在bashrc中没有java的环境变量。所以在这里重新检查一下。
vim ~/.bashrc //看看环境变量什么情况
source ~/.bashrc //记得保存bashrc中添加的是这些:(会根据安装路径的不同有差异,注意修改)
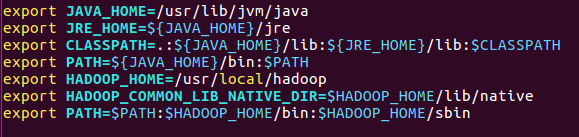
参考博客:启动hadoop输入jps显示:程序 ‘jps‘ 已包含在下列软件包中: * openjdk-7-jdk * openjdk-6-jdk 请尝试:sudo apt-get install ~_陈羽穆的博客-CSDN博客_程序jps已包含在下列软件包中44.输入下列命令出错:-bash:未预期的符号 newline附近有语法错误:不要用<>,改成' '
$ bin/hdfs dfs -mkdir /user/<username> //<username>问用户名,如hadoop
$ bin/hdfs dfs -mkdir /user/hadoop //这样就行了,hadoop可以改成别的名字哈
5.貌似可以正确启动集群,但是使用localhost:9870访问的时候,发现summary里面都是0,再去查datanode发现也没启动。
原因:datanode和namenode启动id不一致的原因。
参考博客:datanode和namenode启动id不一致_再鹤的博客-CSDN博客但是这个博客里面还是写错了,应该修改的是clusterid,不是namespaceid。
6.安装一些python包的时候出现依赖包或者其他错误。
解决方法:换源。我是ubuntu16.04,所以换源的时候对应的时xenial,不同版本对应不同。记得换完源之后update一下,反正我的好使了。
参考博客:Ubuntu18.04下更改apt源为阿里云源_CediOsman的博客-CSDN博客_ubuntu 修改源
然后可以输入python,import一下numpy这几个包,看看行不行。
根据老师的教程安装了一下hadoop和spark,但是没有成功实现mapreduce例子,先总结这么多可能踩的坑。如果实现例子了,再写一下。
我去,这个ubuntu的色彩也太饱和了,我快被亮瞎了。
最后
以上就是淡然钢笔最近收集整理的关于ubuntu16.04安装hadoop和spark问题汇总的全部内容,更多相关ubuntu16内容请搜索靠谱客的其他文章。








发表评论 取消回复