目录
- 高斯过程概述
- 高斯过程举例
- 高斯过程的要素与描述
- 径向基函数演示
- 高斯过程回归
- 高斯过程回归的演示
- 补充内容:关于置信区间
高斯过程概述
高斯过程从字面上看,分为两部分:
- 高斯:高斯分布;
- 过程:随机过程;
当随机变量是一维随机变量的时候,则对应一维高斯分布,概率密度函数 p ( x ) = N ( μ , σ 2 ) p(x)=N(mu,sigma^{2}) p(x)=N(μ,σ2),当随机变量上升至 p p p维后,对应高维高斯分布,概率密度函数 p ( x ) = N ( μ , Σ p × p ) p(x)=N(mu,Sigma_{ptimes p}) p(x)=N(μ,Σp×p)。现在,高斯过程更进一步,是一个定义在连续域上的无限多高斯随机变量组成的随机过程。
比如一个连续域 T T T(假设其为一个时间轴),如果在连续域上任选 n n n个时刻: t 1 , t 2 , . . . , t n ∈ T t_{1},t_{2},...,t_{n}in T t1,t2,...,tn∈T,使得获得的任一个 p p p维向量{ ξ 1 , ξ 2 , . . . , ξ n xi_{1},xi_{2},...,xi_{n} ξ1,ξ2,...,ξn}都满足 p p p维高斯分布,则{ ξ t xi_{t} ξt}为一个高斯过程。
高斯过程举例
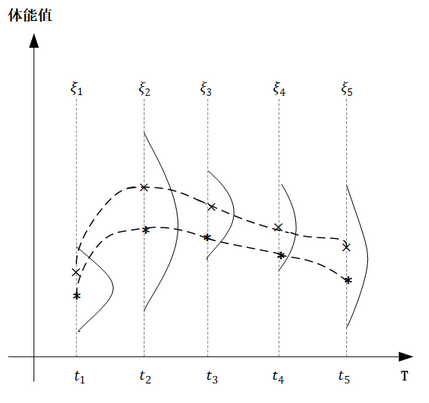
下面通过实际例子直观感受高斯过程,在下图中,横轴 T T T是一个关于时间的连续域,表示人的一生,纵轴表示人的体能,对于同一个人种而言,在任意的时间点上,体能值都服从正态分布,但不同时间点里,分布的均值和方差是不同的。
比如我们选择
t
1
t_{1}
t1到
t
5
t_{5}
t5五个时刻,分别代表同一人种的"童年,少年,青年,中年,老年",
ξ
1
xi_{1}
ξ1到
ξ
5
xi_{5}
ξ5则对应了这五个时刻的体能。对于任意的
t
∈
T
tin T
t∈T,都有
ξ
t
∼
N
(
μ
t
,
σ
t
2
)
xi_{t}sim N(mu_{t},sigma_{t}^{2})
ξt∼N(μt,σt2),也就是对于一个确定的高斯过程而言,选定任意时刻
t
t
t,则
μ
t
mu_{t}
μt与
σ
t
2
sigma_{t}^{2}
σt2也随之确定。在下图中,我们将同一人种的两个人,在关键时刻上采样体能值,再进行平滑连接,比如图中两条虚线,就形成了高斯过程里的两个样本。
高斯过程的要素与描述
对于一个 p p p维高斯分布,决定分布的是两个参数:
- p p p维均值向量 μ p mu_{p} μp,反映随机变量每一维的期望;
- 协方差矩阵 Σ p × p Sigma_{ptimes p} Σp×p,反映高维分布中,每一维自身的方差,以及不同维度间的协方差。
定义在连续域
T
T
T上的高斯过程,需要描述每一个时刻
t
t
t上的均值,所以引入关于时间的函数
m
(
t
)
m(t)
m(t)。对于不同时刻之间协方差的表示,我们引入核函数
k
(
s
,
t
)
k(s,t)
k(s,t),其中
s
s
s和
t
t
t分别表示任意两个时刻或时间点,核函数也称为协方差函数。核函数是一个高斯过程的核心,它决定了高斯过程的性质,核函数具有多种类型,此处介绍最常用的核函数:径向基函数RBF。RBF的定义如下:
k
(
s
,
t
)
=
σ
2
e
x
p
(
−
∣
∣
s
−
t
∣
∣
2
2
l
2
)
k(s,t)=sigma^{2}exp(-frac{||s-t||^{2}}{2l^{2}})
k(s,t)=σ2exp(−2l2∣∣s−t∣∣2)
其中的
σ
sigma
σ和
l
l
l是RBF的超参数,比如设置
σ
=
1
,
l
=
1
sigma=1,l=1
σ=1,l=1,上面式子表达的思想为:
s
s
s和
t
t
t表示高斯过程连续域上的两个不同时间点,
∣
∣
s
−
t
∣
∣
2
||s-t||^{2}
∣∣s−t∣∣2是一个二范式,即
s
s
s和
t
t
t之间的距离(时间间隔的大小)。RBF输出的是一个标量,反映了
s
s
s和
t
t
t两个时间点之间的协方差值。两个点距离越大,则两个分布之间的协方差值越小,即相关性越小。
至此,高斯过程两个要素:均值函数
m
(
t
)
m(t)
m(t)与核函数
k
(
s
,
t
)
k(s,t)
k(s,t)已描述清楚。于是可以确定高斯过程:
ξ
t
∼
G
P
(
m
(
t
)
,
k
(
s
,
t
)
)
xi_{t}sim GP(m(t),k(s,t))
ξt∼GP(m(t),k(s,t))
径向基函数演示
下面是RBF的演示:
import numpy as np
def gaussian_kernel(x1, x2, l=1.0, sigma_f=1.0):
"""RBF"""
m, n = x1.shape[0], x2.shape[0]
dist_matrix = np.zeros((m, n), dtype=float)
for i in range(m):
for j in range(n):
dist_matrix[i][j] = np.sum((x1[i] - x2[j]) ** 2)
return sigma_f ** 2 * np.exp(- 0.5 / l ** 2 * dist_matrix)
train_X = np.array([1, 3, 7, 9]).reshape(-1, 1)#转换为4*1矩阵形式
print(gaussian_kernel(train_X, train_X))
"""
[[1.00000000e+00 1.35335283e-01 1.52299797e-08 1.26641655e-14]
[1.35335283e-01 1.00000000e+00 3.35462628e-04 1.52299797e-08]
[1.52299797e-08 3.35462628e-04 1.00000000e+00 1.35335283e-01]
[1.26641655e-14 1.52299797e-08 1.35335283e-01 1.00000000e+00]]
"""
输入为4个时间点 [ t 1 , t 2 , t 3 , t 4 ] [t_{1},t_{2},t_{3},t_{4}] [t1,t2,t3,t4],输出一个 4 × 4 4times 4 4×4的协方差矩阵,反映任意 t i t_{i} ti和 t j t_{j} tj两个时间点的协方差值,当 i = j i=j i=j时,表示自身方差。
高斯过程回归
我们可以看作是一种 “先验+观测值” 推理出 “后验” 的过程,先通过均值函数 μ ( t ) mu(t) μ(t)和核函数 k ( s , t ) k(s,t) k(s,t)定义一个高斯过程,但是由于没有任何观测值,所以这是一个先验对象。如果获得一组观测值后,我们需要修正高斯过程的均值函数与核函数,得到后验对象。
首先回顾高维高斯分布的条件概率,补充一点,高斯分布具有一个特点:高斯分布的联合概率,边缘概率,条件概率仍然满足高斯分布。
假设有
n
n
n维随机变量服从高斯分布
x
∼
N
(
μ
,
Σ
n
×
n
)
xsim N(mu,Sigma_{ntimes n})
x∼N(μ,Σn×n)。如果把这个
n
n
n维随机变量分成两部分:
p
p
p维的
x
a
x_{a}
xa和
q
q
q维的
x
b
x_{b}
xb,则有以下写法:
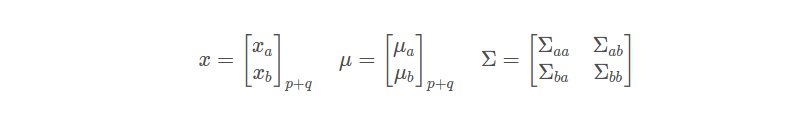
根据高斯分布的性质,我们知道下面的条件分布依然是高维的高斯分布:
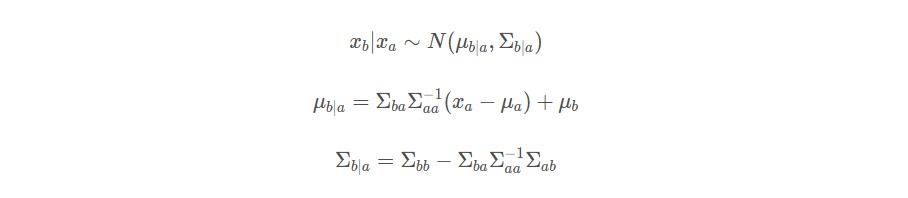
将高斯过程对比高斯分布,可以得到推理:首先设置了高斯过程的先验参数,现在我们获得观测值,就可以对高斯过程的均值函数和核函数进行修正,得到修正后的高斯过程。
我们把均值向量替换到均值函数,协方差矩阵替换到核函数。假设有一组观测值,它们的时刻对应一个向量
X
X
X,那么值对应向量
Y
Y
Y,如果有4对观测值,即为:
{
(
X
[
1
]
,
Y
[
1
]
)
,
(
X
[
2
]
,
Y
[
2
]
)
,
(
X
[
3
]
,
Y
[
3
]
)
,
(
X
[
4
]
,
Y
[
4
]
)
}
left{(X[1],Y[1]),(X[2],Y[2]),(X[3],Y[3]),(X[4],Y[4])right}
{(X[1],Y[1]),(X[2],Y[2]),(X[3],Y[3]),(X[4],Y[4])}
剩下的所有非观测点,在连续域上定义为
X
∗
X^{*}
X∗,值定义为
f
(
X
∗
)
f(X^{*})
f(X∗),则有(
N
N
N表示
G
P
GP
GP):
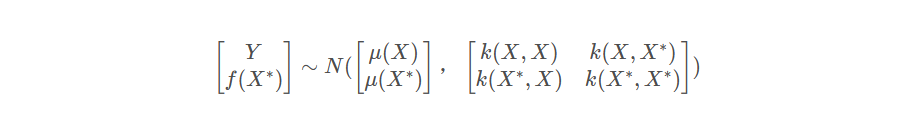
从上式可以看出,如果每个时刻的高斯分布都是一维高斯分布,则高斯过程可以看成是一个无限维的高斯分布。所以从高斯分布类比到高斯过程应该是合理的。
于是,对于
f
(
X
∗
)
∣
Y
f(X^{*})|Y
f(X∗)∣Y 也应该服从高斯分布,当然这个高斯分布是无限维的高斯分布:
f
(
X
∗
)
∣
Y
∼
N
(
μ
∗
,
k
∗
)
f(X^{*})|Ysim N(mu^{*},k^{*})
f(X∗)∣Y∼N(μ∗,k∗)
这里的
μ
∗
,
k
∗
mu^{*},k^{*}
μ∗,k∗为条件分布下的后验高斯过程的均值函数和核函数。类比前面提到的
n
n
n维高斯分布,可以写出:
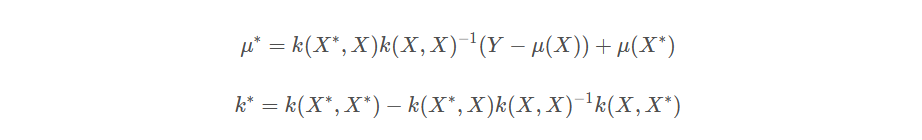
高斯过程回归的演示
首先初始一个先验的高斯过程,我们设置均值函数 μ ( X ) = 0 mu(X)=0 μ(X)=0,径向基函数 k ( X [ i ] , X [ j ] ) = σ 2 e x p ( − ∣ ∣ X [ i ] − X [ j ] ∣ ∣ 2 2 l 2 ) k(X[i],X[j])=sigma^{2}exp(-frac{||X[i]-X[j]||^{2}}{2l^{2}}) k(X[i],X[j])=σ2exp(−2l2∣∣X[i]−X[j]∣∣2)中的超参数 l = 0.5 , σ = 0.2 l=0.5,sigma=0.2 l=0.5,σ=0.2;
在时刻
X
=
[
1
,
3
,
7
,
9
]
X=[1,3,7,9]
X=[1,3,7,9]上采样到观测值,
Y
Y
Y为
X
X
X取正弦的基础上加高斯噪声:
y
=
0.4
s
i
n
(
x
)
+
N
(
0
,
0.05
)
y=0.4sin(x)+N(0,0.05)
y=0.4sin(x)+N(0,0.05)
我们在四个观测点的基础上,计算高斯过程的后验。由于机器只能处理离散数据,所以我们利用一个很大的
n
=
100
n=100
n=100近似表示无限维。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
#高斯核函数
def gaussian_kernel(x1, x2, l=0.5, sigma_f=0.2):
m, n = x1.shape[0], x2.shape[0]
dist_matrix = np.zeros((m, n), dtype=float)
for i in range(m):
for j in range(n):
dist_matrix[i][j] = np.sum((x1[i] - x2[j]) ** 2)
return sigma_f ** 2 * np.exp(- 0.5 / l ** 2 * dist_matrix)
#生成观测值,取sin函数没有别的用意,单纯就是为了计算出Y
def getY(X):
X = np.asarray(X)
Y = np.sin(X)*0.4 + np.random.normal(0, 0.05, size=X.shape)
return Y.tolist()
#根据观察点X,修正生成高斯过程新的均值和协方差
def update(X, X_star):
X = np.asarray(X)
X_star = np.asarray(X_star)
K_YY = gaussian_kernel(X, X) # K(X,X)
K_ff = gaussian_kernel(X_star, X_star) # K(X*, X*)
K_Yf = gaussian_kernel(X, X_star) # K(X, X*)
K_fY = K_Yf.T # K(X*, X) 协方差矩阵是对称的,因此分块互为转置
K_YY_inv = np.linalg.inv(K_YY + 1e-8 * np.eye(len(X))) # (N, N)
mu_star = K_fY.dot(K_YY_inv).dot(Y)
cov_star = K_ff - K_fY.dot(K_YY_inv).dot(K_Yf)
return mu_star, cov_star
f, ax = plt.subplots(2, 1, sharex=True,sharey=True)
#绘制高斯过程的先验
X_pre = np.arange(0, 10, 0.1)
mu_pre = np.array([0]*len(X_pre))
Y_pre = mu_pre
cov_pre = gaussian_kernel(X_pre, X_pre)
uncertainty = 1.96 * np.sqrt(np.diag(cov_pre))#取95%置信区间
"""95%可能性,该区间包含了这个时刻下的高斯分布均值"""
ax[0].fill_between(X_pre, Y_pre + uncertainty,Y_pre - uncertainty, alpha=0.1)
ax[0].plot(X_pre, Y_pre, label="expection")
ax[0].legend()
#绘制基于观测值的高斯过程后验
X = np.array([1, 3, 7, 9]).reshape(-1, 1)#4*1矩阵
Y = getY(X)
X_star = np.arange(0, 10, 0.1).reshape(-1, 1)
mu_star, cov_star = update(X, X_star)
print(mu_star.shape) # (100,1)
print(cov_star.shape) # (100,100) 反映100个时刻各自之间的方差
# 将高维数组展开成一维
Y_star = mu_star.ravel() # (100,)
# 时刻9的值(后验,真实)
print(Y_star[90],Y[3]) # 0.10295047719514798 0.10295050291616215
uncertainty = 1.96 * np.sqrt(np.diag(cov_star))#取95%置信区间
ax[1].fill_between(X_star.ravel(), Y_star + uncertainty, Y_star - uncertainty, alpha=0.1)
ax[1].plot(X_star, Y_star, label="expection")
ax[1].scatter(X, Y, label="observation point", c="red", marker="x")
ax[1].legend()
plt.show()
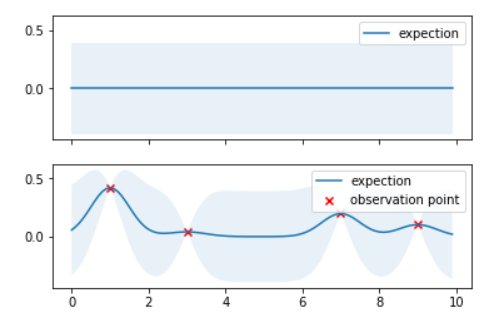
图中半透明区域表示在该时刻的均值附近取95%置信区间的区域,可以看出,由于观测值的引入,连续域上各个时刻的均值发生了变化,并且95%置信区间的空间变窄,证明确定性正在增强。
补充内容:关于置信区间
概念回顾:
- 中心极限定理:
在适当的条件下,大量相互独立随机变量的均值收敛于正态分布。例如我们要计算全中国人的平均身高。如果每次取10000个身高作为样本,对应有一个样本均值。如果再从总体中重复抽取 n n n次10000个样本,就对应有 n n n个样本均值。随着 n n n增大,把所有样本均值记录下来,得到的就是一个接近正太分布的曲线。 - 大数定理:
取样数趋近无穷时,样本的平均值按概率收敛于期望值。比如抛硬币的次数越多,统计结果越接近正反面朝上各一半。
大数定律讲的是样本均值收敛到总体均值(就是期望);
中心极限定理告诉我们,不管总体的分布是什么,总体的任意一个样本均值都围绕在总体均值周围,并呈现正态分布。
- 标准差(standard deviation)与标准误差(standard error):
标准差 = 一次抽样中个体分数间的离散程度,反映了个体分数对样本均值的代表性,用于描述统计。
标准误差 = 多次抽样中样本均值间的离散程度,反映了样本均值对总体均值的代表性,用于推论统计。
点估计:用样本统计量来估计总体参数,因为样本统计量为数轴上某一点值,估计的结果也以一个点的数值表示,所以称为点估计。点估计虽然给出了未知参数的估计值,但是未给出估计值的可靠程度,即估计值偏离未知参数真实值的程度。
区间估计:给定置信水平,根据估计值确定真实值可能出现的区间范围,该区间通常以估计值为中心,该区间被称为为置信区间。
比如:有一个零部件的长度 θ theta θ未知,我们通过点估计推测 θ theta θ为9 cm,这还不足够。如果我们能知道 θ theta θ有95%的概率在(8.7cm,9.2cm)之间,这样描述该长度会更合理。其中(8.7cm,9.2cm)我们就可以理解成置信区间,那么95%就是置信水平。
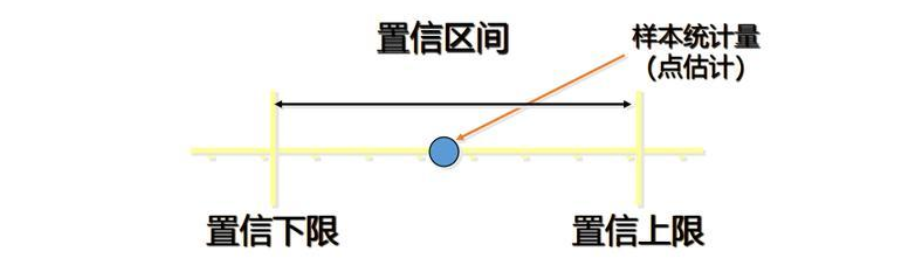
由样本统计量所构造的总体参数的估计区间为置信区间。由于统计学家在某种程度上确定这个区间会包含真正的总体参数,所以取名置信区间。在统计中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。置信区间给出的被测量参数的测量值的可信程度,即前面所要求的"一定概率"。这个概率被称为置信水平。
例如:想了解全国成年男性平均身高,可用抽样的方法,用样本信息估计总体信息。从全国男性中抽取一组样本,将这组样本的平均值作为对总体平均值的一个点估计,当有多组样本,即有多组点估计,但我们不知道哪组样本对总体的估计最正确,所以用区间估计来解决这个问题。假设全国成年男性平均身高在165-175cm之间,这个区间叫置信区间,即:[165,175],这个区间的可信程度由置信水平来表现,置信水平指置信区间包含总体平均值的概率多大,如置信水平为95%。
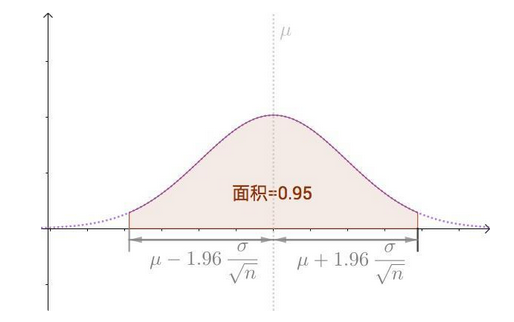
结合中心极限定理,各组样本均值的分布可以用正态分布来近似,总体均值为
μ
mu
μ,总体的标准差为
σ
sigma
σ,总体的样本量为
n
n
n,所以得到95%置信水平的置信区间为:
[
μ
−
1.96
σ
n
,
μ
+
1.96
σ
n
]
[mu-1.96frac{sigma}{sqrt{n}},mu+1.96frac{sigma}{sqrt{n}}]
[μ−1.96nσ,μ+1.96nσ]
在实际应用中,我们不能完全顾及总体,所以还是用样本来估计总体(假设样本服从正态分布),我们即可使用样本均值
μ
mu
μ,样本标准差
σ
sigma
σ,样本的数量
n
n
n计算置信区间,比如:95%可能性包含样本均值的区间。
最后
以上就是舒服烤鸡最近收集整理的关于第十一课.高斯过程高斯过程概述高斯过程举例高斯过程的要素与描述补充内容:关于置信区间的全部内容,更多相关第十一课.高斯过程高斯过程概述高斯过程举例高斯过程内容请搜索靠谱客的其他文章。








发表评论 取消回复