我是靠谱客的博主 迷路御姐,这篇文章主要介绍【OCR识别验证码】--基于tesseract1、环境准备(windows)2、实现目的:3、代码实现5、二值化处理去掉一些杂质 6、评价7、一些问题解决的参考方法,现在分享给大家,希望可以做个参考。
目录
1、环境准备(windows)
2、实现目的:
3、代码实现
5、二值化处理
6、评价
1、环境准备(windows)
- 打开cmd(命令符窗口)输入以下命令: pip install pytesseract
- 安装Tesseract-OCR:下载地址为https://sourceforge.net/projects/tesseract-ocr-alt/files/,可以下载exe程序安装。
等待几秒自动下载(进不去多试几次)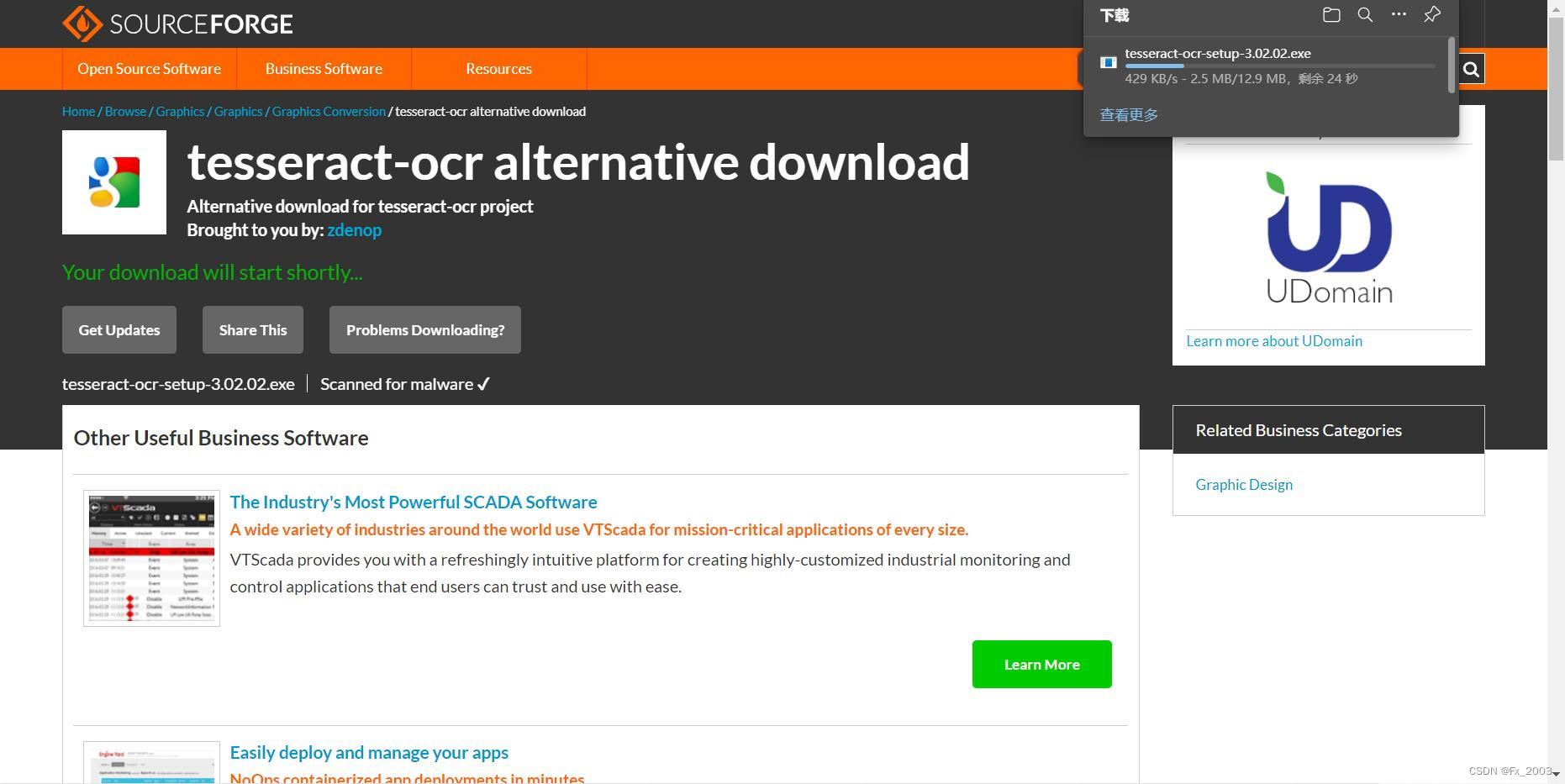
安装(next就行了,不过建议安装在C盘之外的盘)。。有点久
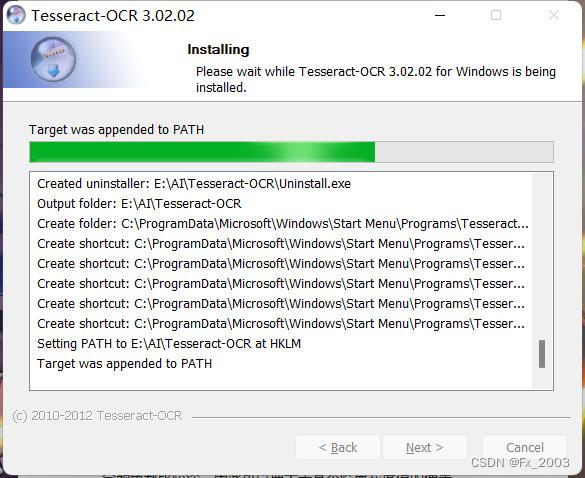
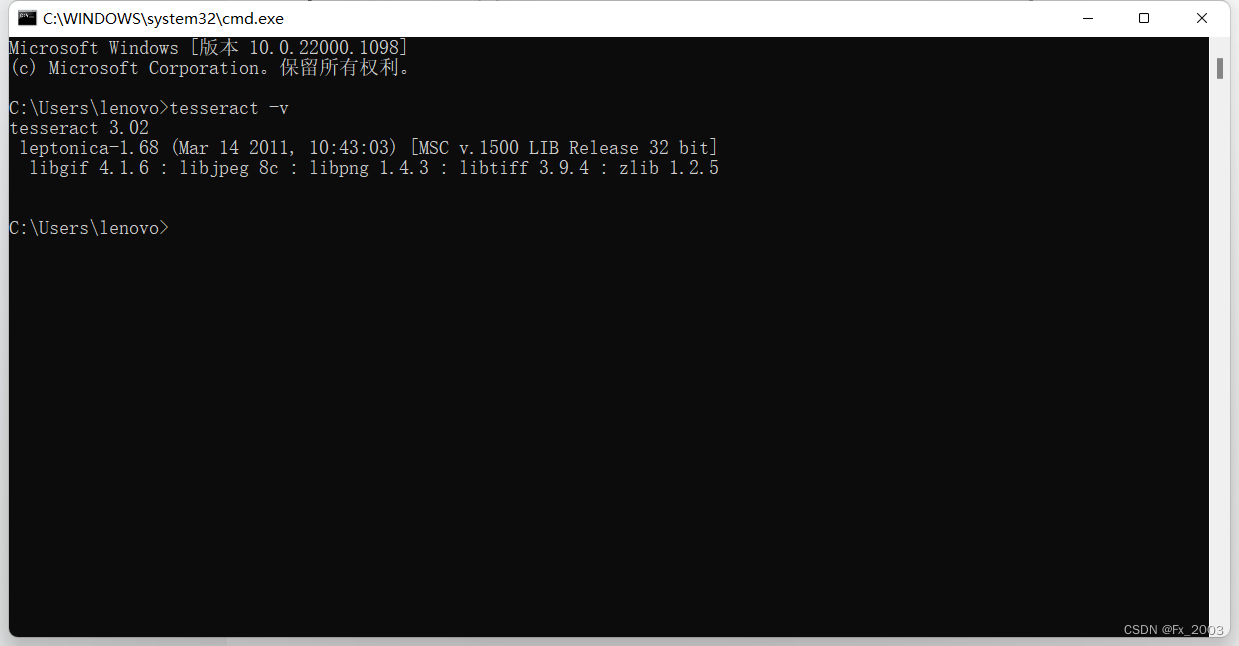
验证:cmd输入 tesseract -v
有下列信息即为成功:
2、实现目的:
识别一张图片上的英文字母
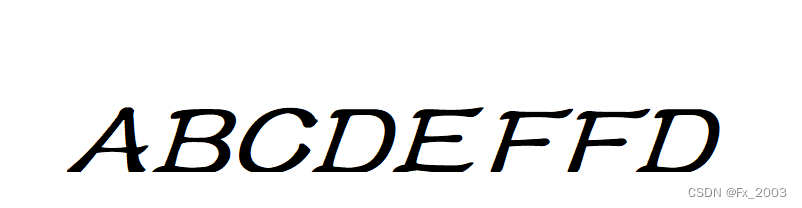
3、代码实现
# -*- coding: utf-8 -*-
"""
@File : OCR.py
@author: FxDr
@Time : 2022/10/30 18:12
"""
from PIL import Image
import pytesseract
th = Image.open("img_out5.png")
print(pytesseract.image_to_string(th))输出如下:

5、二值化处理去掉一些杂质
如下图:

二值化处理。上图文本的部分颜色比较深,
通过把大于某个临界灰度值的像素灰度设为灰度极大值,
把小于这个值的像素灰度设为灰度极小值,从而实现二值化
通过代码:
# -*- coding: utf-8 -*-
"""
@File : OCR处理验证码.py
@author: FxDr
@Time : 2022/10/30 17:17
"""
from PIL import Image
# 灰度处理
im = Image.open("img.png")
g = im.convert('L')
# g.show()
# 二值化处理
threshold = 150
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
out = g.point(table, '1')
out.show()
out.save("img_out.png")
import pytesseract
th = Image.open("img_out.png")
print(pytesseract.image_to_string(th))
会打开一张图片:img_out.png

但是输出的结果为:
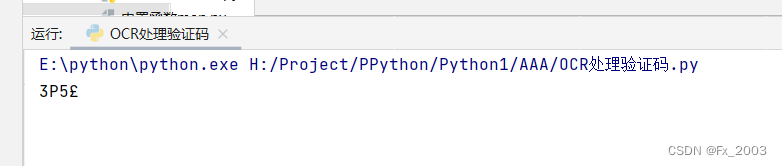
可见:E的识别并不准确
6、评价
我们通过上述示例可以知道,tesseract OCR
可以帮我们识别一些图片上的英文字母
而通过二值化我们可以去掉一些图片上的相比于文本较浅的的背景
但是也有不足:
识别并不是那么准确。
但是对那些简单的验证码来说,还是比较不错的
7、一些问题解决的参考方法
tesseract 安装及使用_showgea的博客-CSDN博客_tesseract
最后
以上就是迷路御姐最近收集整理的关于【OCR识别验证码】--基于tesseract1、环境准备(windows)2、实现目的:3、代码实现5、二值化处理去掉一些杂质 6、评价7、一些问题解决的参考方法的全部内容,更多相关【OCR识别验证码】--基于tesseract1、环境准备(windows)2、实现目内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复