1.安装tesseract
以windows系统为例,可以通过以下链接进行安装:
https://github.com/UB-Mannheim/tesseract/wiki
根据自己电脑选择下载32或64bit的。
安装过程较简单,
安装将其好后放设置为系统环境变量。(放在path中)
除此之外,要把训练集的数据也设为环境变量。即
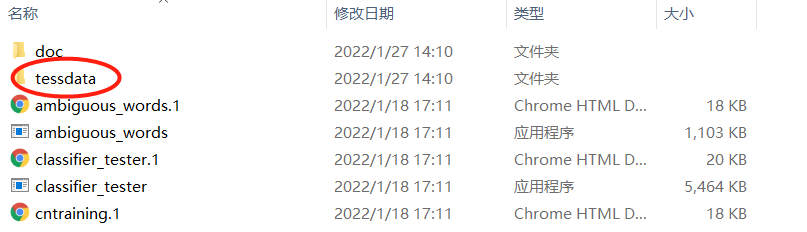
如图,上边这个文件夹。(单独新建,不放path中)
2.直接在终端使用
安装并设置好后,在命令行中可以到查看版本:
tesseract --version
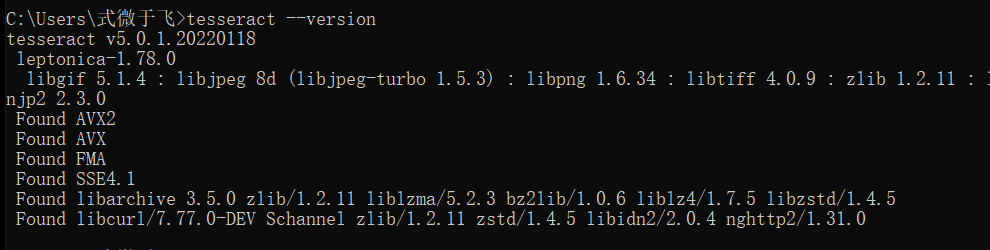
然后就可以正常使用了。
以下图上的文字为例

将其截图保存下来,文件名命名为 pic.png,放在一定目录下
然后在命令行中输入,tesseract 并在后边加上两个路径,第一个路径是目标图片的路径,第二个路径是输出结果的路径(如果没有txt后缀也默认为txt文件输出)。
以此行命令为例:
tesseract D:ABCpic.png D:ABCresult.txt
如图则在目标路径下生成了一个txt文件,图片上的文字得到识别。
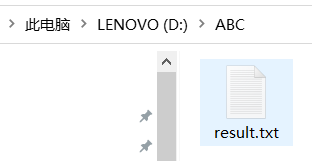
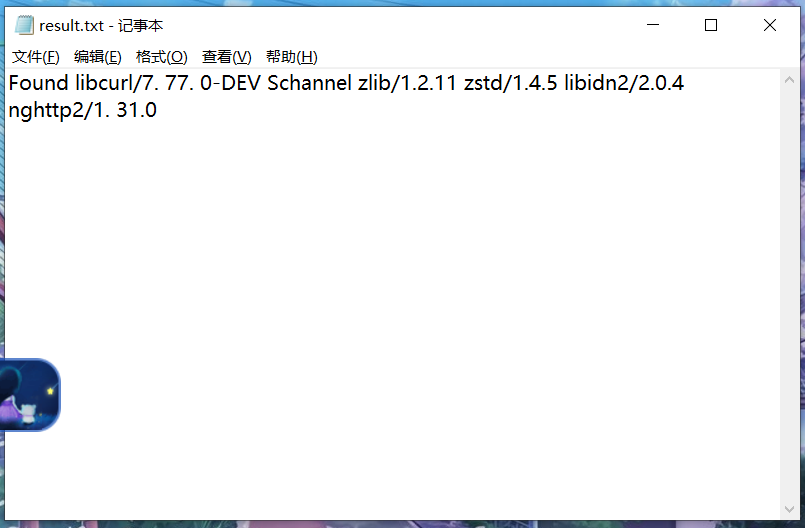
该识别有一定的准确率,不能保证100%准确。(但还是比较高的)
3.在py中使用tesseract
安装两个库:
pip install pytesseract
pip install pillow
以该图片为例,文件名为yzm.png
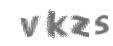
import pytesseract
from PIL import Image
image = Image.open('yzm.png')
# 如果没有设置上边提到的两个环境变量,则需要以下代码来分别指定tesseract.exe和训练集的路径
# tesseract.exe的路径
# pytesseract.pytesseract.tesseract_cmd = 'tesseract.exe的路径'
# 指定训练集的路径
# tessdata_dir_config = r'--tessdata-dir "D:Tesseract-OCRtessdata"'
result = pytesseract.image_to_string(image)
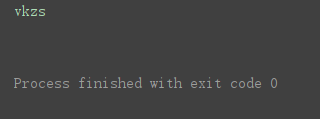
print(result)
输出结果如下,成功识别了图片上的文字。
如果想要识别中文,则还需要去安装中文的训练集数据,在pytesseract.image_to_string()方法中指定参数lang:pytesseract.image_to_string(image, lang=‘chi’)。(这种方法对中文识别的效果并不非常好)
最后
以上就是诚心小白菜最近收集整理的关于tesseract库的安装与使用及在python中使用1.安装tesseract2.直接在终端使用3.在py中使用tesseract的全部内容,更多相关tesseract库内容请搜索靠谱客的其他文章。








发表评论 取消回复