2017年1月4日文章Recurrent Layers——介绍
我不把他们叫做CNN或RNN,而叫convolutional layers,recurrent layers,feedforward layers。
所有layers的本质都是feedforward。
- feedforward layer是指在一个vector内部的不同维度之间进行一次信息交互
- convolutional layer是以逐次扫描的方式在一个vector的局部进行多次信息交互。
- recurrent layer就是在hidden state上增加了loop,看似复杂,其实就是从时间维度上进行了展开。是在不同时刻的多个vectors之间进行信息交互。
深层学习的 “深” 字是由于将 分类/回归 和 特征提取 两者结合在一起来训练了。
Recurrent layer和convolutional layer都可以看成是特征提取层。
- 语音识别用Recurrent layer去学习“如何”去听,再用学好的听取方式去处理声音再送入分类器中。
人脑举例子,我们大脑已有从中文学来的对语音的“特征提取层”和“分类层”。学习外语的时候,只是新训练了一个“分类层”,继续用中文的语音的“特征提取层”,这是外语听力的不好的原因之一。 - 画面识别convolutional layer学习“如何”去观察,再用学好的观察方式去处理画面再送入分类器中。
人脑举例子,我们在观察图片的时候并不是一眼把所有画面都送入大脑进行识别的,而是跟convolutional layer的处理方式一样,逐一扫描局部后再合并。不同的扫描方式,所观察出的内容也不同。
简单理解神经网络应该分为两部分:
- 网络结构:神经网络是怎么计算预测的,以及神经网络为什么好用。
- 网络训练:神经网络是怎么训练的,以及如何克服在训练时所遇到的如过拟合,梯度消失等问题。
进一步理解围绕“深层”二字来神经网络的的话应该在网络结构中细分两类:
网络结构:
- 特征结构:之所以要深层是因为一部分的层在完成“学习如何提取特征”的任务。比如画面处理的convolutional layers ,时间序列处理的Recurrent layers。甚至feedforward layers也能完成此任务。
- 分类/递归结构:如果仅需完成分类器的任务的话,一个hidden feedforward足以。其他的机器学习算法如SVM,GP甚至做的要比神经网络要好。
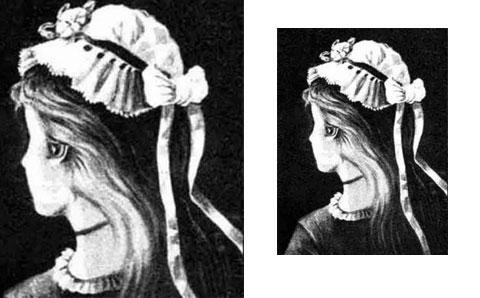 如果这是一个训练样本。
如果这是一个训练样本。
- 当你给的标签是少女的时候,convolutional layers会以此学习“如何观察”成少女
- 当你给的标签是老妇的时候,convolutional layers会以此学习“如何观察”成老妇
- 之所以深层,是因为一定数量的层数在学习“如何观察”。再学习完如何观察后再传递给“分类层”中去。而分类层并不需要“深”。
- 网络结构中最重要的是特征结构层,画面处理的convolutional layers ,时间序列处理的Recurrent layers最好理解为特征结构层。
补充: 这种 特征层 + Mapping层 的观点可以从Yoshua Bengio大神在 Deep Learning:Theoretical Motivations 的开头的讲解中找的到
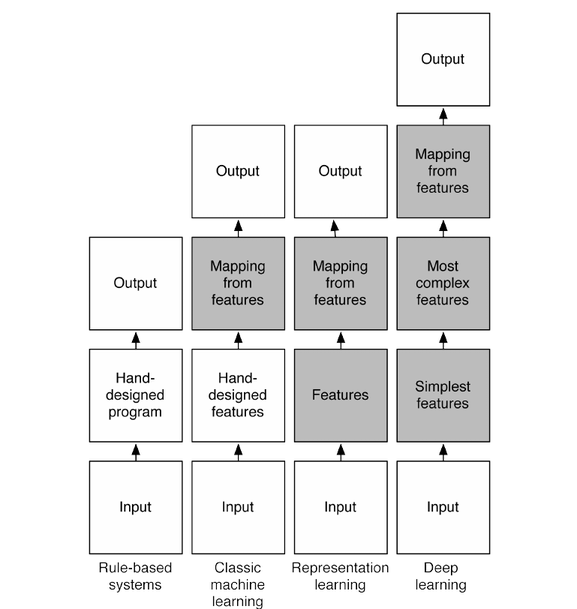 这张图简述了机器学习的发展,从最初的人工定义特征再放入分类器的方法一直到如今的deep learning。
这张图简述了机器学习的发展,从最初的人工定义特征再放入分类器的方法一直到如今的deep learning。
Yoshua Bengio所提到的
automatic feature discovery + high level 就是 特征层,
mapping from features to output 就是 分类/回归层 .
可以看出从representation learning 开始就已经融合二者在一个网络之中了,深层学习更是进了一步.同时也能清晰的观察到,deep learning之所以 "深" 的原因.
当前人们的研究方向
深层神经网络叫做deep neural network (DNN),是指加深后的神经网络。深层学习叫做deep learning (DL),泛指任何加深后的机器学习方法。DNN是DL的一种。
当人们意识到更deep的机器学习方法更加有效时,除了神经网络,人们也在不断的尝试应用其他的深层学习方法。比如加深SVM,加深Gaussian Processes (GP) 就是比较有前景的研究。 在单层的时候SVM和GP都比NN要更加优秀,GP在回归task上额外优秀,但加深GP存在训练上的困难。这也是人们当前在解决的课题之一。
-------------------------------------------------------------------------------------------------------------------------------
新文章
深层学习为何要“Deep”(上)
深层学习为何要“Deep”(下)
链接:https://www.zhihu.com/question/34681168/answer/133563629
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接: 知乎专栏
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先, 要看RNN和对于图像等静态类变量处理立下神功的卷积网络CNN的结构区别来看, “循环”两个字,已经点出了RNN的核心特征, 即系统的输出会保留在网络里, 和系统下一刻的输入一起共同决定下一刻的输出。这就把动力学的本质体现了出来, 循环正对应动力学系统的反馈概念,可以刻画复杂的历史依赖。另一个角度看也符合著名的图灵机原理。 即此刻的状态包含上一刻的历史,又是下一刻变化的依据。 这其实包含了可编程神经网络的核心概念,即, 当你有一个未知的过程,但你可以测量到输入和输出, 你假设当这个过程通过RNN的时候,它是可以自己学会这样的输入输出规律的, 而且因此具有预测能力。 在这点上说, RNN是图灵完备的。
<img src="https://www.shuijiaxian.com/files_image/2023061223/202306122332518399169.png" data-rawwidth="827" data-rawheight="262" class="origin_image zh-lightbox-thumb" width="827" data-original="https://pic2.zhimg.com/v2-6522f0e0cd9740f45e1ee46591898081_r.png">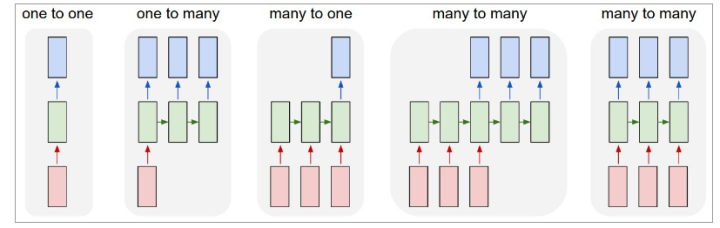
图: 图1即CNN的架构, 图2到5是RNN的几种基本玩法。图2是把单一输入转化为序列输出,例如把图像转化成一行文字。 图三是把序列输入转化为单个输出, 比如情感测试,测量一段话正面或负面的情绪。 图四是把序列转化为序列, 最典型的是机器翻译,注意输入和输出的“时差”。 图5是无时差的序列到序列转化, 比如给一个录像中的每一帧贴标签。 图片来源 The unreasonableeffective RNN。
我们用一段小巧的python代码让你重新理解下上述的原理:
classRNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
这里的h就是hidden variable 隐变量,即整个网络每个神经元的状态,x是输入, y是输出, 注意着三者都是高维向量。隐变量h,就是通常说的神经网络本体,也正是循环得以实现的基础, 因为它如同一个可以储存无穷历史信息(理论上)的水库,一方面会通过输入矩阵W_xh吸收输入序列x的当下值,一方面通过网络连接W_hh进行内部神经元间的相互作用(网络效应,信息传递),因为其网络的状态和输入的整个过去历史有关, 最终的输出又是两部分加在一起共同通过非线性函数tanh。 整个过程就是一个循环神经网络“循环”的过程。 W_hh理论上可以可以刻画输入的整个历史对于最终输出的任何反馈形式,从而刻画序列内部,或序列之间的时间关联, 这是RNN强大的关键。
<img src="https://www.shuijiaxian.com/files_image/2023061223/202306122332512887139.png" data-rawwidth="920" data-rawheight="757" class="origin_image zh-lightbox-thumb" width="920" data-original="https://pic2.zhimg.com/v2-f1798a007e657d4a1e65afdd9bc8a241_r.png">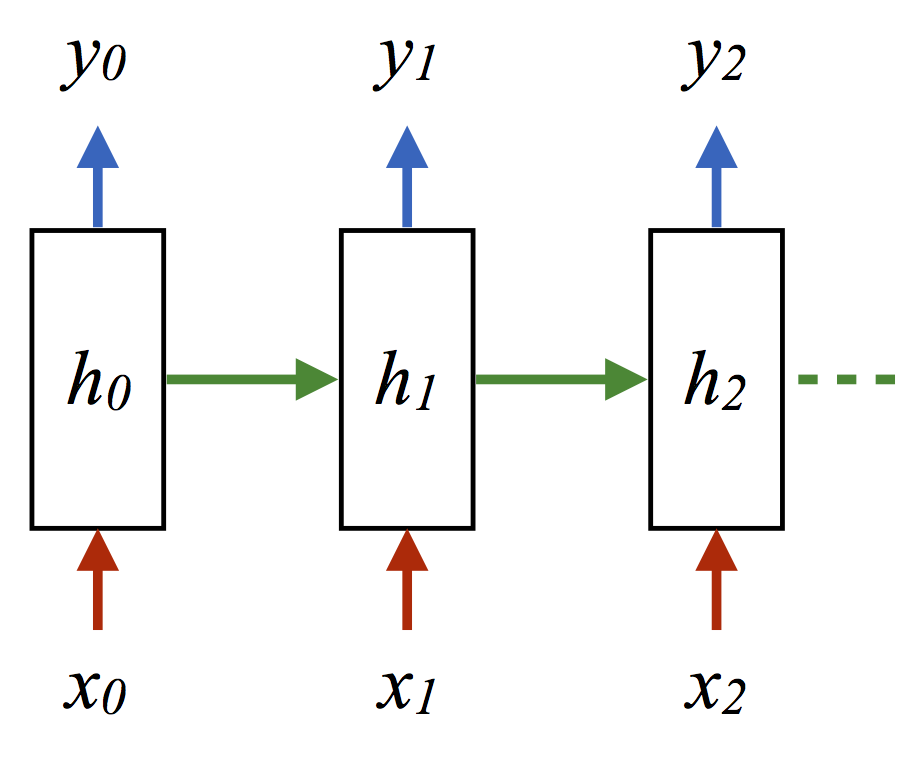
那么CNN似乎也有类似的功能? 那么CNN是不是也可以当做RNN来用呢? 答案是否定的,RNN的重要特性是可以处理不定长的输入,得到一定的输出。当你的输入可长可短, 比如训练翻译模型的时候, 你的句子长度都不固定,你是无法像一个训练固定像素的图像那样用CNN搞定的。而利用RNN的循环特性可以轻松搞定。
<img src="https://www.shuijiaxian.com/files_image/2023061223/202306122332516837455.png" data-rawwidth="1045" data-rawheight="273" class="origin_image zh-lightbox-thumb" width="1045" data-original="https://pic1.zhimg.com/v2-225be444ffc0da0bd0cbfb79b6b0ad80_r.png">图, CNN(左)和RNN(右)的结构区别, 注意右图中输出和隐变量网络间的双向箭头不一定存在,往往只有隐变量到输出的箭头。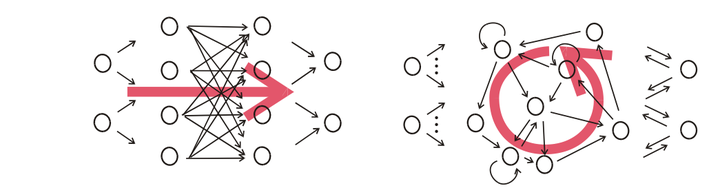 图, CNN(左)和RNN(右)的结构区别, 注意右图中输出和隐变量网络间的双向箭头不一定存在,往往只有隐变量到输出的箭头。
图, CNN(左)和RNN(右)的结构区别, 注意右图中输出和隐变量网络间的双向箭头不一定存在,往往只有隐变量到输出的箭头。
我不把他们叫做CNN或RNN,而叫convolutional layers,recurrent layers,feedforward layers。
所有layers的本质都是feedforward。
- feedforward layer是指在一个vector内部的不同维度之间进行一次信息交互
- convolutional layer是以逐次扫描的方式在一个vector的局部进行多次信息交互。
- recurrent layer就是在hidden state上增加了loop,看似复杂,其实就是从时间维度上进行了展开。是在不同时刻的多个vectors之间进行信息交互。
深层学习的 “深” 字是由于将 分类/回归 和 特征提取 两者结合在一起来训练了。
Recurrent layer和convolutional layer都可以看成是特征提取层。
- 语音识别用Recurrent layer去学习“如何”去听,再用学好的听取方式去处理声音再送入分类器中。
人脑举例子,我们大脑已有从中文学来的对语音的“特征提取层”和“分类层”。学习外语的时候,只是新训练了一个“分类层”,继续用中文的语音的“特征提取层”,这是外语听力的不好的原因之一。 - 画面识别convolutional layer学习“如何”去观察,再用学好的观察方式去处理画面再送入分类器中。
人脑举例子,我们在观察图片的时候并不是一眼把所有画面都送入大脑进行识别的,而是跟convolutional layer的处理方式一样,逐一扫描局部后再合并。不同的扫描方式,所观察出的内容也不同。
简单理解神经网络应该分为两部分:
- 网络结构:神经网络是怎么计算预测的,以及神经网络为什么好用。
- 网络训练:神经网络是怎么训练的,以及如何克服在训练时所遇到的如过拟合,梯度消失等问题。
进一步理解围绕“深层”二字来神经网络的的话应该在网络结构中细分两类:
网络结构:
- 特征结构:之所以要深层是因为一部分的层在完成“学习如何提取特征”的任务。比如画面处理的convolutional layers ,时间序列处理的Recurrent layers。甚至feedforward layers也能完成此任务。
- 分类/递归结构:如果仅需完成分类器的任务的话,一个hidden feedforward足以。其他的机器学习算法如SVM,GP甚至做的要比神经网络要好。
如果这是一个训练样本。
- 当你给的标签是少女的时候,convolutional layers会以此学习“如何观察”成少女
- 当你给的标签是老妇的时候,convolutional layers会以此学习“如何观察”成老妇
- 之所以深层,是因为一定数量的层数在学习“如何观察”。再学习完如何观察后再传递给“分类层”中去。而分类层并不需要“深”。
- 网络结构中最重要的是特征结构层,画面处理的convolutional layers ,时间序列处理的Recurrent layers最好理解为特征结构层。
补充: 这种 特征层 + Mapping层 的观点可以从Yoshua Bengio大神在 Deep Learning:Theoretical Motivations 的开头的讲解中找的到
这张图简述了机器学习的发展,从最初的人工定义特征再放入分类器的方法一直到如今的deep learning。
Yoshua Bengio所提到的
automatic feature discovery + high level 就是 特征层,
mapping from features to output 就是 分类/回归层 .
可以看出从representation learning 开始就已经融合二者在一个网络之中了,深层学习更是进了一步.同时也能清晰的观察到,deep learning之所以 "深" 的原因.
当前人们的研究方向
深层神经网络叫做deep neural network (DNN),是指加深后的神经网络。深层学习叫做deep learning (DL),泛指任何加深后的机器学习方法。DNN是DL的一种。
当人们意识到更deep的机器学习方法更加有效时,除了神经网络,人们也在不断的尝试应用其他的深层学习方法。比如加深SVM,加深Gaussian Processes (GP) 就是比较有前景的研究。 在单层的时候SVM和GP都比NN要更加优秀,GP在回归task上额外优秀,但加深GP存在训练上的困难。这也是人们当前在解决的课题之一。
-------------------------------------------------------------------------------------------------------------------------------
新文章
深层学习为何要“Deep”(上)
深层学习为何要“Deep”(下)
最后
以上就是飘逸微笑最近收集整理的关于RNN解释摘自知乎的全部内容,更多相关RNN解释摘自知乎内容请搜索靠谱客的其他文章。








发表评论 取消回复