《 Dianchen666’s Deep Learning 学习笔记系列 ---- 小白角度看深度学习》
有导航,不迷路。
(1). DeepLearning之LSTM模型输入参数:time_step, input_size, batch_size的理解
(2). DeepLearning之LSTM模型输入数据:白话降维解说
本文摘要:
-
对于LSTM的输入参数的理解的应用。
-
LSTM模型真正的输入数据是什么样的?
-
通过LSTM的输入数据实例的讲解,更好的理解循环神经网络的输入数据。
1. LSTM的基本介绍
- 上次讲到了LSTM模型的输入参数的理解,这一篇讲讲我对LSTM以及循环网络模型的输入数据的理解。
- LSTM是循环神经网络的一个变种,加入了多个门来控制每个神经细胞的状态
- 细胞的状态对于整个模型是非常重要的,训练模型主要是更新每个细胞的输入参数,转态参数,输入的参数,让每个细胞处于一个稳定的状态
- 输入的数据的一般是time_step, input_size, batch_size,这三个输入参数的定义我已经在上一篇博文中谈了谈我的理解
- 受一位博友启发,但是我发现好像没有博文对输入数据到底是什么样的,讲的非常的清晰透彻、清楚。
- 本文尝试从非常白话的角度,来谈谈我对输入数据模样的理解。
- 如有不对,还请多批评指正。
2. 基础参数理解
- 输入数据主要是三个参数,time_step, input_size, batch_size
- 借某位博友的启发,引用一下它的话:“batch_size是指有多少组序列数据,而time_step是指每组序列数据中有多少个时刻”
- input_size 最好理解,就是输入的数据有几个自变量,就是有几个X
- iteration与batchsize是有乘法关系的,3000条数据,100iteration,那么batchsize就是30。也就是Total sample = iteration(n)*batchsize
- batch_size就是我们常说的批处理的数据量
- epoch=10就是进行10*100个iteration来对模型进行训练
3. 各参数确定的次序
- 首先应该确定的是由几个自变量,就是有几个X,由几个变量来预测另外一个y
- 第2个应该确定的是time_step,就是确定你进行训练其中一次的有多少个时刻,这个time_step就应该是多少,换句话说就是你预测的这个y和之前的多少个时刻有关系,这样来确定。
- 第3个就是batch_size, 原理上将batch_size可能会影响你的训练速度,因为它的定义是批大小,是一次训练所选取的样本数,为了在内存效率与内存容量之间寻找平衡,白话就是提高你的训练效率。
- batch_size和time_step本身没有关系,但是time_step的长短和input_size的多少会影响每一个iteration训练的速度。
3. 示意图
1.还是用一个excel的数据表来进行举例
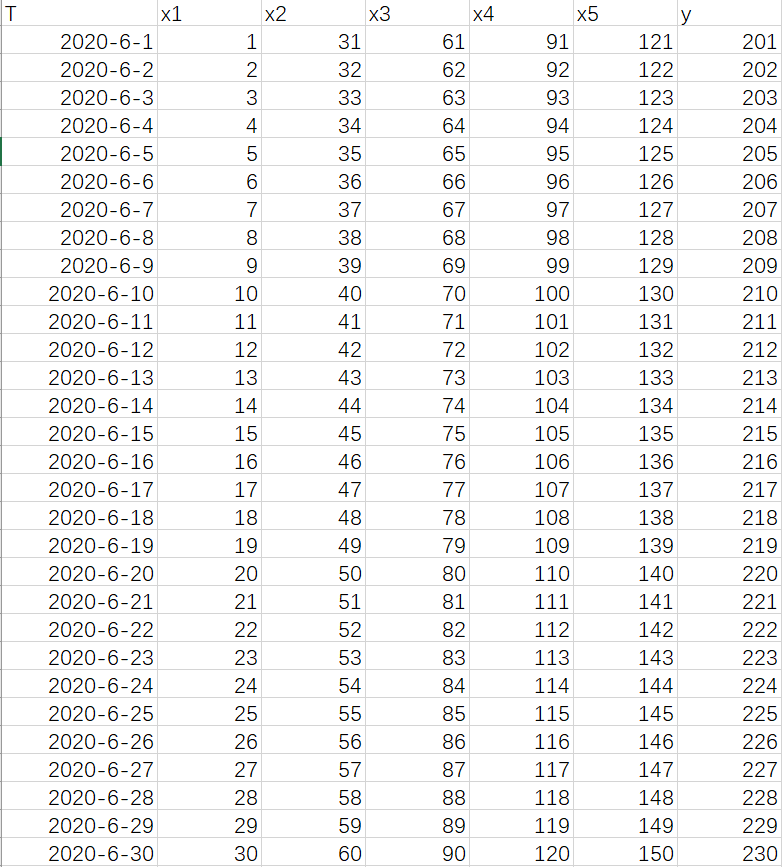
2.时间是从2020年6月1日-6月30日,x1,x2,x3,x4,x5说明是有5个自变量,也就是Inputsize=5,y为要预测的值。
3.此时确定timestep的值,就是你预测的这个Y值是之前的几个时刻有关系,比如上图要预测的y值使用前5天的数据来进行预测,那么time_step=5,此时将上述的数据按照time_step的大小进行重构。
4.通过time_step参数对数据进行重构后,会产生新的数据组,组数=total_sample - time_step + 1,如下图:26组=total(30) - time_step(5) +1,每组数据都有5个时刻t
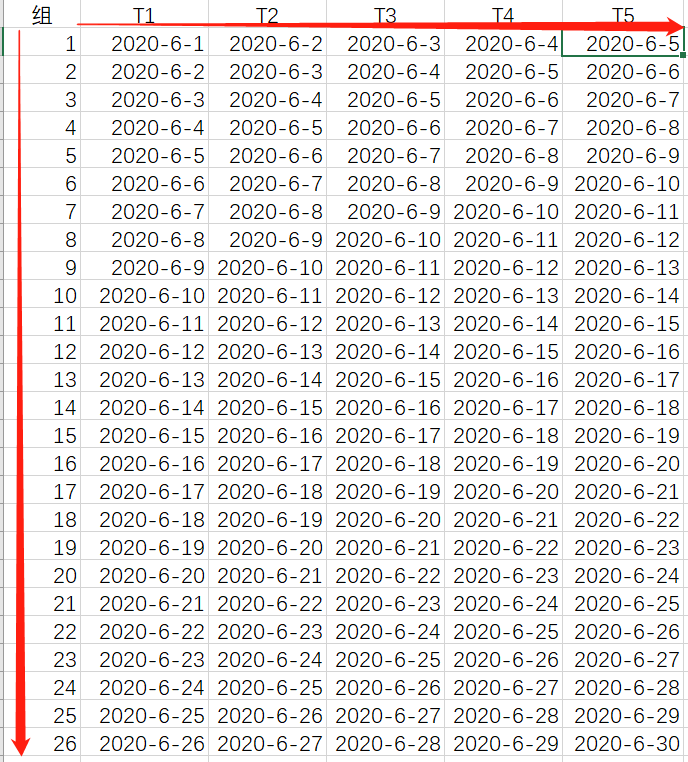
4.其中包含5个时刻数据的这一组数据称为输入数据的一个batch,而batch_size就是每一次feed数据有多少组这样的数据。batch(26) = total(30) - time_step(5) +1
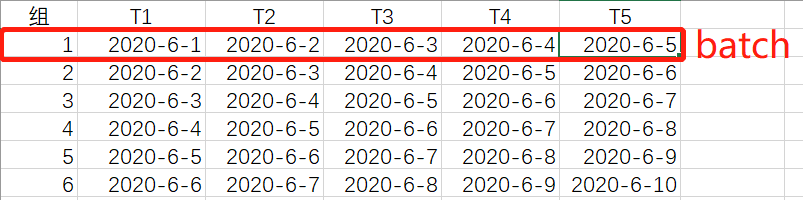
5.再把每一个batch的数据剖开,看看每一个batch的数据是什么样的。
6.下图为一个粗糙的示意图。讲述了在一个Batch中数据是如何进行运转的。
7.在batch1 中,T1时刻的数据分为X变量与Y变量,在T1时刻X与Y数据被同时输入到LSTM中,通过各种门的计算,输出了一个细胞状态Ct1与Ht1,这个两个变量会作为输入变量到下一个时刻的计算当中。
8.到T2时,T1时刻输出的Ct1与Ht1与T2时刻的X变量(x1x2x3x4x5)输入到LSTM模型中,通过各种门的计算,最后得到Ct2与Ht2,在输入到下一时刻,直到整个batch结束。
- 一个batch中会循环计算time_step次。
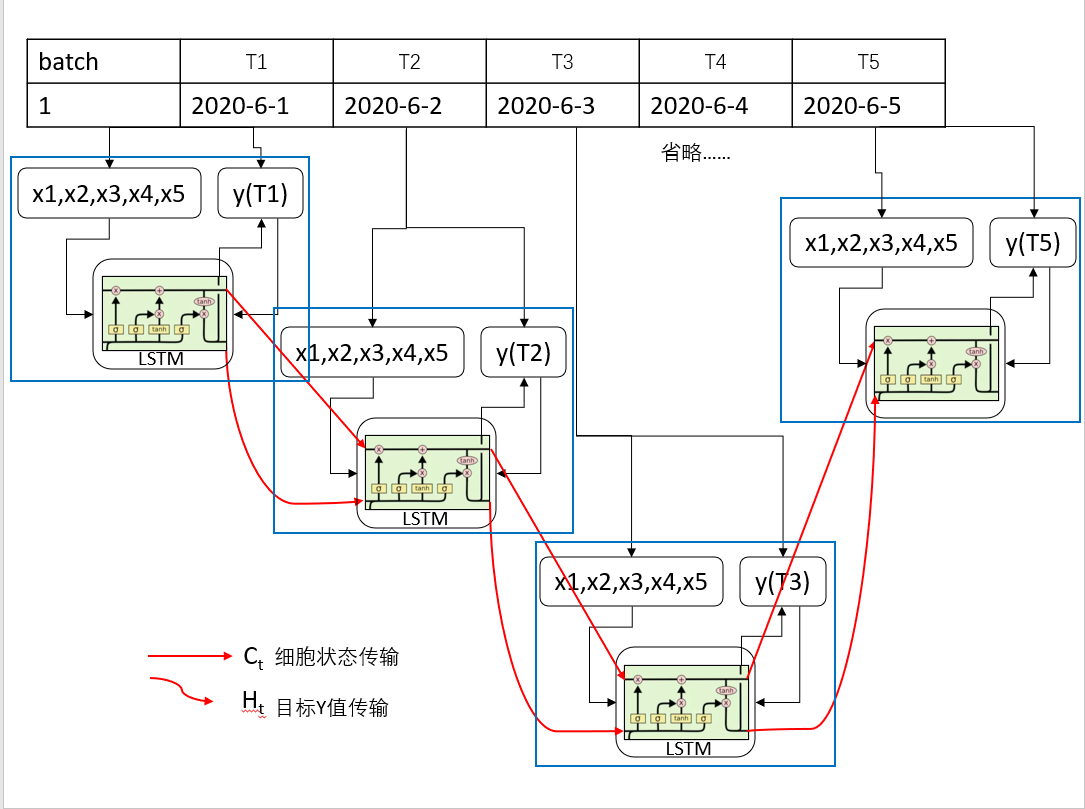
10.上图中,红色直线代表是的细胞状态变量的转移
红色曲线代表的是目标值也就是Ht变量的转移。
11.在执行一个batch结束后,再执行下一个batch,batchsize=30就是1个iteration中执行了30个这样的batch,在一次feed数据中。
12.重构后的batch的个数,自己定义size的大小。上图中的所有数据重构后,变成了26个batch,你可以将batchsize设置为5,设置为10,设置为20。
13.无论batchsize设置为多少,每一组数据都是按照顺序进入到模型中进行训练。
4. 总结
- 那么batchsize主要影响模型的什么?主要是影响模型的泛化性能,就是模型在训练之后对于test数据预测的准确性。
- 一般来说:越大大的batchsize,会减少模型训练所需要的时间,提高模型的稳定性
- 在合适的范围内,增大batchsize,有助于收敛的稳定性,但是再随着batchsize的增加,模型的性能会下降(泛化性能)
- 总结来说:batchsize在变得很大(超过一个临界点)时,会降低模型的泛化能力。
下一篇说说学习率与batchsiz对模型性能的影响。
————————————————
参考链接,尊重原创,支持原创!
- 作者:ch206265, 文章:LSTM中的batch到底是什么, https://blog.csdn.net/ch206265/article/details/107088040
- 作者:言有三,学习率和batchsize如何影响模型的性能?
最后
以上就是羞涩翅膀最近收集整理的关于DeepLearning之LSTM模型输入数据:白话降维解说1. LSTM的基本介绍2. 基础参数理解3. 各参数确定的次序3. 示意图4. 总结的全部内容,更多相关DeepLearning之LSTM模型输入数据:白话降维解说1.内容请搜索靠谱客的其他文章。








发表评论 取消回复