LSTM:三个门 - 遗忘门、输入门、输出门
门可以理解为mask,用来过滤筛选信息。
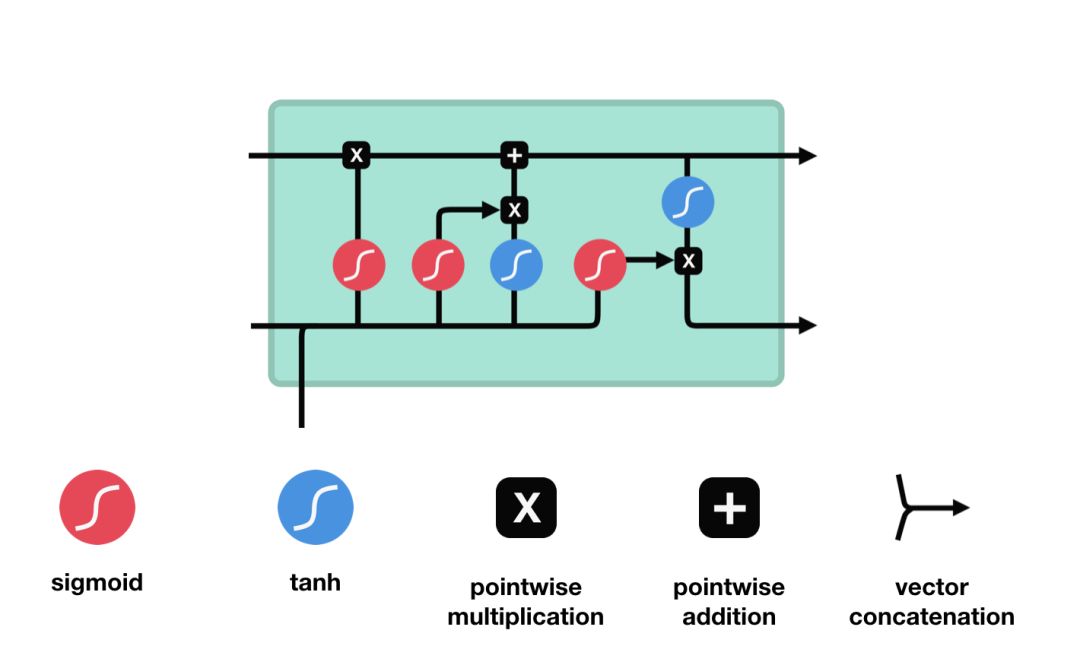
单次输入、细胞状态、单次输出,均是列向量。即总的输入是一连串的列向量。
解释:除去最右边的蓝色tanh,其他每一个激活函数图标,都代表着 f(Wx+b) 即激活一个线性运算。三个门共四个要激活的线性运算,代表着四对可训练的矩阵W和截距b。这四对参数才是LSTM训练过程中真正在训练的东西。由于细胞状态c与隐状态h的维数相同(记做k),与输入的维数i无关,故四个矩阵W均是k*(k+i)维。
注意1:k与i均可在搭建时设定,即同CNN一样,LSTM也有改变特征维数的功能。
注意2:tanh输出-1到1,sigmoid输出0到1,所以在不同时候使用,起到不同效果。
参数量:4k(k+i)+4k (即4个W和4个b)
问题思考:细胞状态c和隐状态h貌似有部分功能重复的嫌疑?
问题解决:新出的GRU合并了隐状态和细胞状态。与LSTM效果差不多,但参数更少,更不容易过拟合。
GRU:两个门 - 更新门、重置门
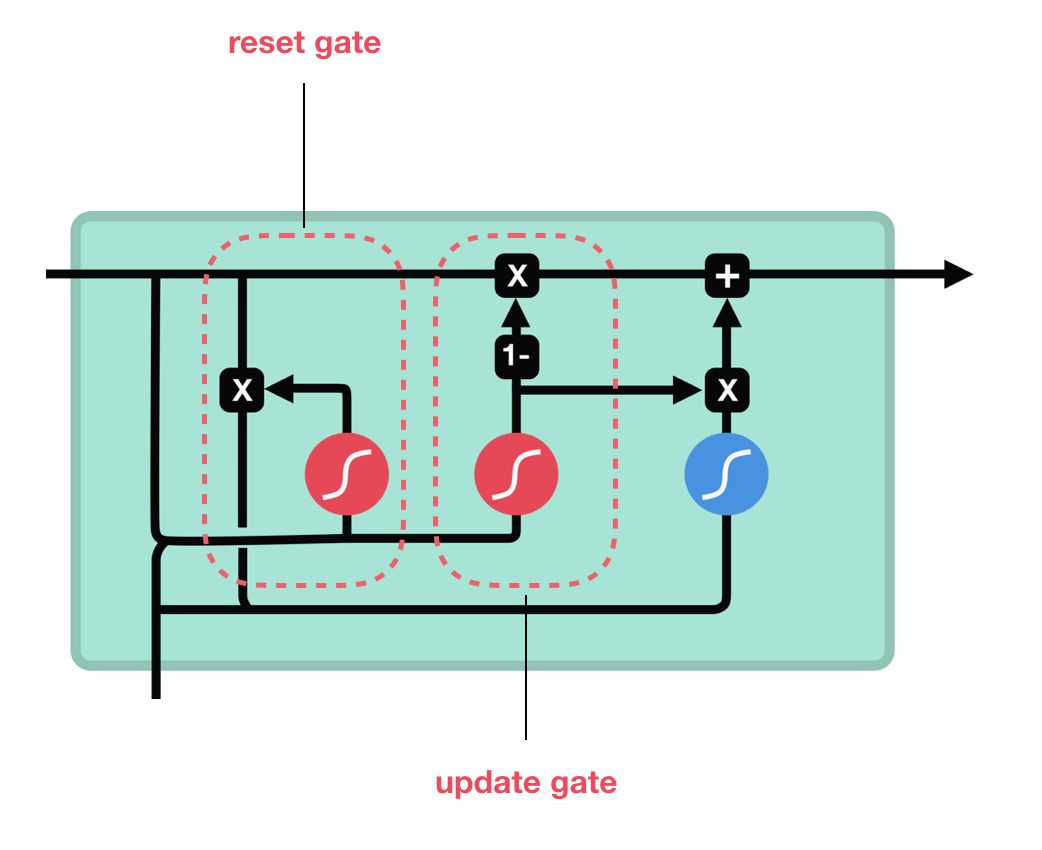
GRU将LSTM中的细胞状态和隐状态统一为隐状态h。
解释:三个激活函数都代表着 f(Wx+b) 即激活一个线性运算。三个要激活的线性运算,代表着三对可训练的矩阵W和截距b。隐状态h的维数(记做k),与输入的维数i无关,故三个矩阵W均是k*(k+i)维。
注意:k与i均可在搭建时设定,即GRU同样有改变特征维数的功能。
参数量:3k(k+i)+3k (即3个W和4个b,比LSTM少了四分之一的参数)
最后回过头来看一眼基本的RNN。
RNN:没有门结构
只有一对参数W和b,没有流经始终的细胞(隐)状态,受到梯度消失问题的影响,模型无法记忆远期知识。
参数量:k(k+i)+k (即1个W和1个b)
最后
以上就是自觉吐司最近收集整理的关于LSTM与GRU的扼要理解LSTM:三个门 - 遗忘门、输入门、输出门GRU:两个门 - 更新门、重置门RNN:没有门结构的全部内容,更多相关LSTM与GRU的扼要理解LSTM:三个门内容请搜索靠谱客的其他文章。








发表评论 取消回复