LSTM和GRU的感性理解
- 零、tanh函数与sigmoid函数
- 1.tanh函数
- 2.sigmoid函数
- 一、RNN简单介绍
- 二、RNN的缺点——短时记忆
- 三、LSTM
- 1.整体结构
- 2.forget gate(遗忘门)
- 3.input gate(输入门)
- 4.cell state(细胞状态)
- 5.output gate(输出门)
- 6.总结
- 7.补充说明
- (1)LSTM中的细胞状态对应RNN中的隐藏状态
- (2)在LSTM中,传递下去的细胞状态变化很慢,而隐藏状态在不同的节点就有较大的区别
- 四、GRU
- 1.整体结构
- 2.update gate(更新门)
- 3.reset gate(重置门)
零、tanh函数与sigmoid函数
1.tanh函数
激活函数 Tanh 用于帮助调节流经网络的值。 tanh 函数将数值始终限制在 -1 和 1 之间。其作用是让数据变化别太大。
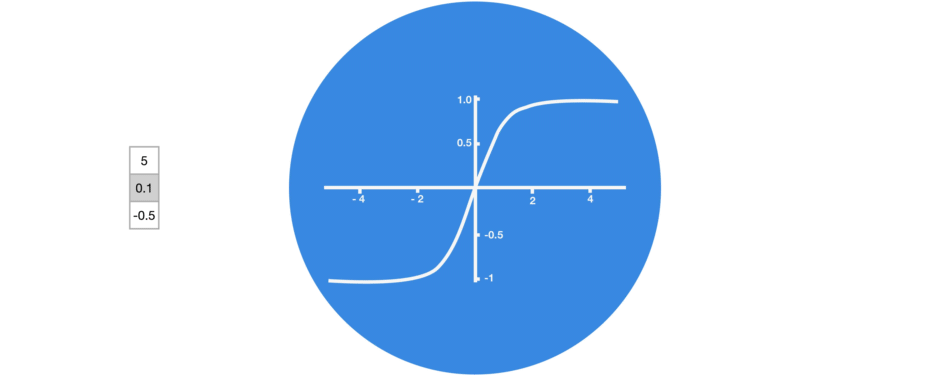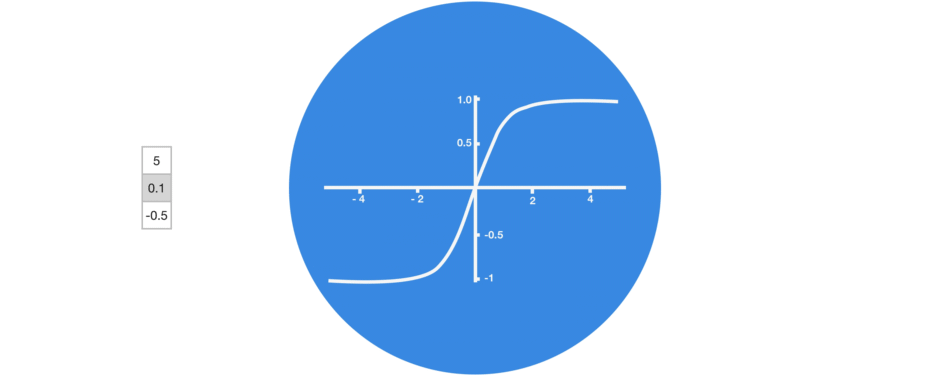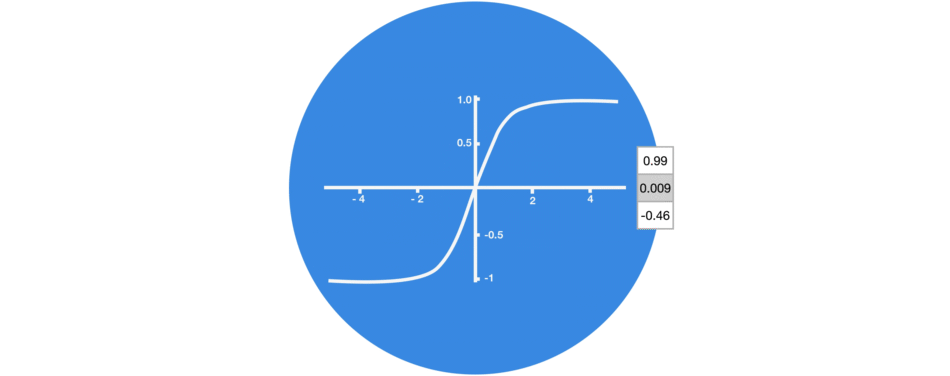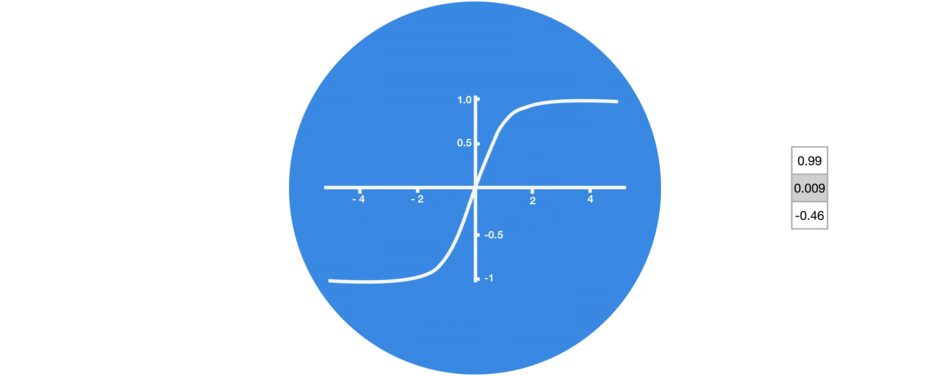
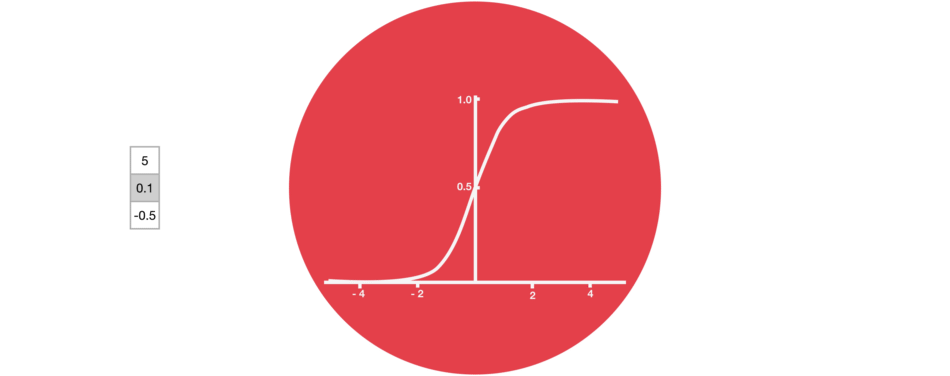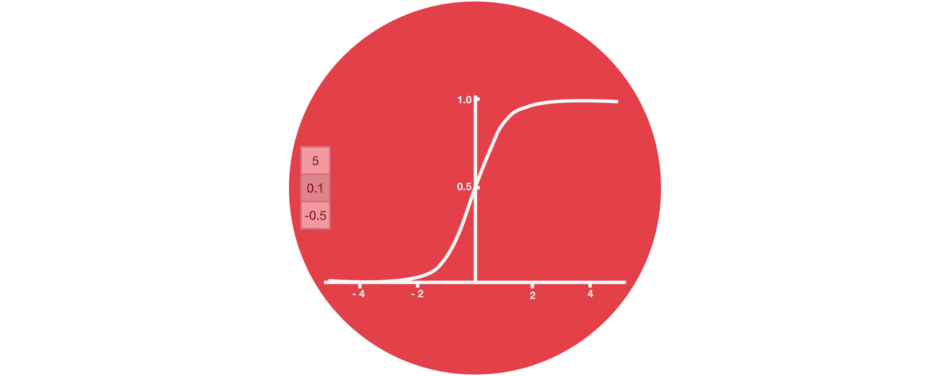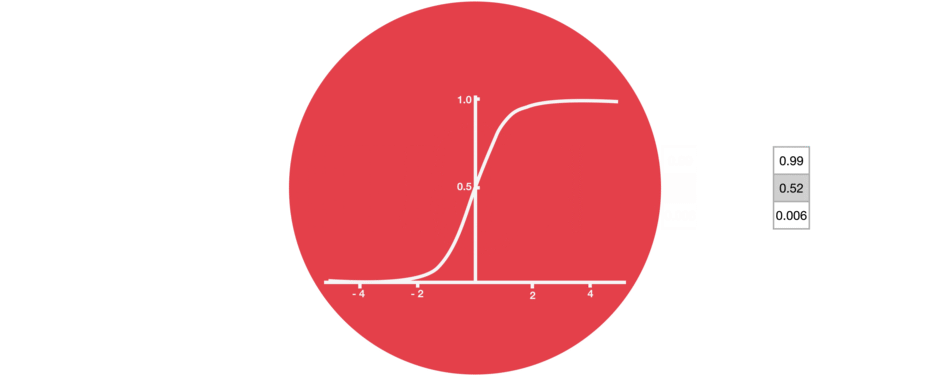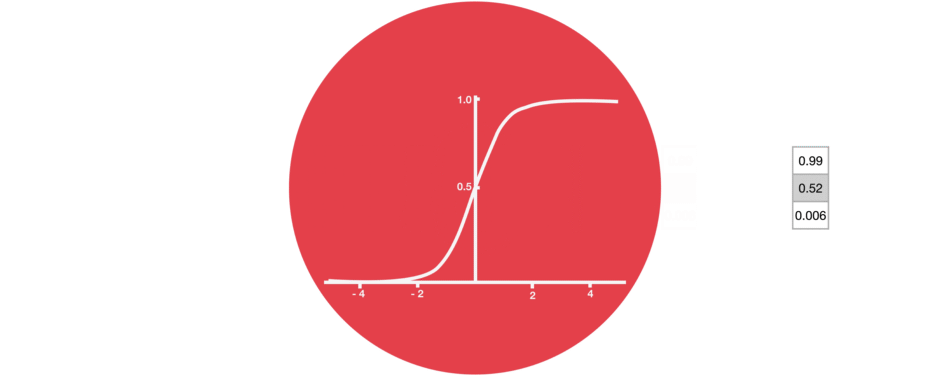
2.sigmoid函数
Sigmoid 激活函数与 tanh 函数类似,不同之处在于 sigmoid 是把值压缩到 0~1 之间而不是 -1~1 之间。这样的设置有助于更新或忘记信息,因为任何数乘以 0 都得 0,这部分信息就会剔除掉。同样的,任何数乘以 1 都得到它本身,这部分信息就会完美地保存下来。这样网络就能了解哪些数据是需要遗忘,哪些数据是需要保存。
一、RNN简单介绍
RNN 的工作原理如下;第一个词被转换成了机器可读的向量,然后 RNN 逐个处理向量序列。
处理时,RNN 将先前隐藏状态传递给序列的下一步。 而隐藏状态充当了神经网络记忆,它包含相关网络之前所见过的数据的信息。
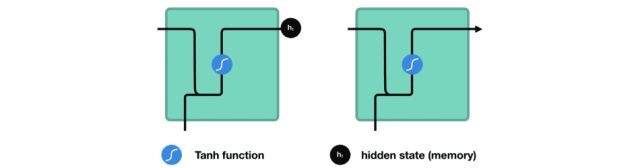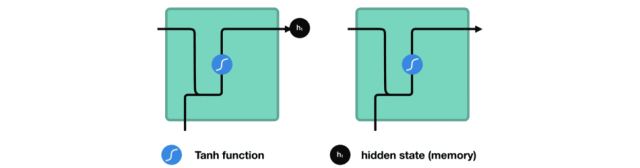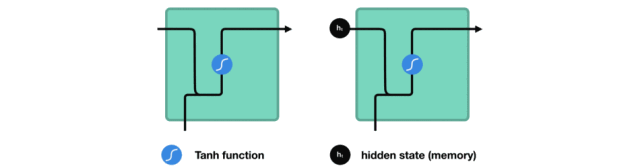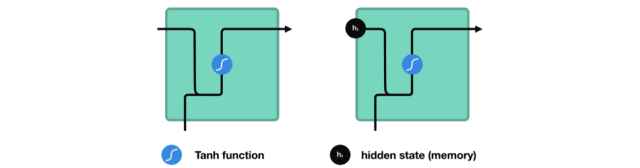
让我们看看 RNN 的一个细胞,了解一下它如何计算隐藏状态。 首先,将输入和先前隐藏状态组合成向量, 该向量包含当前输入和先前输入的信息。 向量经过激活函数 tanh之后,输出的是新的隐藏状态或网络记忆。
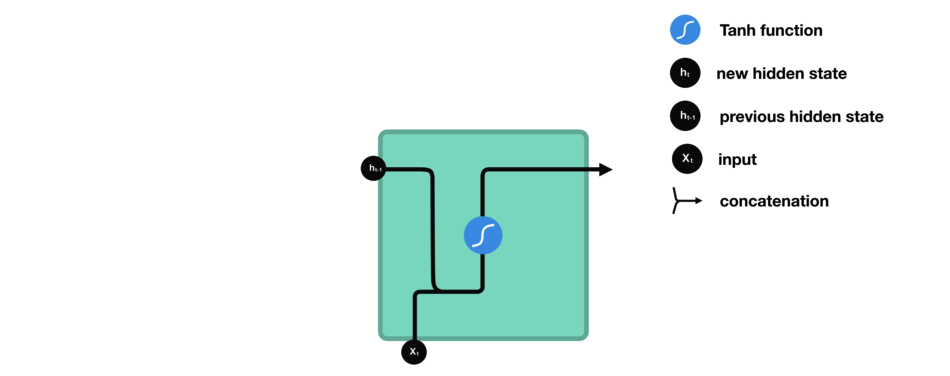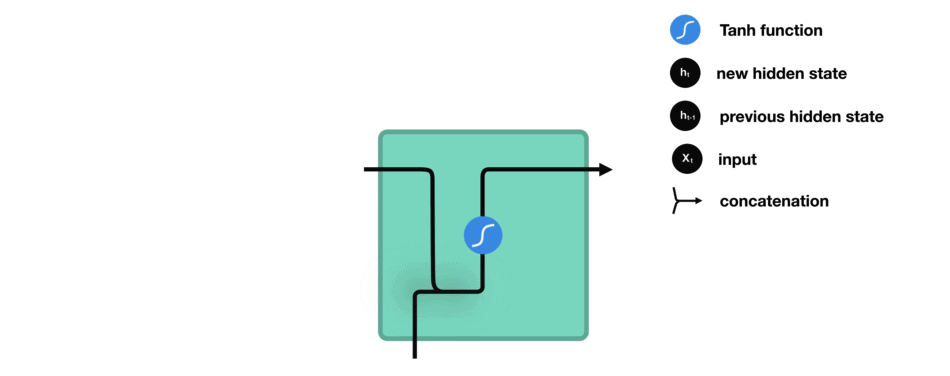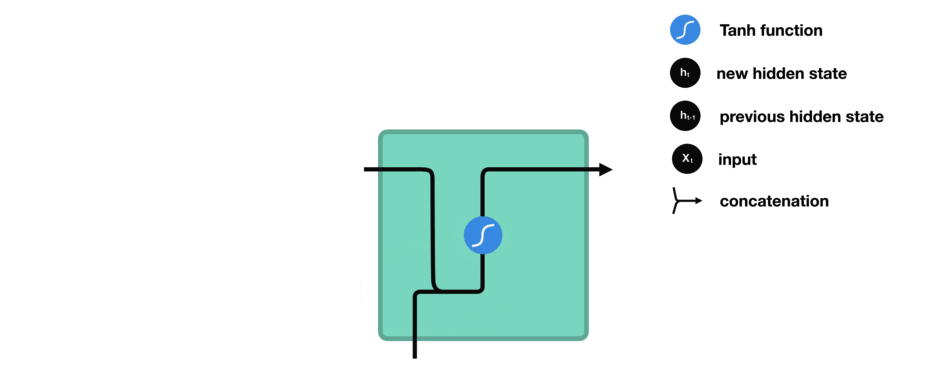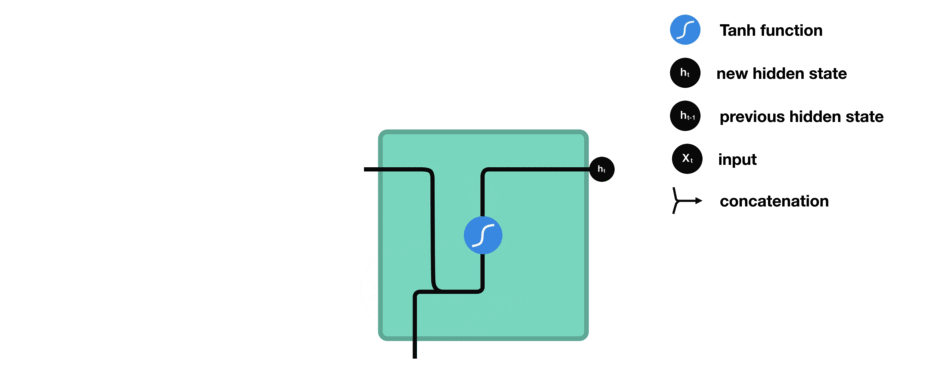 RNN。它内部的操作很少,但在适当的情形下(如短序列)运作的很好。 RNN 使用的计算资源比它的演化变体 LSTM 和 GRU 要少得多。
RNN。它内部的操作很少,但在适当的情形下(如短序列)运作的很好。 RNN 使用的计算资源比它的演化变体 LSTM 和 GRU 要少得多。
二、RNN的缺点——短时记忆
RNN 会受到短时记忆的影响。如果一条序列足够长,那它们将很难将信息从较早的时间步传送到后面的时间步。 因此,如果你正在尝试处理一段文本进行预测,RNN 可能从一开始就会遗漏重要信息。
在反向传播期间,RNN 会面临梯度消失的问题。 梯度是用于更新神经网络的权重值,消失的梯度问题是当梯度随着时间的推移传播时梯度下降,如果梯度值变得非常小,就不会继续学习。

因此,在递归神经网络中,获得小梯度更新的层会停止学习—— 那些通常是较早的层。 由于这些层不学习,RNN 可以忘记它在较长序列中看到的内容,因此具有短时记忆。
三、LSTM
LSTM可以解决RNN的短时记忆问题。
1.整体结构
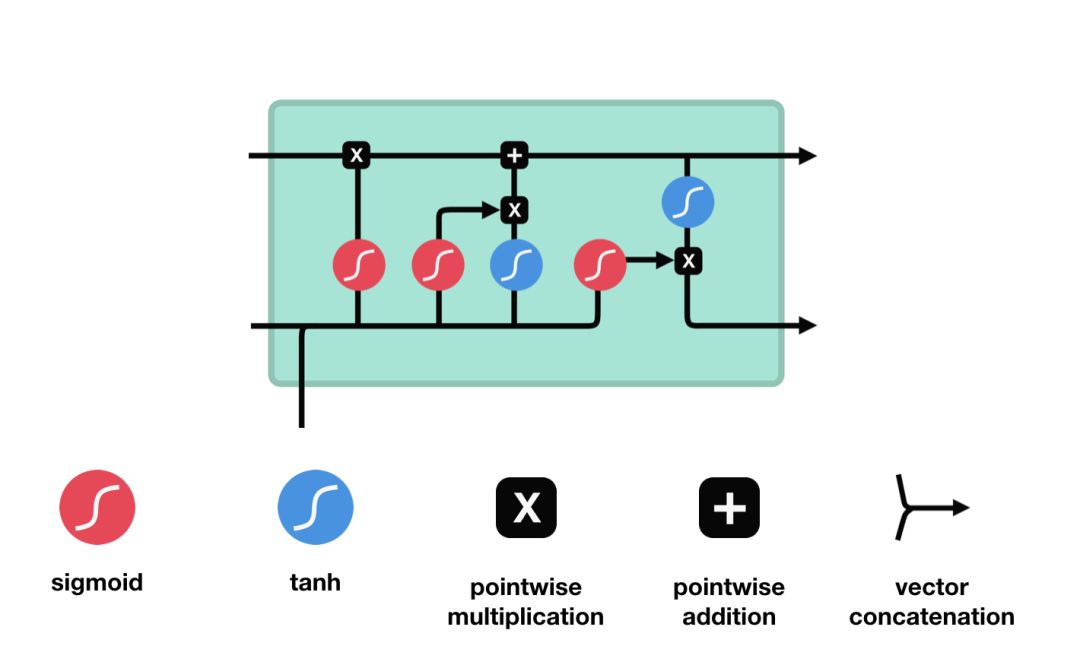
LSTM中有很多成为“门”的内部机制,可以调节信息流。这些“门”可以知道整个输入序列中哪些数据、信息是重要的需要保留,哪些是不用重要的可以删除。随后,它可以沿着长链序列传递相关信息来进行预测。简单来说就是关注有用信息、去掉无用信息。
LSTM 的核心概念在于细胞状态以及“门”结构。细胞状态相当于信息传输的路径,让信息能在序列连中传递下去。你可以将其看作网络的“记忆”。理论上讲,细胞状态能够将序列处理过程中的相关信息一直传递下去。
因此,即使是较早时间步长的信息也能携带到较后时间步长的细胞中来,这克服了短时记忆的影响。信息的添加和移除我们通过“门”结构来实现,“门”结构在训练过程中会去学习该保存或遗忘哪些信息。
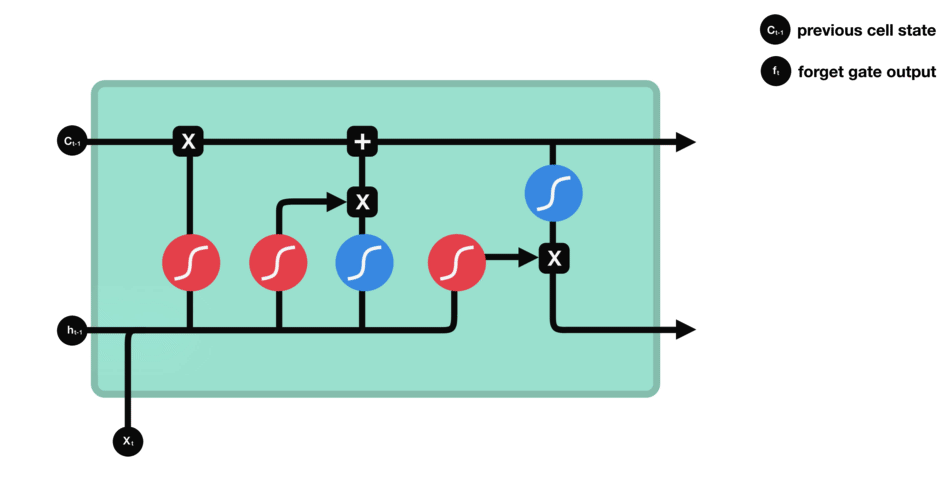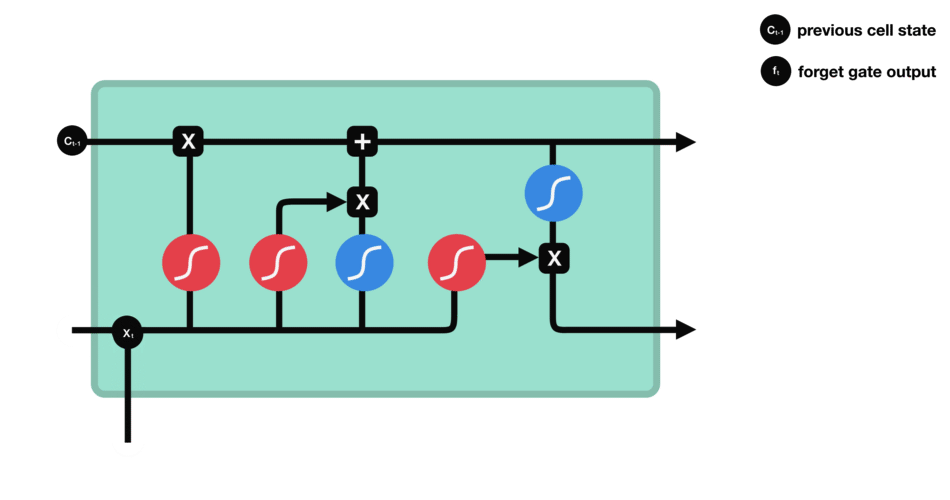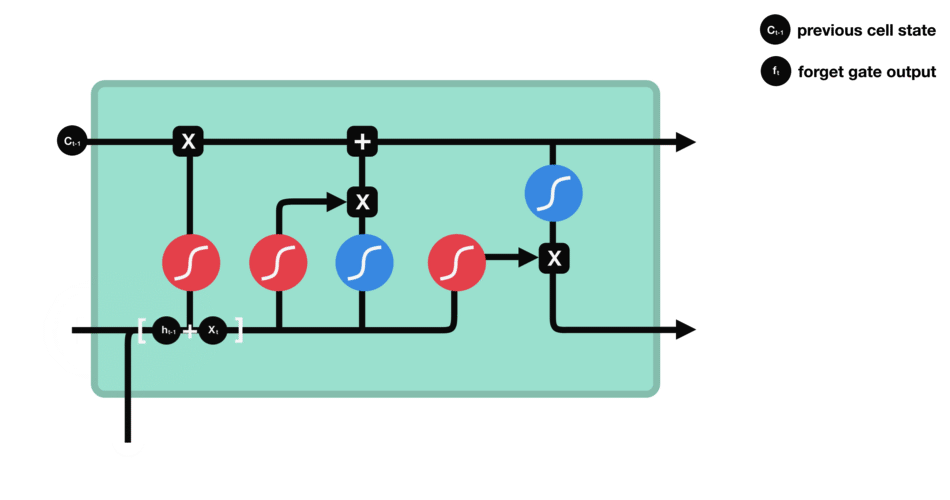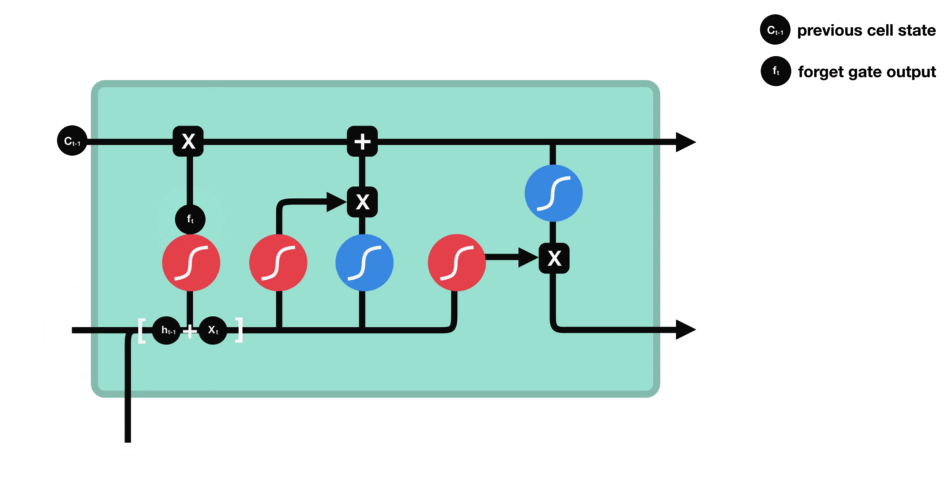
2.forget gate(遗忘门)
遗忘门的功能是决定应该丢弃或者保留哪些信息,来自前一个隐藏状态的信息 h t − 1 h_{t-1} ht−1和当前输入的信息 x t x_{t} xt同时传送入sigmoid函数中,得到的输出 f t f_{t} ft介于0和1之间,越接近0越意味着丢弃,越接近1越意味着保留。
比如当我们要预测下一个词是什么时,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。再比如当我们看到新的主语,我们希望忘记旧的主语。
公式: f t = σ ( W f ⋅ [ h t − 1 , x t + b f ] ) f_{t} = sigma(W_{f}cdot[h_{t-1},x_{t} + b_{f}]) ft=σ(Wf⋅[ht−1,xt+bf])
得出来的
f
t
f_{t}
ft与上一步的细胞状态
c
t
−
1
c_{t-1}
ct−1做point-wise乘法,得出来上一步细胞状态
c
t
−
1
c_{t-1}
ct−1要删除掉什么信息。
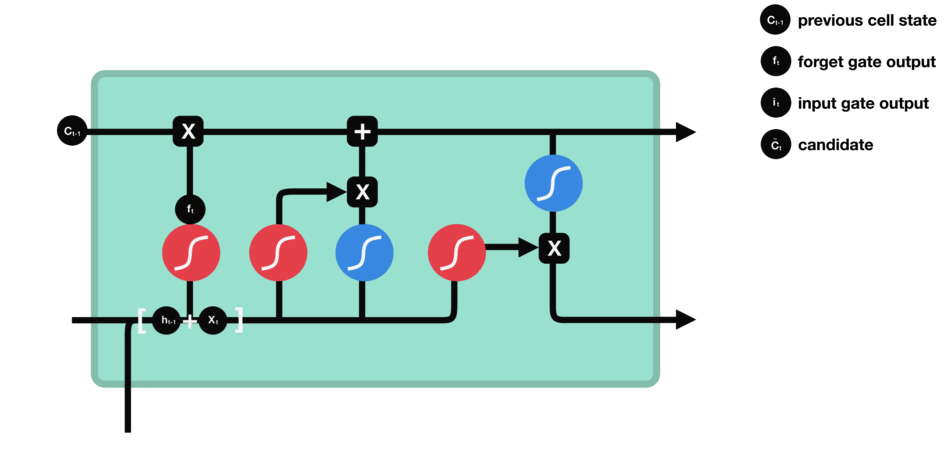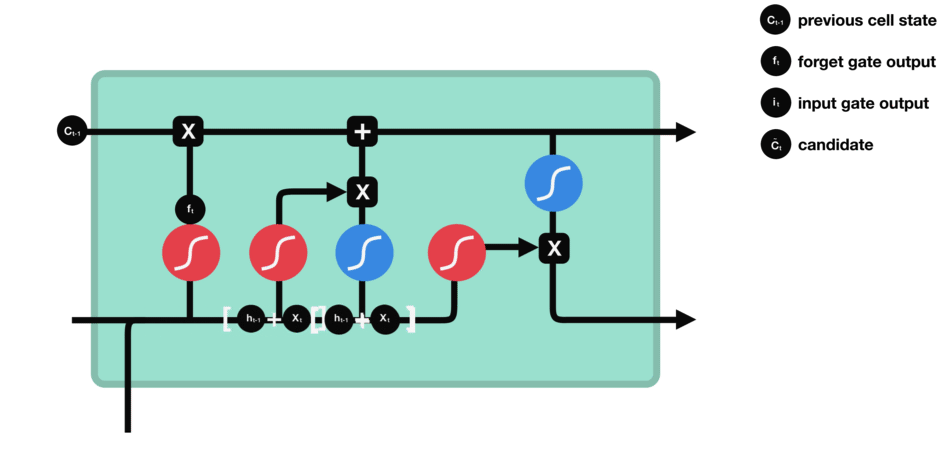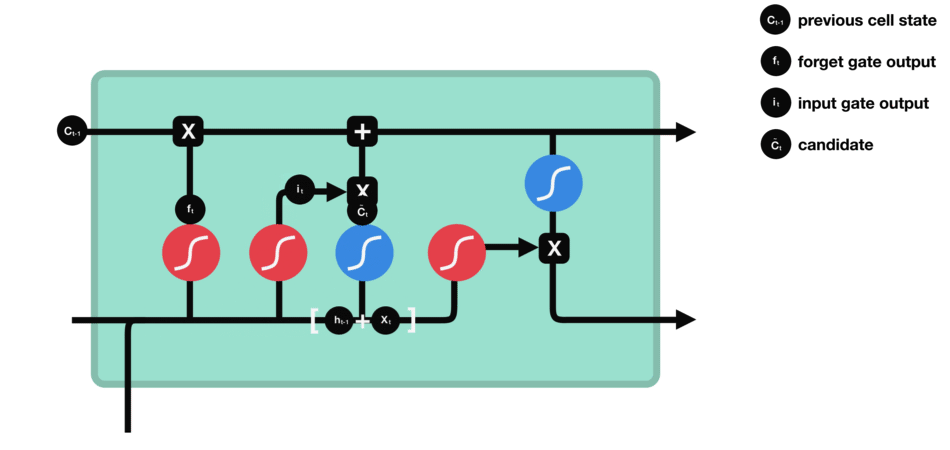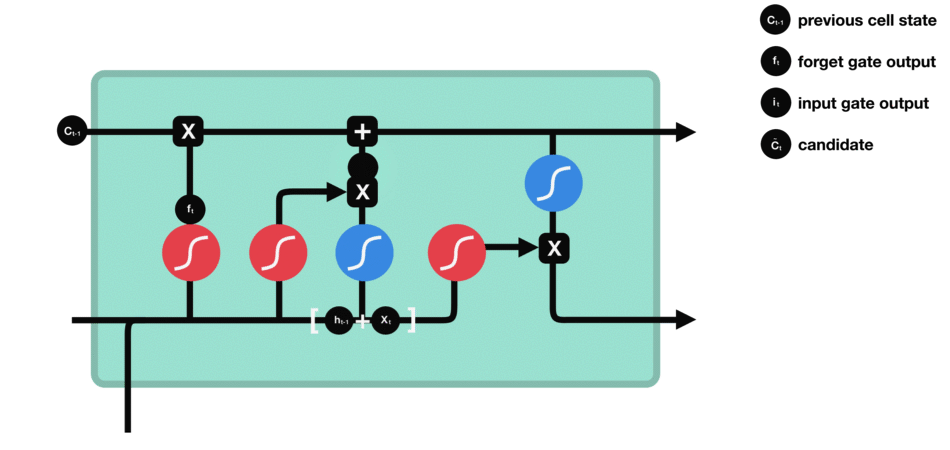
3.input gate(输入门)
输入门用于把新的信息加入到细胞状态中。
首先要将前一层隐藏状态的信息 h t − 1 h_{t-1} ht−1和当前输入的信息 x t x_{t} xt传递到 tanh 函数中去,产生更新值的候选项 c ˇ t check{c}_{t} cˇt,其输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱。
其次将前一层隐藏状态的信息 h t − 1 h_{t-1} ht−1和当前输入的信息 x t x_{t} xt传递到 sigmoid 函数中去,其输出值为 i t i_{t} it。还是0 表示不重要,1 表示重要。
最后将 sigmoid 的输出值与 tanh 的输出值相乘,sigmoid 的输出值将决定 tanh 的输出值中哪些信息是重要且需要保留下来的,起到一个放缩的作用。极端情况下sigmoid输出0说明相应维度上的细胞状态不需要更新。在预测下一个词的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
公式1:
c
ˇ
t
=
t
a
n
h
(
W
c
⋅
[
h
t
−
1
,
x
t
+
b
c
]
)
check{c}_{t} = tanh(W_{c}cdot[h_{t-1},x_{t} + b_{c}])
cˇt=tanh(Wc⋅[ht−1,xt+bc])
公式2:
i
t
=
σ
(
W
i
⋅
[
h
t
−
1
,
x
t
+
b
i
]
)
i_{t} = sigma(W_{i}cdot[h_{t-1},x_{t} + b_{i}])
it=σ(Wi⋅[ht−1,xt+bi])
得出来的
c
ˇ
t
check{c}_{t}
cˇt和
i
t
i_{t}
it做point-wise乘法,得出来的结果与经过遗忘门后的细胞状态
c
t
−
1
c_{t-1}
ct−1做point-wise加法,得到要添加进去什么新的信息。
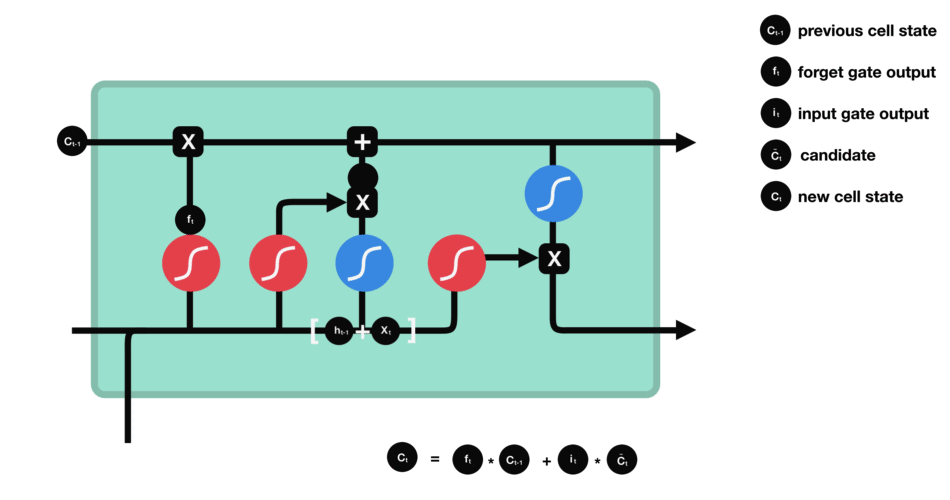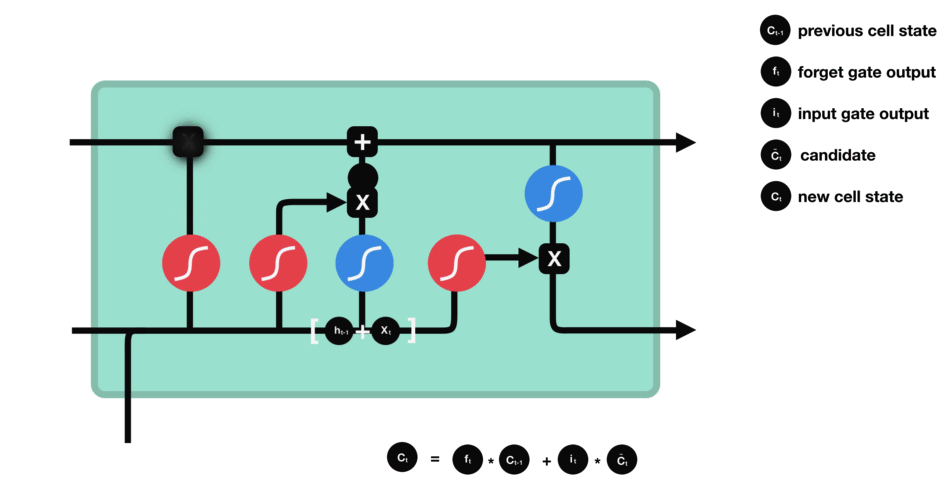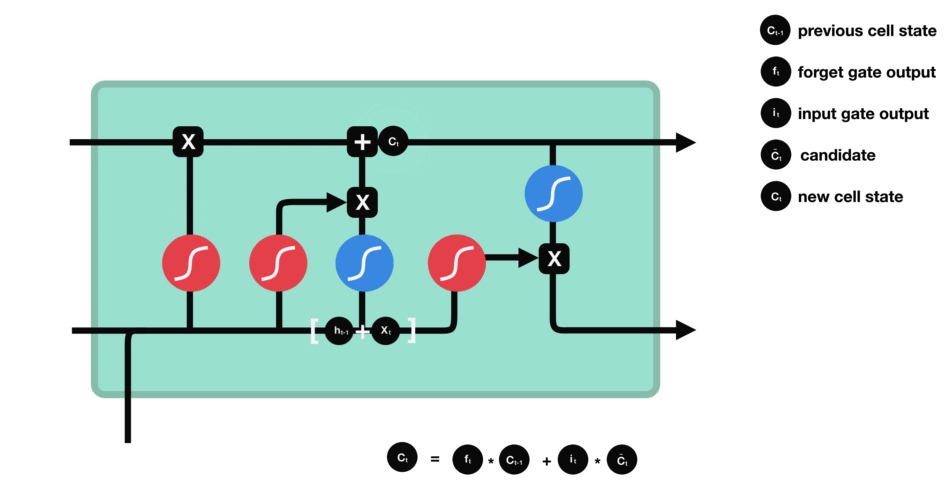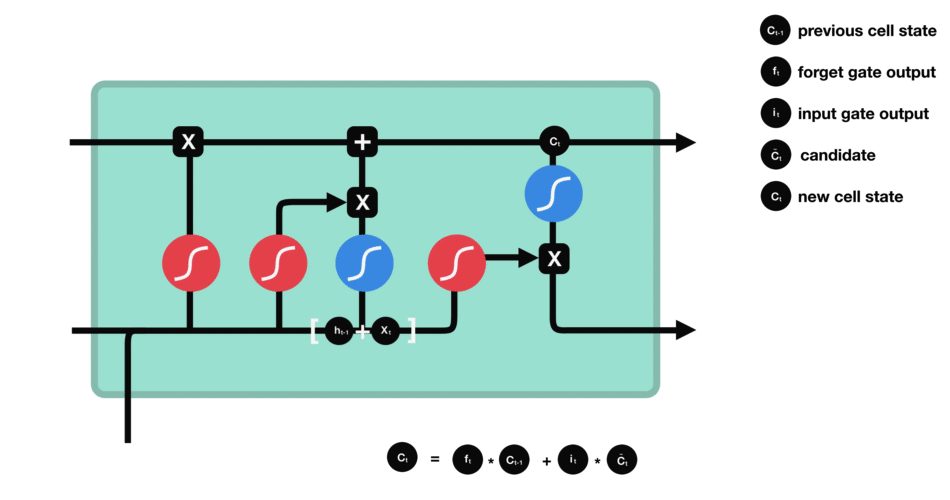
4.cell state(细胞状态)
LSTM模型的核心思想是“细胞状态”。“细胞状态”类似于传送带。直接在整个链上运行(只走最上面一条路),只有一些少量的线性交互。
首先前一层的细胞状态 c t − 1 c_{t-1} ct−1与遗忘向量 f t f_{t} ft逐点相乘。如果它乘以接近 0 的值,意味着在新的细胞状态中,这些信息是需要丢弃掉的。然后再将该值与输入门的输出值逐点相加,将神经网络发现的新信息更新到细胞状态中去。至此,就得到了更新后的细胞状态 c t c_{t} ct。在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的信息并添加新的信息的地方。
公式:
c
t
=
f
t
∗
c
t
−
1
+
i
t
∗
c
ˇ
t
c_{t} = f_{t}ast c_{t-1} + i_{t}ast check{c}_{t}
ct=ft∗ct−1+it∗cˇt
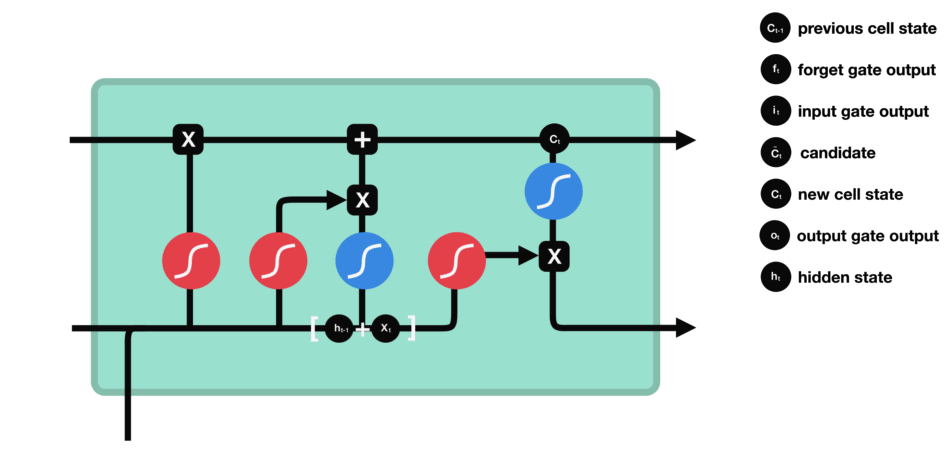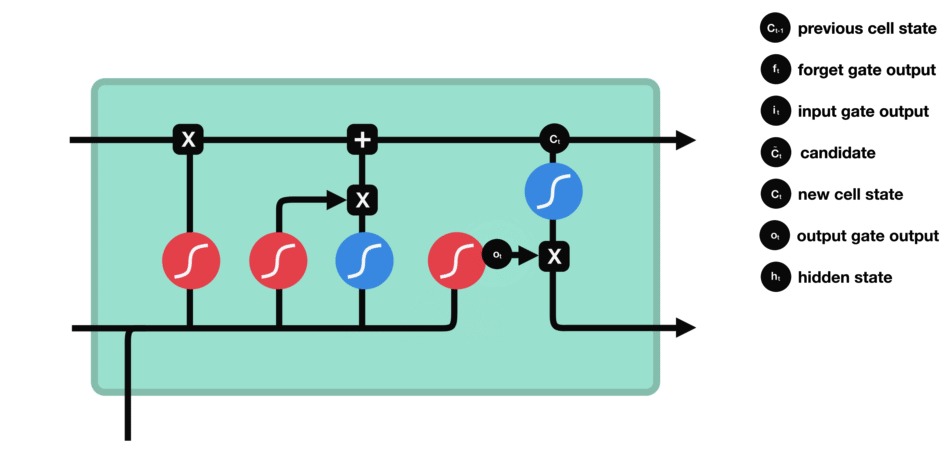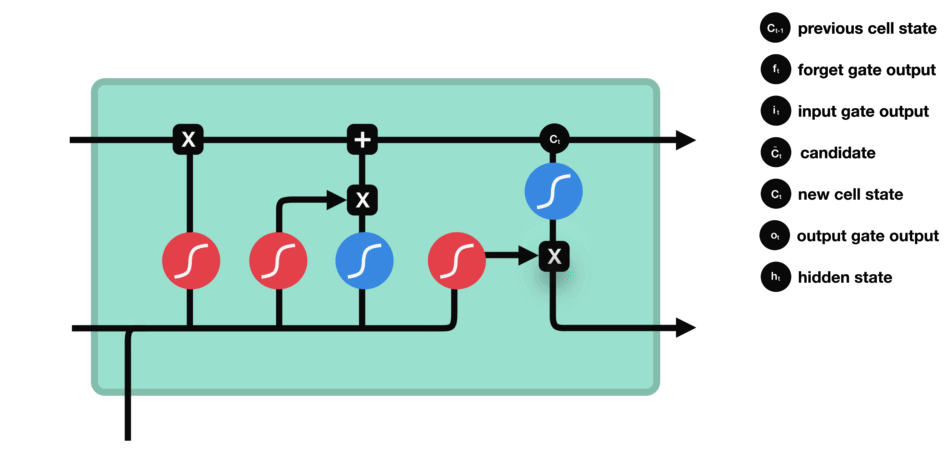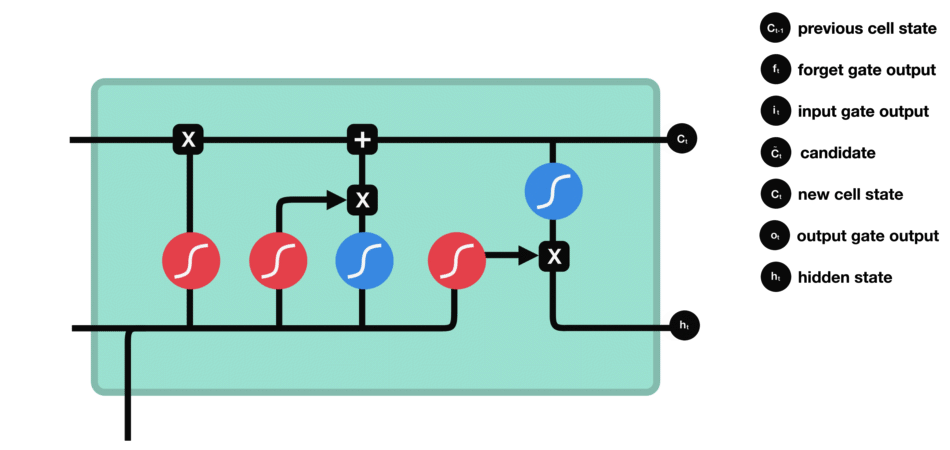
5.output gate(输出门)
输出门用来确定下一个隐藏状态的值。首先,我们将前一个隐藏状态 h t − 1 h_{t-1} ht−1和当前输入 x t x_{t} xt传递到 sigmoid 函数中得到 o t o_{t} ot,然后将新得到的细胞状态 c t c_{t} ct传递给 tanh 函数。最后将 tanh 的输出与 o t o_{t} ot相乘,以确定隐藏状态 h t h_{t} ht应携带的信息。
再将隐藏状态 h t h_{t} ht作为当前细胞的输出,把新的细胞状态 c t c_{t} ct和新的隐藏状态 h t h_{t} ht传递到下一个时间步长中去。在预测下一个词的例子中,如果细胞状态告诉我们当前代词是第三人称,那我们就可以预测下一词可能是一个第三人称的动词。
公式1:
o
t
=
σ
(
W
o
[
h
t
−
1
,
x
t
]
+
b
o
)
o_{t} = sigma(W_{o}[h_{t-1},x_{t}] + b_{o})
ot=σ(Wo[ht−1,xt]+bo)
公式2:
h
t
=
o
t
∗
t
a
n
h
(
c
t
)
h_{t} = o_{t} ast tanh(c_{t})
ht=ot∗tanh(ct)
6.总结
在LSTM模型中,第一步是决定我们从“细胞”中丢弃什么信息,这个操作由一个forget gate(遗忘门)来完成。该层读取当前输入 x t x_{t} xt和前神经元信息 h t − 1 h_{t-1} ht−1,由 f t f_{t} ft来决定丢弃的信息。输出结果1表示“完全保留”,0 表示“完全舍弃”。
第二步是确定细胞状态要添加的新信息,这一步由两层组成。sigmoid层作为“输入门层”,决定我们将要更新的值 i t i_{t} it;tanh层来创建一个新的候选值向量 c ˇ t check{c}_{t} cˇt加入到状态中。
第三步就是更新旧细胞的状态,将 c t − 1 c_{t-1} ct−1更新为 c t c_{t} ct。我们把旧状态 c t − 1 c_{t-1} ct−1与 f t f_{t} ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上 c ˇ t check{c}_{t} cˇt和 i t i_{t} it做point-wise乘法的结果。这就是要加入的新的值,根据我们决定更新每个状态的程度进行变化。
最后一步就是确定输出。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去 o t o_{t} ot。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出 o t o_{t} ot相乘,最终输出 h t h_{t} ht。
我自己的理解: h t − 1 h_{t-1} ht−1代表上一个单元的隐藏信息, c t − 1 c_{t-1} ct−1代表的是所有之前单元的信息, x t x_{t} xt表示当前单元的输入。然后遗忘门负责决定丢弃掉 c t − 1 c_{t-1} ct−1中什么信息,输入门负责决定添加到 c t − 1 c_{t-1} ct−1中什么信息,细胞状态负责把前两步的操作执行到 c t − 1 c_{t-1} ct−1身上生成 c t c_{t} ct,最后输出门负责更新当前单元的隐藏状态 h t h_{t} ht。
7.补充说明
(1)LSTM中的细胞状态对应RNN中的隐藏状态
RNN中只有隐藏状态 h t h_{t} ht,故其保存了先前节点的信息内容;而LSTM中的细胞状态 c t c_{t} ct就是用来保存先前节点的信息内容的,故两者对应。事实上,LSTM中的隐藏状态 h t h_{t} ht是用于结合当前输入来获得门控信号的。
(2)在LSTM中,传递下去的细胞状态变化很慢,而隐藏状态在不同的节点就有较大的区别
c t c_{t} ct是cell state中的内容,其为一条主线,用来保存节点传递的数据。在每次传递的过程中,其会遗忘一些内容并加入当前节点的内容,但其主要任务依旧是保存节点的信息,故改变会较小。但是,隐藏状态 h t h_{t} ht主要任务是结合当前输入来获得门控信号,故对于不同的输入,传递给下一状态的 h t h_{t} ht区别也比较大。
四、GRU
1.整体结构
GRU也可以解决RNN的短时记忆问题。
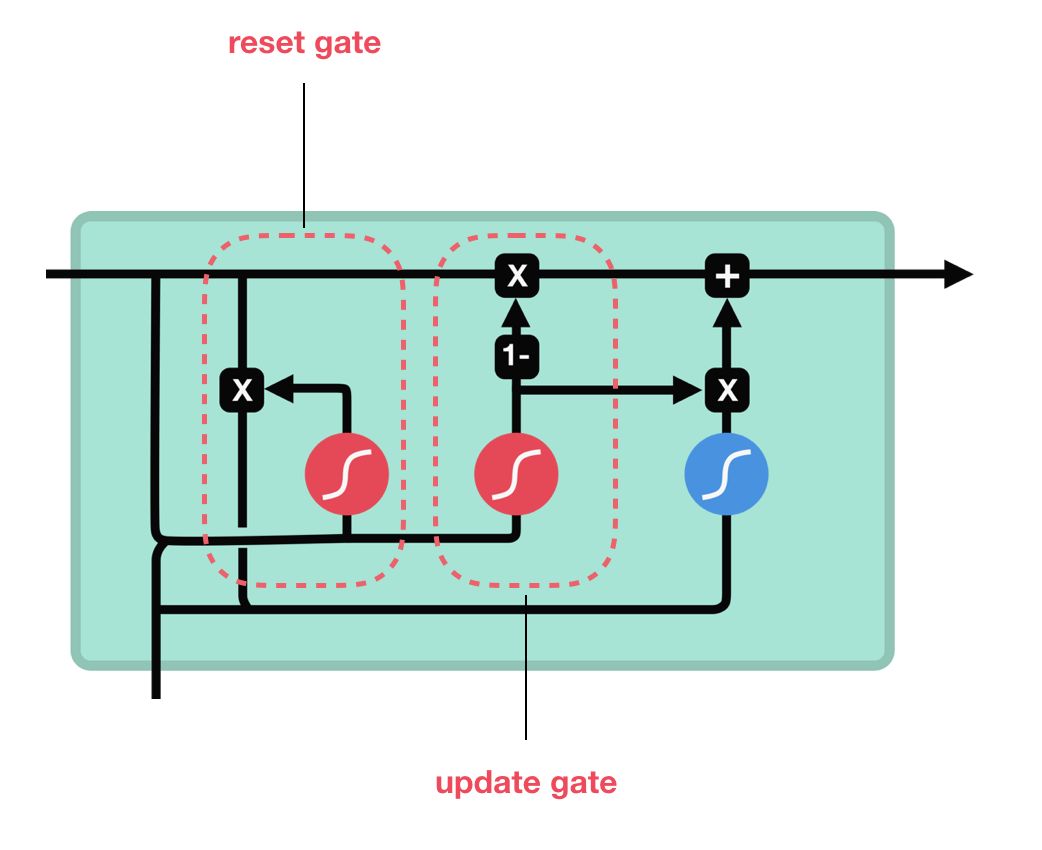
GRU作为LSTM的一种变体,将遗忘门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加之其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
GRU 的张量运算较少,因此它比 LSTM 的训练更快一下。很难去判定这两者到底谁更好,研究人员通常会两者都试一下,然后选择最合适的。
2.update gate(更新门)
更新门的作用类似于 LSTM 中的遗忘门和输入门。它决定了要忘记哪些信息以及哪些新信息需要被添加。
3.reset gate(重置门)
重置门用于决定遗忘先前信息的程度,直接作用于前面的隐藏状态(没有细胞状态了,只有隐藏状态)。
最后
以上就是花痴镜子最近收集整理的关于LSTM和GRU看完必须全部了然零、tanh函数与sigmoid函数一、RNN简单介绍二、RNN的缺点——短时记忆三、LSTM四、GRU的全部内容,更多相关LSTM和GRU看完必须全部了然零、tanh函数与sigmoid函数一、RNN简单介绍二、RNN内容请搜索靠谱客的其他文章。








发表评论 取消回复