http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
翻译:
https://zhuanlan.zhihu.com/p/22338087
随时间的反向传播(BPTT)
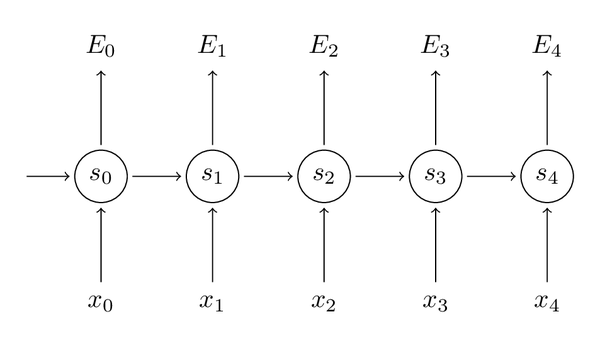
让我们先迅速回忆一下RNN的基本公式,注意到这里在符号上稍稍做了改变(o变成
y^
),这只是为了和我参考的一些资料保持一致。
st=tanh(Uxt+Wst−1)
y^t=softmax(Vst)
同样把损失值定义为交叉熵损失,如下:
Et(yt,y^t)=−ytlog(y^t)
E(y,y^)=∑tEt(yt,y^t)=−∑tytlogy^t
这里,
yt
表示时刻t正确的词,
y^t
是我们的预测。通常我们会把整个句子作为一个训练样本,所以总体错误是每一时刻的错误的加和。
我们的目标是计算错误值相对于参数U, V, W的梯度以及用随机梯度下降学习好的参数。就像我们要把所有错误相加一样,我们同样会把每一时刻针对每个训练样本的梯度值相加:
∂E∂W=∑t∂Et∂W
。
为了计算梯度,我们使用链式求导法则,主要是用反向传播算法往后传播错误。下文使用
E3
作为例子,主要是为了描述方便。
∂E3∂V=∂E3∂y^3∂y^3∂V=∂E3∂y^3∂y^3∂z3∂z3∂V=(y^3−y3)⊗s3
上面
z3=Vs3
,
⊗
是向量的外积。如果你不理解上面的公式,不要担心,我在这里跳过了一些步骤,你可以自己尝试来计算这些梯度值。这里我想说明的一点是梯度值只依赖于当前时刻的结果
y^3,y3,s3
。根据这些,计算V的梯度就只剩下简单的矩阵乘积了。
但是对于梯度
∂E3∂W
情况就不同了,我们可以像上面一样写出链式法则。
∂E3∂W=∂E3∂y^3∂y^3∂s3∂s3∂W
注意到这里的
s3=tanh(Uxt+Ws2)
依赖于
s2
,
s2
依赖于W和
s1
,等等。所以为了得到W的梯度,我们不能将
s2
看作常量。我们需要再次使用链式法则,得到的结果如下:
∂E3∂W=∑3k=0∂E3∂y^3∂y^3∂s3∂s3∂sk∂sk∂W
我们把每一时刻得到的梯度值加和,换句话说,W在计算输出的每一步中都使用了。我们需要通过将t=3时刻的梯度反向传播至t=0时刻。
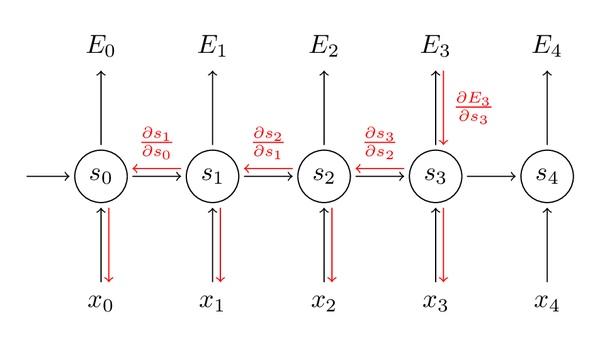
注意到这里和我们在深度前向神经网络中使用的标准反向传播算法是一致的,关键不同在于我们把每一时刻针对W的不同梯度做了加和。在传统神经网络中,不需要在层之间共享参数,就不需要做任何加和。在我看来,BPTT是应用于展开的RNN上的标准反向传播的另一个名字。就像反向传播一样,你也可以定义一个反向传递的delta向量,例如,
δ(3)2=∂E3z2=∂E3∂s3∂s3∂s2∂s2∂z2
,其中
z2=Ux2+Ws1
。
这会让你明白为什么标准RNN很难训练:序列会变得很长,可能有20个词或更多,因而就需要反向传播很多层。实践中,很多人会把发现传播截断至几步。
梯度消失问题
在教程前一部分,我提到RNN很难学到长范围的依赖——相隔几步的词之间的交互。这是有问题的因为英语中句子的意思通常由相距不是很近的词来决定:“The man who wore a wig on his head went inside”。这个句子讲的是一个男人走了进去,而不是关于假发。但是普通的RNN不可能捕捉这样的信息。要理解为什么,让我们先仔细看一下上面计算的梯度:
∂E3∂W=∑3k=0∂E3∂y^3∂y^3∂s3∂s3∂sk∂s3∂W
注意到
∂s3∂sk
也需要使用链式法则,例如,
∂s3∂s1=∂s3∂s2∂s2∂s1
。注意到因为我们是用向量函数对向量求导数,结果是一个矩阵(称为Jacobian Matrix),矩阵元素是每个点的导数。我们可以把上面的梯度重写成:
∂E3∂W=∑3k=0∂E3∂y^3∂y^3∂s3(∏3j=k+1∂sj∂sj−1)∂sk∂W
可以证明上面的Jacobian矩阵的二范数(可以认为是一个绝对值)的上界是1。这很直观,因为激活函数tanh把所有制映射到-1和1之间,导数值得界限也是1:
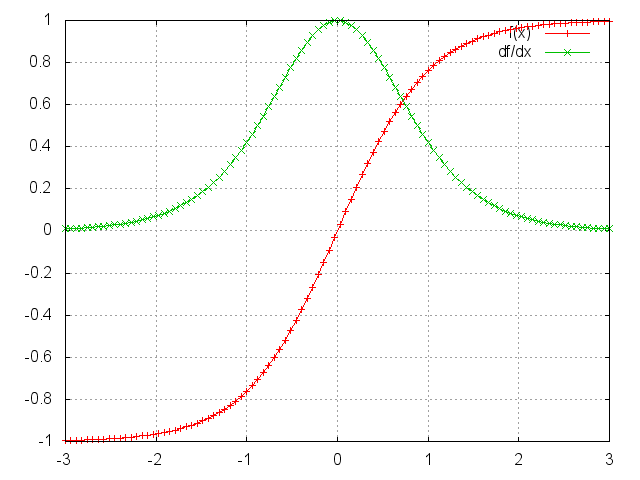
你可以看到tanh和sigmoid函数在两端的梯度值都为0,接近于平行线。当这种情况出现时,我们就认为相应的神经元饱和了。它们的梯度为0使得前面层的梯度也为0。矩阵中存在比较小的值,多个矩阵相乘会使梯度值以指数级速度下降,最终在几步后完全消失。比较远的时刻的梯度值为0,这些时刻的状态对学习过程没有帮助,导致你无法学习到长距离依赖。消失梯度问题不仅出现在RNN中,同样也出现在深度前向神经网中。只是RNN通常比较深(例子中深度和句子长度一致),使得这个问题更加普遍。
很容易想到,依赖于我们的激活函数和网络参数,如果Jacobian矩阵中的值太大,会产生梯度爆炸而不是梯度消失问题。梯度消失比梯度爆炸受到了更多的关注有两方面的原因。其一,梯度爆炸容易发现,梯度值会变成NaN,导致程序崩溃。其二,用预定义的阈值裁剪梯度可以简单有效的解决梯度爆炸问题。梯度消失出现的时候不那么明显而且不好处理。
幸运的是,已经有一些方法解决了梯度消失问题。合适的初始化矩阵W可以减小梯度消失效应,正则化也能起作用。更好的方法是选择ReLU而不是sigmoid和tanh作为激活函数。ReLU的导数是常数值0或1,所以不可能会引起梯度消失。更通用的方案时采用长短项记忆(LSTM)或门限递归单元(GRU)结构。LSTM在1997年第一次提出,可能是目前在NLP上最普遍采用的模型。GRU,2014年第一次提出,是LSTM的简化版本。这两种RNN结构都是为了处理梯度消失问题而设计的,可以有效地学习到长距离依赖。
https://www.zhihu.com/question/34878706
LSTM只能避免RNN的梯度消失(gradient vanishing);梯度膨胀(gradient explosion)不是个严重的问题,一般靠裁剪后的优化算法即可解决,比如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩)。下面简单说说LSTM如何避免梯度消失.
传统的RNN总是用“覆写”的方式计算状态 St=f(St−1,xt) ,其中 f(⋅) 表示仿射变换外面在套一个Sigmoid, xt 表示输入序列在时刻 t 的值。根据求导的链式法则,这种形式直接导致梯度被表示为连成积的形式,以致于造成梯度消失——粗略的说,很多个小于1的项连乘就很快的逼近零。
现代的RNN(包括但不限于使用LSTM单元的RNN)使用“累加”的形式计算状态:
St=∑tτ=1ΔSτ ,其中的 ΔSτ 显示依赖序列输入 xt . 稍加推导即可发现,这种累加形式导致导数也是累加形式,因此避免了梯度消失。
最后
以上就是生动保温杯最近收集整理的关于[rnn]BPTT_梯度消失/爆炸问题的全部内容,更多相关[rnn]BPTT_梯度消失/爆炸问题内容请搜索靠谱客的其他文章。




![[rnn]BPTT_梯度消失/爆炸问题](https://www.shuijiaxian.com/files_image/reation/bcimg11.png)



发表评论 取消回复