WaveNet论文学习
文章目录
- WaveNet论文学习
- 摘要
- 应用方向
- 模型结构
- 1.WaveNet运用了因果卷积与扩大卷积。
- 2.SOFTMAX分布
- 3.门控激活单元
- 4.残差连接和跳步连接
- 5.条件WaveNet
- 6.上下文堆栈
- 详细实验内容
- 总结
摘要
WaveNet是一个生成原始音频波形的深度神经网络。WaveNet是一个完全概率自回归模型,每个音频样本的预测分布取决于之前的所有样本。WaveNet可以在每秒数万采样率的音频数据上高效地进行训练。
应用方向
这篇论文研究了WaveNet在三个方向的应用:语音合成、语音识别与音乐合成。
在语言合成方向:WaveNet获得了当前业界最佳的性能。WaveNet测试了英语和普通话的语音合成,并于此前效果最好的两种方式:参数式与拼接式进行了对比。主观评价表明:WaveNet在自然度上有大幅度的提升。
在语音识别方向:WaveNet可以以相同的保真度捕获很多说话人的特征,并可以针对说话者进行训练后在多人之间切换语音特征。
在音乐合成方向:WaveNet可以产生新颖的高度真实的音乐片段,且在判别模型应用在音素识别中有客观的前景。
模型结构
1.WaveNet运用了因果卷积与扩大卷积。
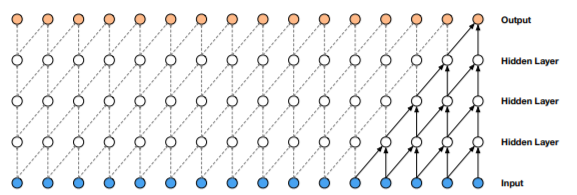
因果卷积确保了模型输出不会违反数据的顺序,模型在某时刻输出的预测不会依赖任何一个未来时刻的数据。
且在训练阶段,每个时刻的输出需要计算的样本都是已知的,因此所有时刻的条件概率预测可以并行计算。
由于使用因果卷积的模型中没有循环连接,通常训练起来比RNN更快,特别是对于很长句子的训练。
因果卷积存在的一个问题是它需要很多层,或者很大的卷积核来增大其感受野。例如,在上图2中,感受野只有5个单位 。(感受野 = 层数 + 卷积核长度 - 1)。
因此WaveNet使用扩大卷积使感受野增大几个数量级,同时不会显著增加计算成本。
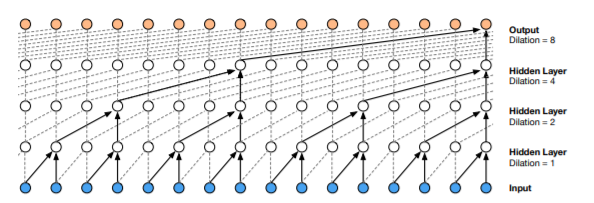
扩大卷积是卷积核在比自身大的数据上进行卷积时跳步的卷积方法。与正常卷积相比,扩大卷积有效地使网络可以执行粗粒度的卷积操作。
在上图中,扩大卷积的扩大系数每层翻倍(1,2,4,8),只通过少数几层便拥有了非常大的感受野(16个单位)。WaveNet中最大的扩大系数达到了512,拥有1024个单位的感受野。
2.SOFTMAX分布
原始音频通常保存为16Bit规格 ,对每个时刻输出的可能值 ,softmax层将需要输出65536个值。为了更方便快捷地计算,需要先对数据实施一个µ-law压扩变换,然后取到256个量化值。µ-law压扩变换算法如下:
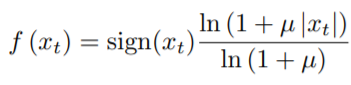
实验证明,使用上述方法重构后的信号听起来非常接近原始信号。
3.门控激活单元
WaveNet使用与gated PixelCNN 中相同的门控激活单元,公式如下所示。
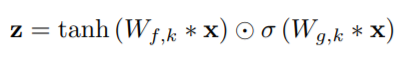
其中∗代表卷积操作,⊙代表点乘操作,σ(.)是sigmoid函数,k是层索引,f和g是各自的滤波器和门,W是可学习的卷积核。
实验证明,在音频信号建模方面,该非线性操作显著优于ReLU激活函数。
4.残差连接和跳步连接
WaveNet使用了残差和跳步连接,以加速收敛并允许更深的模型训练。该结构示意图如下:
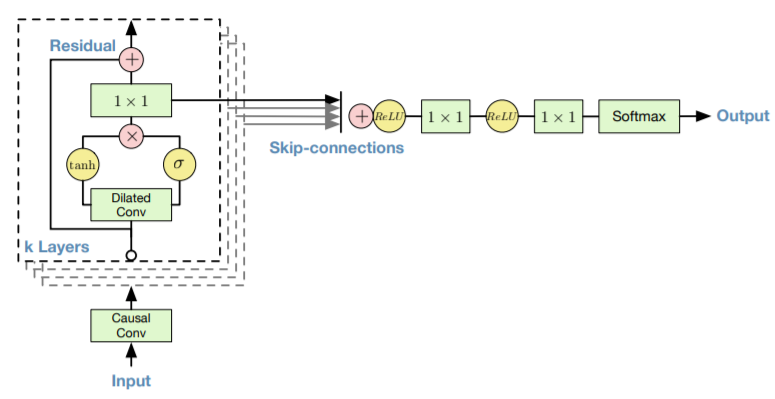
WaveNet中会将多个这样的模块堆叠在一起。
5.条件WaveNet
给定一个额外输入h,WaveNets可以由这个给定输入。
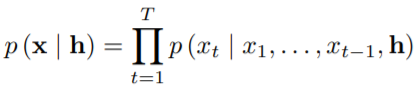
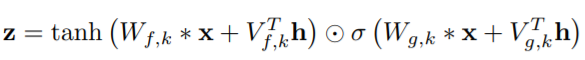
基于输入变量进行条件建模,可以引导WaveNet产生要求特征的音频。例如,可以把说话人身份作为条件输入给WaveNet,然后WaveNet将选择该说话人的声音进行音频输出。
6.上下文堆栈
上文中提出了多种方法来增加WaveNet的感受野大小:增加扩大系数的大小,使用更多的层数,更大的过滤器,更大的膨胀系数,或者他们的组合。
补充的一个方法是:使用单独的更小的上下文堆栈来处理语音信号的长跨度信息,并在局部条件下形成处理较大的WaveNet,该WaveNet只处理音频信号的一小部分(在结尾处裁剪)。
你可以使用具有不同长度和数量隐藏单元的多个上下文堆栈。感受野越大的堆栈每层的单位就越少。上下文堆栈也可以有以较低频率运行的池层。这将计算需求保持在一个合理的水平上,并与在较长时间尺度上建模时间相关性所需的容量较少的直觉相一致。
详细实验内容
详细实验内容见WaveNet项目主页
https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
总结
本WaveNet是一个音频数据的深度生成模型,它直接在波形水平上运行。
WaveNet是自回归的,并将因果滤波器与扩张的卷积相结合,以允许它们的接受域随深度呈指数增长,这对模拟音频信号的长期时间依赖性很重要。
上文已经展示了如何在全局(如说话人身份)或局部(如语言特征)的输入条件下调节波。
当应用到TTS时,WaveNet产生的样本在主观自然性方面优于目前最好的TTS系统。
最后,在应用于音乐音频建模和语音识别方面,小波网络显示了非常有前途的结果。
最后
以上就是不安小鸭子最近收集整理的关于【论文学习笔记】《WaveNet: A generative model for raw audio》WaveNet论文学习的全部内容,更多相关【论文学习笔记】《WaveNet:内容请搜索靠谱客的其他文章。


![[Machine Learning] 搭建神经网络(一层、二层和多层)](https://www.shuijiaxian.com/files_image/reation/bcimg22.png)





发表评论 取消回复