什么什么seq2seq结构不是搞机器翻译的吗,咋也可以用在序列预测方面,在最近看到的一篇论文中,作者用他的DARNN模型实现了股票的预测,想来整理总结一下这篇论文
预备知识
在文章开始之前,先来了解下什么是seq2seq结构,seq2seq其实是深度学习中一种模型的架构,主要用于的是机器翻译领域,其实本质上就是用了两个循环神经网络将一个语言序列直接转换为了另外一个语言序列,在这里,循环神经网络可以简单理解为一个动力系统,可以自主学习一组片段(句子,信号这类等)的序列中的关系,能够通过前面的状态来预测后面的状态,在这里后面我会简单的介绍,那序列到序列模型其实是RNN(后面循环神经网络都由这个代替)的升级版,在机器翻译过程中,其实就是联合了两个RNN来处理序列,一个用来负责接收源句子,一个用来将句子转换为要翻译成的语言,这两个过程分别被称为编码和解码过程,用英文表示为encoder-decoder
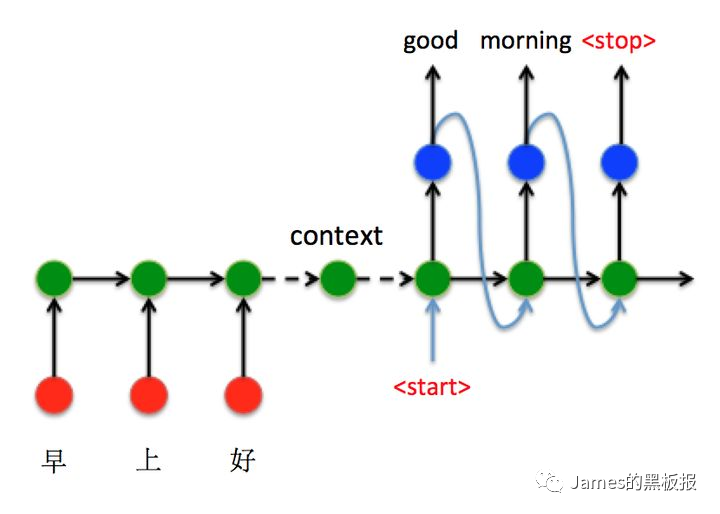
循环神经网络(RNN)
循环神经网络是一种网络结构,通过使用带有自反馈的神经元,能够处理任意长度的时序数据,这个数据可以是文本,可以是信号,数据的类型不重要,但保证能够前后由依赖就行,最终都会通过一个embedding层转化为词向量输入到网络中,例如,我们给定一个输入序列(x1,x2,x3…xT),循环神经网络通过下面公式更新带有反馈边的隐藏层的活性值ht
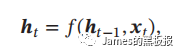 其中h0 = 0,f()是一个非线性函数,例如循环神经网络的变种LSTM,GRU这些,我们来看下网络结构
其中h0 = 0,f()是一个非线性函数,例如循环神经网络的变种LSTM,GRU这些,我们来看下网络结构
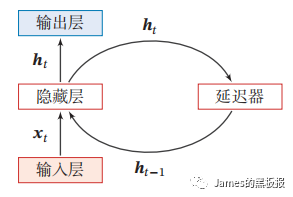
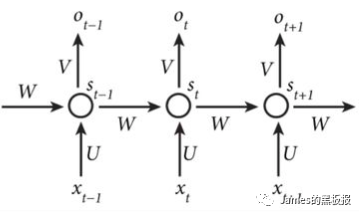 上面的两个图可以结合起来看,我们的词向量就是xt,在上图中的延迟器用于记录神经元最近一次或者几次的活性值,这个活性值可以称为状态(s)或者隐状态(h),所以每次由新的输入进去,隐状态都会结合上一步的隐状态输入和当前输入进行更新,在二图中,我们可以看到由W,U,V三个变量,这些就是更新权重,他们是共享的,理论上,RNN可以模拟任意的非线性函数,但是也存在一些弊端,所以诞生了很多变种,譬如lstm,gru,在这里不展开赘述了
上面的两个图可以结合起来看,我们的词向量就是xt,在上图中的延迟器用于记录神经元最近一次或者几次的活性值,这个活性值可以称为状态(s)或者隐状态(h),所以每次由新的输入进去,隐状态都会结合上一步的隐状态输入和当前输入进行更新,在二图中,我们可以看到由W,U,V三个变量,这些就是更新权重,他们是共享的,理论上,RNN可以模拟任意的非线性函数,但是也存在一些弊端,所以诞生了很多变种,譬如lstm,gru,在这里不展开赘述了
编码器
编码过程实际使用了循环神网络记忆的功能,通过上下文的序列关系,将词向量依次输入网络对于循环神经网络,这里的词向量可以理解为一段句子转化为了一组向量的结果,我们知道每一次网络都会输出一个结果,但是编码不同之处在于,其只保留最后一个隐藏状态,相当于将整句话浓缩在一起,将其存为一个内容向量context,供后面的解码器使用
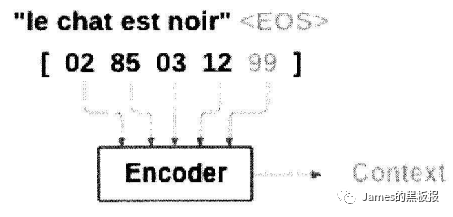
解码器
编码器和解码器的结构几乎一样,但是在解码过程中,是根据前面的结果来得到后面的结果,比如,我们在编码过程中输入一句话,这一句话是一个序列,而且序列中的每一个词都是已知的,解码过程是什么也不知道的,所以我们需要一个标识来表示一句话的开始,然后将其输入到网络中得到第一个输出来作为这句话的第一个词,再通过这个词作为网络的下一个输入,得到的输出作为第二个词,如此循环往复,来得到最后网络输出的一句话
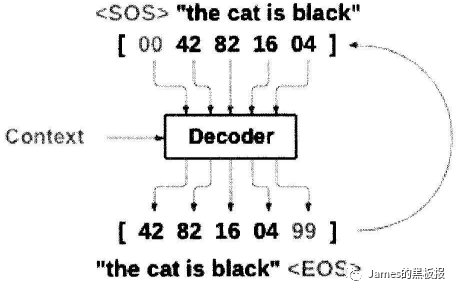
所以说编码器与解码器本身就是两个神经网络各自处理各自的事,单纯的seq2seq可以结合注意力机制,强化学习等策略获得更好的性能

注意力机制(attention)
注意力机制很好理解,举个生活场景

比如做阅读理解,如果一段话特别长记不住的话,我们会着重记住其中的几个关键片段,来推断句子的语义,那在编码过程中,如果一句话很长,那么经过压缩得到的context向量往往会损失很多信息,影响解码过程,由于context向量是通过隐状态的不断更新而得到的,但是更新过程中每一步的输出我们并没有利用到,attention就是指在解码过程中能够将注意力集中处理编码过程中输出的部分上,而不是依赖于context
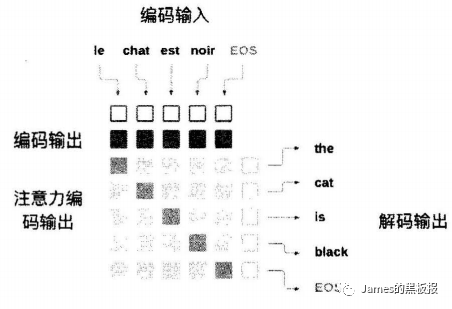
上图描述了,对于每个解码器的输出,都是由编码的输出和权重一起决定的,在上图的注意力输出中,颜色越深表示那个位置的权重越大,在解码的过程中,解码的过程每一步都会得到一个权重,权重的计算依赖于解码过程的输入和隐藏状态来计算,并不依赖于编码过程的输出,而编码过程的输出需要和权重结合起来得到结果,通过编码和解码这样组合就形成了注意力机制
论文介绍
这篇论文很少见的将seq2seq结构用在了时序预测上,作者提出了一种基于双阶段时间注意力机制的方法,简单来看也是融合了seq2seq+attention机制的影响,去掉了embedding层,论文中使用了股票数据集,室内温度数据两种数据集,其中规定了输入序列的形式
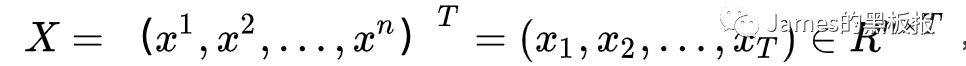
其中n为特征的维度,T代表时间步长,这里的T在论文中很重要,因为论文中的实验部分在每一轮epoch中设定的batch_size是128,也就是假设我们训练集的数据有1024条,那么每一轮送到网络中进行训练的数据规模是128条,迭代的次数iteration就是1024/128 = 8次,而在论文中,每次迭代需要送进网络的数据都是随机选择的
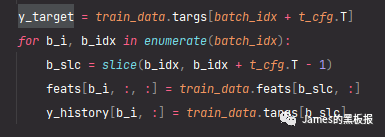
这部分代码意思就是对于每一次iteration中的batch_ids,y_target存储了当前id位置加上T时间步之后的位置上的结果列数据,feats和y_history代表了从当前id位置到加上T-1之后这段范围的特征列和结果列数据
对于输出序列,论文中给出描述如下
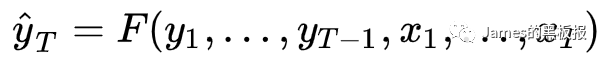 其中y1,y2…yt-1代表历史目标预测值,x1,x2…xt代表历史和当前的输入特征值,yt是我们预测的目标值
其中y1,y2…yt-1代表历史目标预测值,x1,x2…xt代表历史和当前的输入特征值,yt是我们预测的目标值
这个就是论文中模型的架构
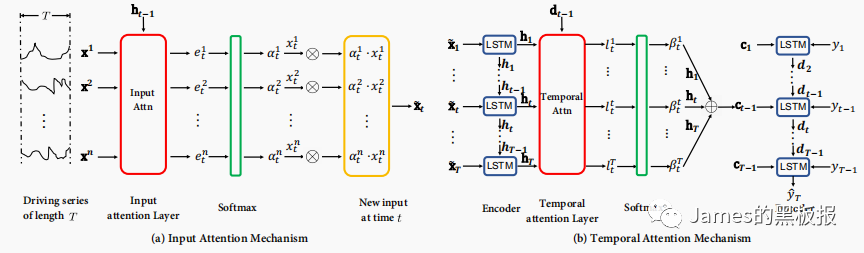
先来看第一个重要的函数
def preprocess_data(dat, col_names) -> Tuple[TrainData, StandardScaler]:
# 标准化
scale = StandardScaler().fit(dat)
proc_dat = scale.transform(dat)
# 生成同等列长的mask数组
mask = np.ones(proc_dat.shape[1], dtype=bool)
dat_cols = list(dat.columns)
for col_name in col_names:
mask[dat_cols.index(col_name)] = False
feats = proc_dat[:, mask]
targs = proc_dat[:, ~mask]
return TrainData(feats, targs), scale
这个函数是数据的预处理过程,dat代表读取出来的源数据集,col_names是用于预测的目标列,作者在代码中用一个mask数组标记了哪些列是用来预测的,所以也适用于多维度的输出,最后返回的对象TrainData中存储的是分别是训练集的特征数据和目标列数据
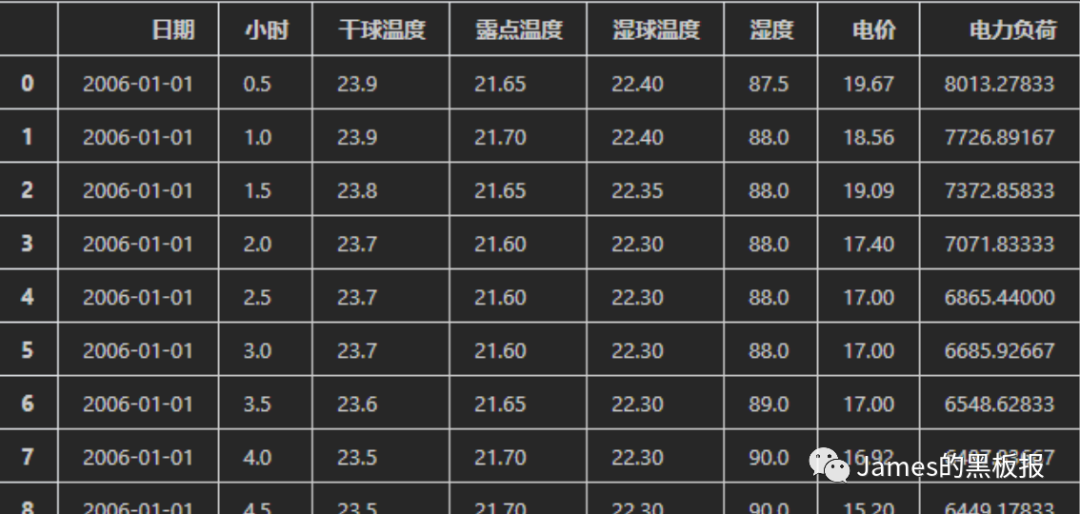 我在使用过程中用的数据集是某个国家的电力数据集,那我们的特征列就是干球温度,露点温度…电价这些,目标列就是电力负荷
我在使用过程中用的数据集是某个国家的电力数据集,那我们的特征列就是干球温度,露点温度…电价这些,目标列就是电力负荷
这篇论文最为重要的还是其网络结构的设计,接下来就是构建网络模型,前面说了,作者默认设置了128为每次epoch的采样数,T是一个超参,表示时间步长,论文中预设为10
da_rnn_kwargs = {"batch_size": 128, "T": 10}
config, model = da_rnn(data, n_targs=len(targ_cols), learning_rate=.001, **da_rnn_kwargs)
跳进da_rnn函数中可以看到整个网络初始化的步骤,可以看出作者定义了一个配置器,默认选取了训练集中前70%的数据作为训练集,损失函数用了mse,同时分别初始化encoder层和decoder层的网络结构,encoder层输入的是input_size,hidden_size,encoder_hidden_size,分别代表输入的特征维度,隐状态的特征维度,滑窗长度,注意decoder层传入的参数有一个输出特征的维度,在这里因为我们只是预测一列,所以长度为1,同时将配置文件写入到文件中,然后设置好网络的优化器和学习率,返回整个层
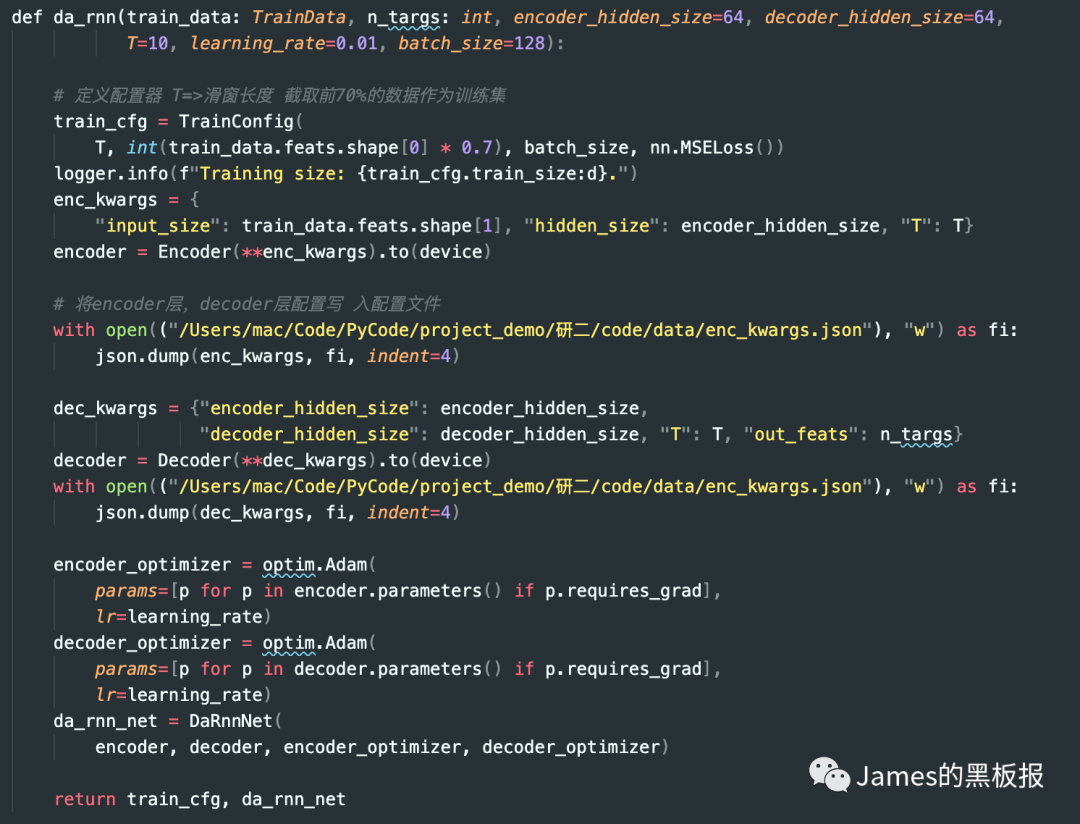
这篇论文最难的地方在于网络的前向传播过程,先来看下encoder层的设计,其实就是一个简单的LSTM网络加上一个注意力全连接层,在论文中给出的网络定义如下
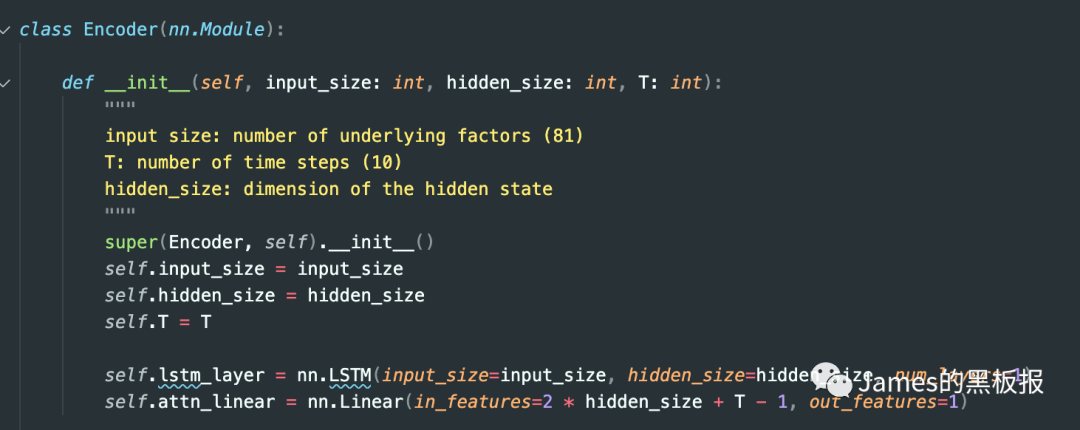
在这里,输入数据是一个特征维度为n,长度为T(时间步)的向量,首先会初始化注意力权重值和神经元的隐藏状态
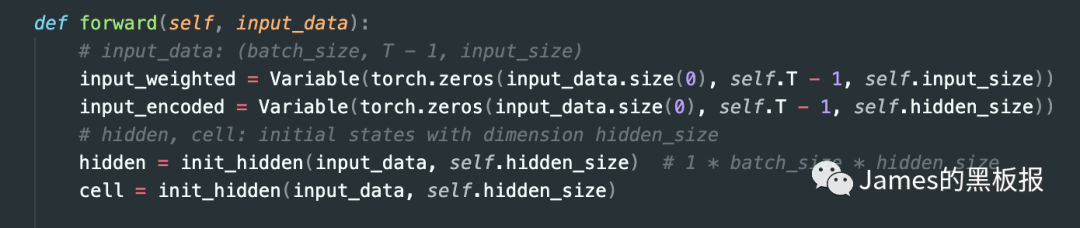 论文中使用了lstm作为记忆系统去更新隐状态的状态值ht,input_data是一个shape为(128,9,5)的tensor,128就是我们前面说的采样的个数bactch_size,9是时间步T-1,5是我们特征的维度,在这里需要将之前隐藏层的状态hidden和lstm单元的状态cell,还有input_data进行拼接一下,作为注意力层的输入,论文中给出了公式
论文中使用了lstm作为记忆系统去更新隐状态的状态值ht,input_data是一个shape为(128,9,5)的tensor,128就是我们前面说的采样的个数bactch_size,9是时间步T-1,5是我们特征的维度,在这里需要将之前隐藏层的状态hidden和lstm单元的状态cell,还有input_data进行拼接一下,作为注意力层的输入,论文中给出了公式
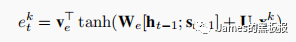
最后注意力层的输出会通过一个softmax层进行归一化,因为要保证所有的权重和为1,参见论文中的公式
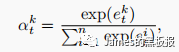
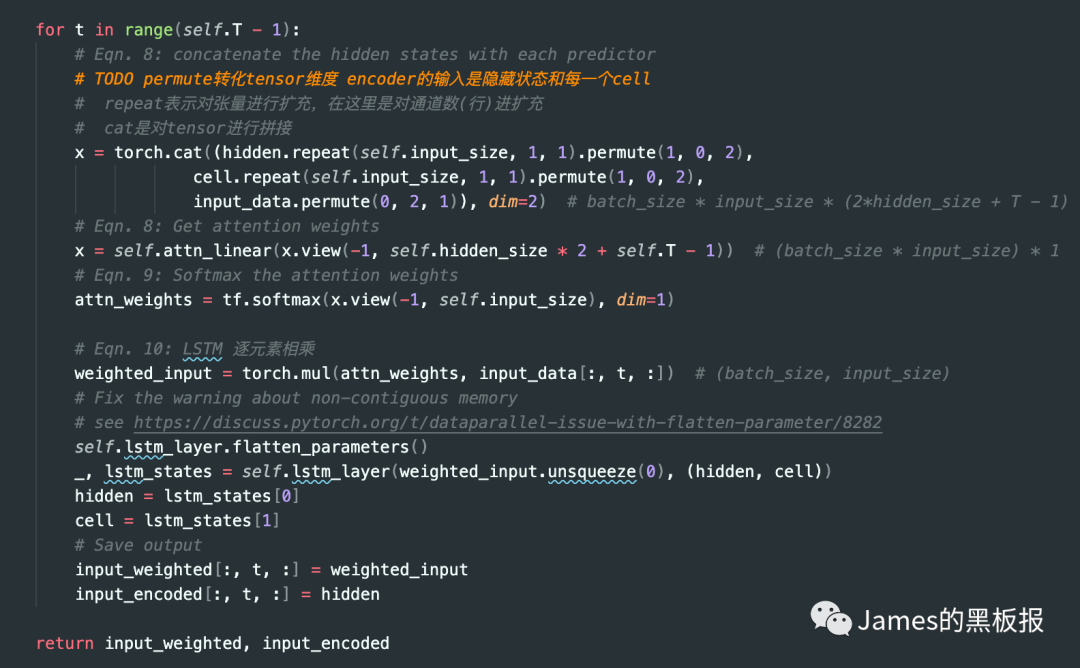
debug一下,可以看到这里的每一行的权重和都是1
在这里,每一次迭代后的weighted_input还是一个(128,5)维的tensor,通过这样循环,就可以不断更新hidden层的状态,直到达到时间步的长度,最后分别将(128,9,5)维度的input_weight和(128,9,64)维度的input_encoded返回即可
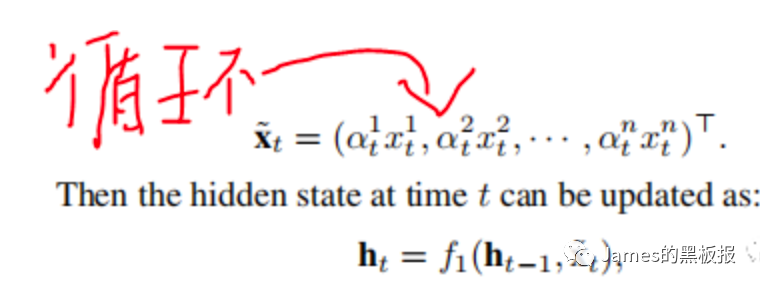
那现在我们就得到了内容向量,接下来将其输入到decoder层,decoder层就是进行预测了
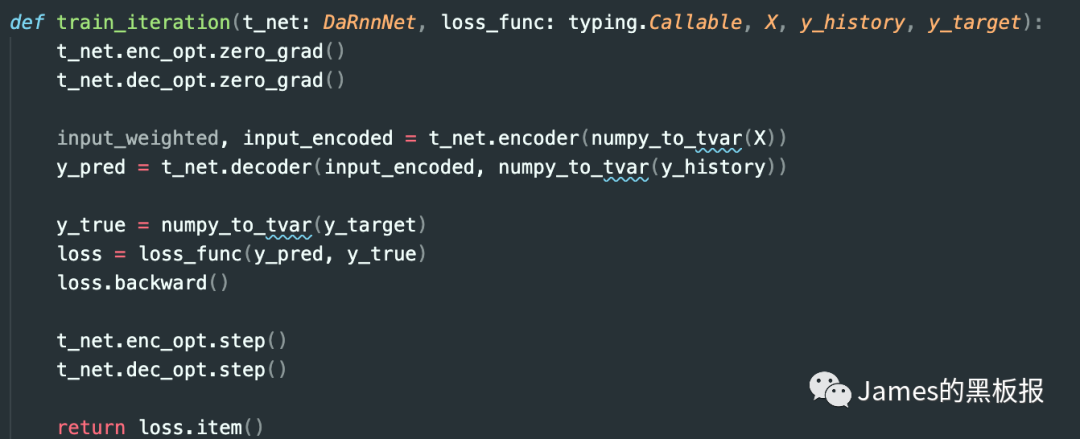
decoder层需要输入的是Xt和y_history,分别代表编码层中最后一步通过隐藏层输出的特征向量input_encoded(context)和y_history(历史预测值),来看下网络的架构
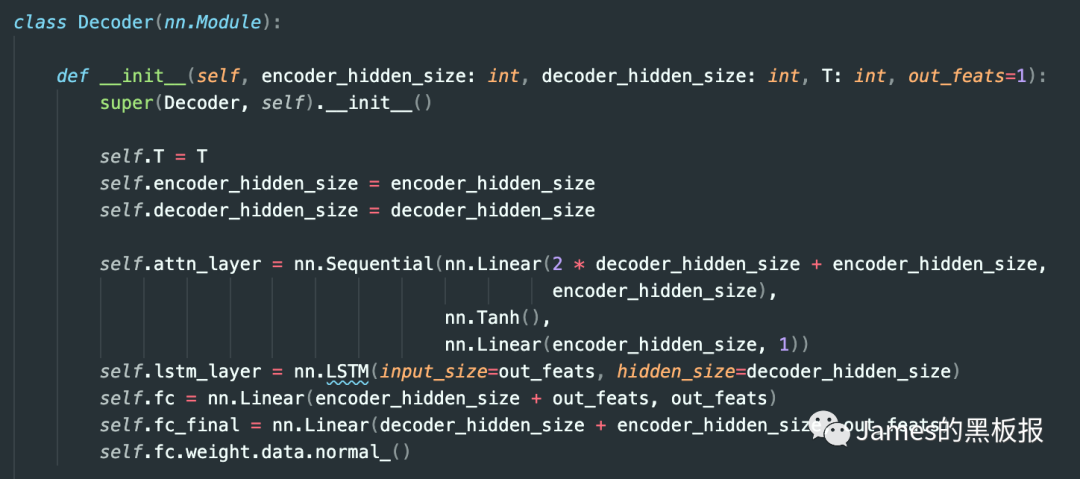
在这里分别传入了encoder隐藏层,decoder隐藏层的大小,时间步长,输出特征维度的长度,进入的第一层网络也是一个注意力层,论文中也解释了为什么这里要采取和encoder层一样的做法,在解码器同样使用一个注意力层,这样是为了防止当序列过长,也就是我们的时间步T过长时,而导致Encoder-Decoder结构的计算效率的大大降低,其实这也是RNN整个网络结构的弊端,太长的序列容易造成梯度爆炸,最后再经过一层lstm层和两层全连接层,就可以输出了,具体来看代码中给出的前向传播过程,这一步对应着下图的公式
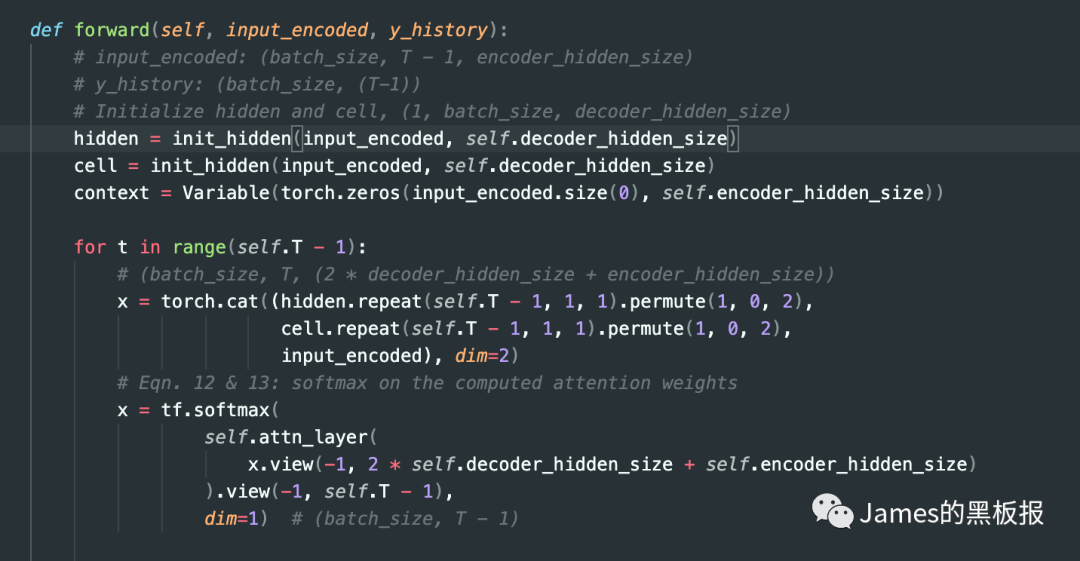
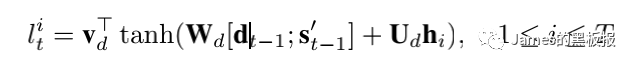
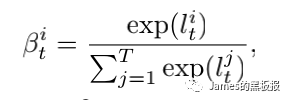
这一步与之前编码层基本一样,其中[dt-1,st-1]代表前一次的hidden状态值与lstm单元状态拼接起来的结果,这样再通过一个softmax层就可以计算出当前时间步的权重,接下来将归一化后的权重矩阵与input_encoded进行矩阵相乘,就可以得到更新后的context向量
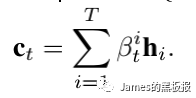

一旦得到更新后的context向量,就可以将这个向量与我们的历史序列[x1,x2,x3…xt-1],也就是y_history拼接起来,然后输入到一个LSTM层用来更新解码器的隐状态
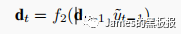
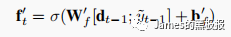 这一步计算比较复杂,其实和编码器的那部分差不多,最后通过建立以下方程,就可以得出估计出的预测值了
这一步计算比较复杂,其实和编码器的那部分差不多,最后通过建立以下方程,就可以得出估计出的预测值了
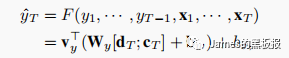
这一部分结束之后,就是模型训练了,作者在代码中的训练过程使用了一个学习率衰减的策略,保证训练后期模型收敛的稳定,最后设定了每10轮epoch保存一次结果图表,并且计算一次平均Loss,这一步就不说了
总结来说,这篇论文改进了seq2seq结构中的编码层,在lstm层之上加入一个基于时间步的注意力机制,提取的特征深度可能会更好,但是效果是否真的像论文中说的那么好,还需实验考证
论文地址:https://arxiv.org/pdf/1704.02971v4.pdf
最后
以上就是超帅月光最近收集整理的关于DARNN论文解读预备知识的全部内容,更多相关DARNN论文解读预备知识内容请搜索靠谱客的其他文章。





![[Machine Learning] 搭建神经网络(一层、二层和多层)](https://www.shuijiaxian.com/files_image/reation/bcimg22.png)


发表评论 取消回复