Day0
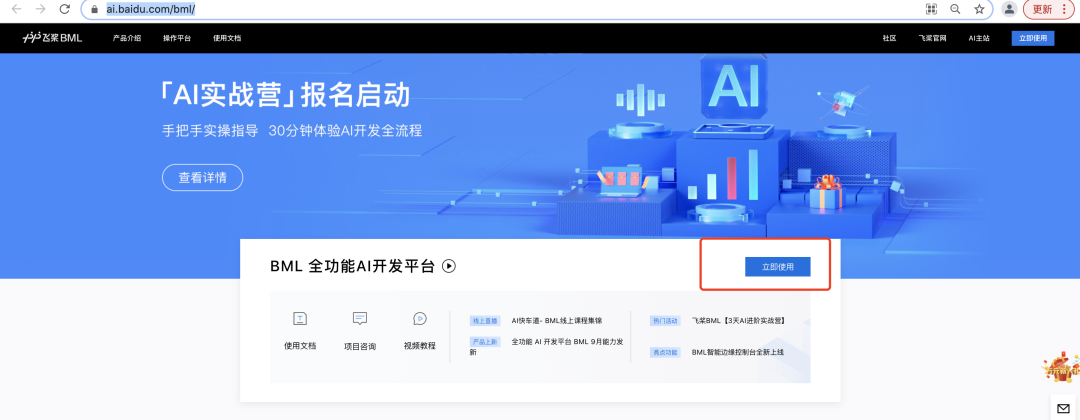
**step1:**进入BML主页,点击立即使用
????:https://ai.baidu.com/bml/
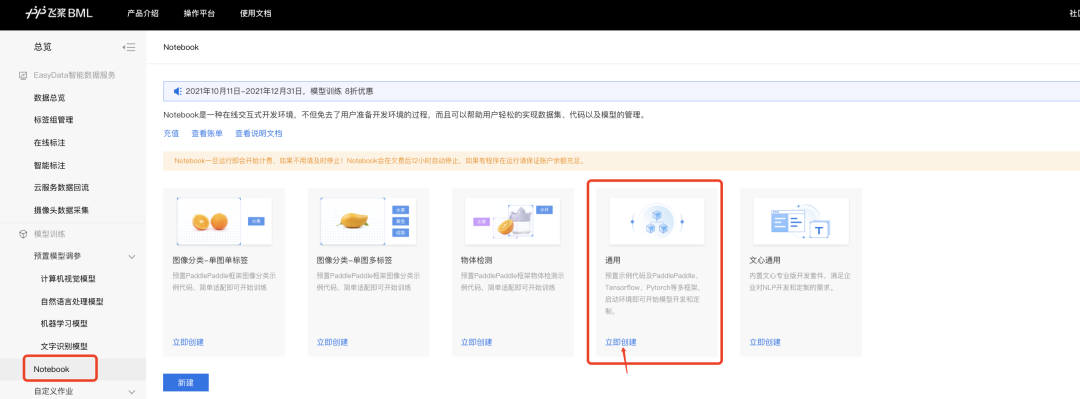
**step2:**点击Notebook,创建“通用任务”
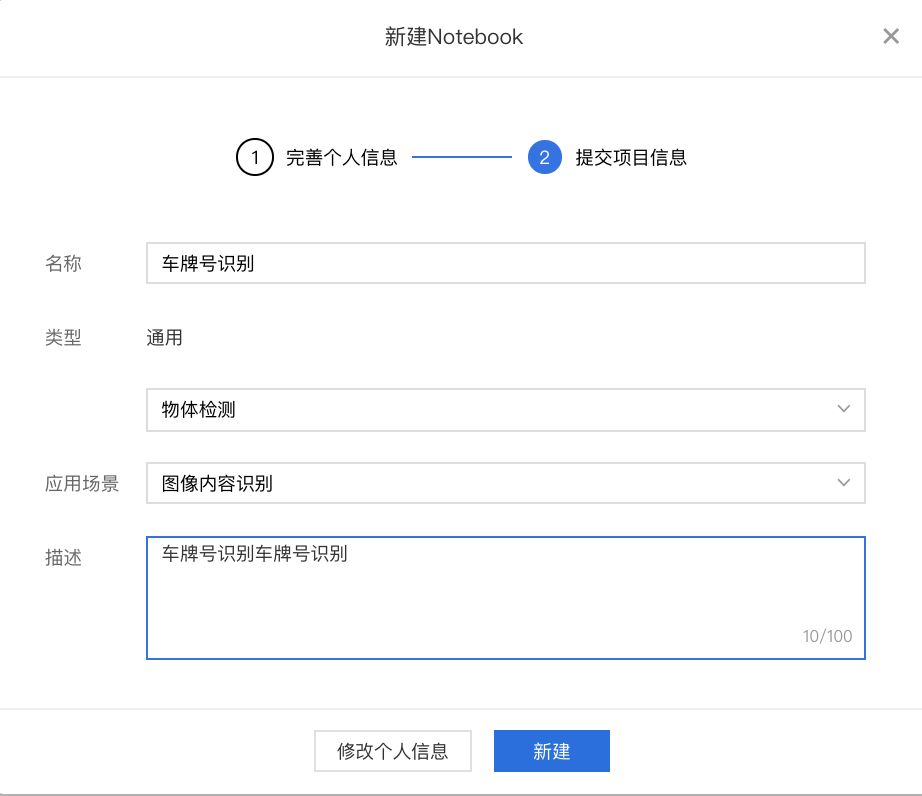
**step3:**填写任务信息
Day01
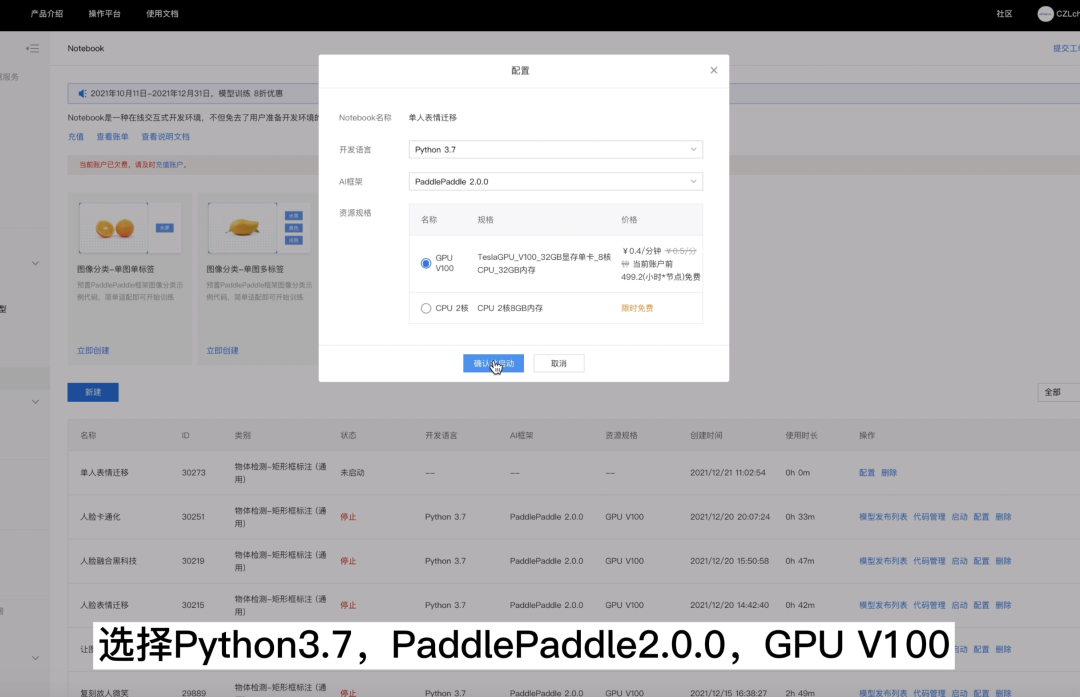
第一步:配置Notebook
1.找到昨天创建的Notebook任务,点击配置
- 开发语言:Python3.7
- AI框架:PaddlePaddle2.0.0
- 资源规格:GPU V100
 **
**
**
2.打开Notebook

3.创建一个Notebook,选择Python3
第二步:上传数据集至Notebook
1.下载数据集至本地
https://aistudio.baidu.com/aistudio/datasetdetail/123686
2.上传数据集至Notebook并解压
!unzip -q /home/work/chepaishibie.zip
3.生成标签文档
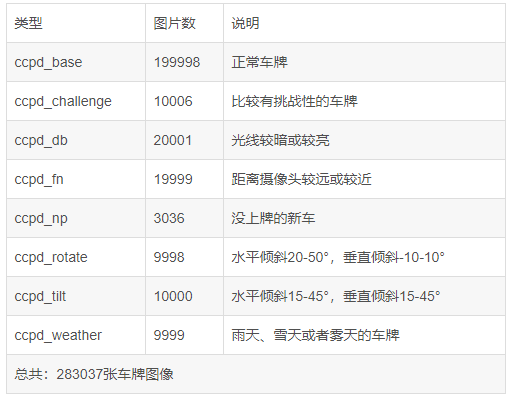
- 本次使用的数据集为CCPD2019车牌数据集
- 该数据集在合肥市的停车场采集得来,采集时间早上7:30到晚上10:00。停车场采集人员手持Android POS机对停车场的车辆拍照并手工标注车牌位置。拍摄的车牌照片涉及多种复杂环境,包括模糊、倾斜、阴雨天、雪天等等。CCPD数据集一共包含将近30万张图片,每种图片大小720x1160x3。一共包含8项,具体如下:
-
CCPD数据集没有专门的标注文件,每张图像的文件名就是对应的数据标注(label)
-
- 例如:025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg 由分隔符’-'分为几个部分:
-
- 025为区域
- 95_113 对应两个角度, 水平95°, 竖直113°
- 154&383_386&473对应边界框坐标:左上(154, 383), 右下(386, 473)
- 386&473_177&454_154&383_363&402对应四个角点坐标
- 0_0_22_27_27_33_16为车牌号码 映射关系如下: 第一个为省份0 对应省份字典皖, 后面的为字母和文字, 查看ads字典.如0为A, 22为Y…
-
仅使用到数据集中正常车牌即ccpd_base的数据
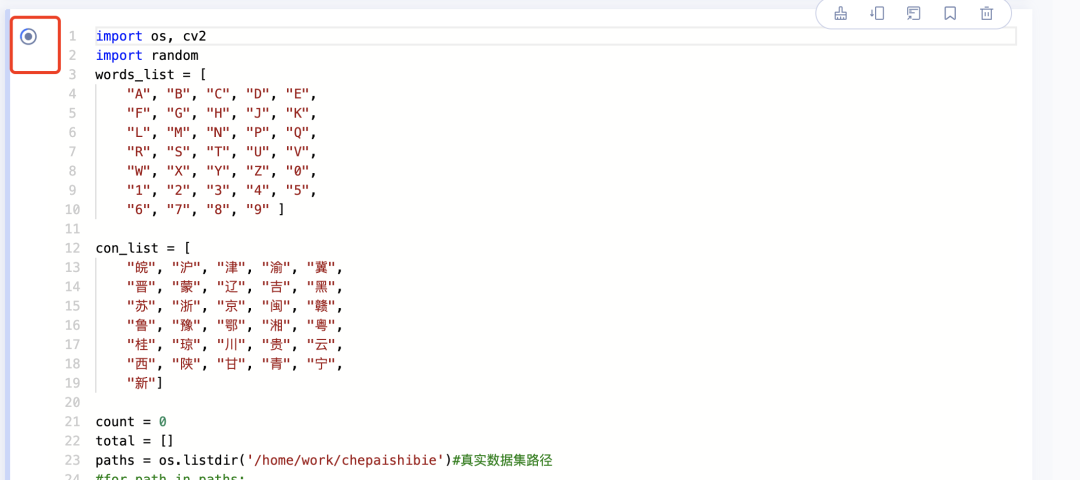
import os, cv2
import random
words_list = [
"A", "B", "C", "D", "E",
"F", "G", "H", "J", "K",
"L", "M", "N", "P", "Q",
"R", "S", "T", "U", "V",
"W", "X", "Y", "Z", "0",
"1", "2", "3", "4", "5",
"6", "7", "8", "9" ]
con_list = [
"皖", "沪", "津", "渝", "冀",
"晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣",
"鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云",
"西", "陕", "甘", "青", "宁",
"新"]
count = 0
total = []
paths = os.listdir('/home/work/chepaishibie')#真实数据集路径
#for path in paths:
for item in os.listdir(os.path.join('/home/work/chepaishibie')):#真实数据集路径
if item[-3:] =='jpg':
new_path = os.path.join('/home/work/chepaishibie', item) #训练图片路径的路径
_, _, bbox, points, label, _, _ = item.split('-')
points = points.split('_')
points = [_.split('&') for _ in points]
tmp = points[-2:]+points[:2]
points = []
for point in tmp:
points.append([int(_) for _ in point])
label = label.split('_')
con = con_list[int(label[0])]
words = [words_list[int(_)] for _ in label[1:]]
label = con+''.join(words)
line = new_path+'t'+'[{"transcription": "%s", "points": %s}]' % (' ', str(points))
line = line[:]+'n'
total.append(line)
random.shuffle(total)
with open('/home/work/data/train.txt', 'w', encoding='UTF-8') as f:
for line in total[:-200]:
f.write(line)
with open('/home/work/data/dev.txt', 'w', encoding='UTF-8') as f:
for line in total[-200:]:
f.write(line)
检查data下的两个txt文件

第三步:配置环境
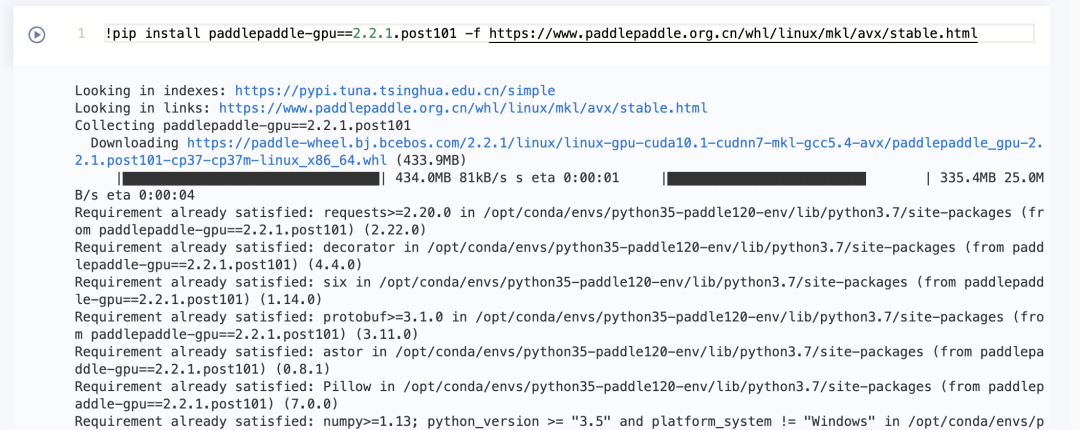
1.升级PaddlePaddle
!pip install paddlepaddle-gpu==2.2.1.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
2.下载PaddleOCR
!git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
3.下载预训练模型
cd /home/work/PaddleOCR
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ch_models/ch_det_mv3_db.tar!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/rec_mv3_tps_bilstm_attn.tar
cd pretrain_models
!tar -xf ch_det_mv3_db.tar && rm -rf ch_det_mv3_db.tar!tar -xf rec_mv3_tps_bilstm_attn.tar && rm -rf rec_mv3_tps_bilstm_attn.tar
第四步:保存Notebook并关闭、停止运行

Day02
第一步:重新安装环境
1.启动Notebook并打开
2.重新执行以下安装命令
第二步:安装PaddleOCR相关依赖文件
1.修改requirements文件
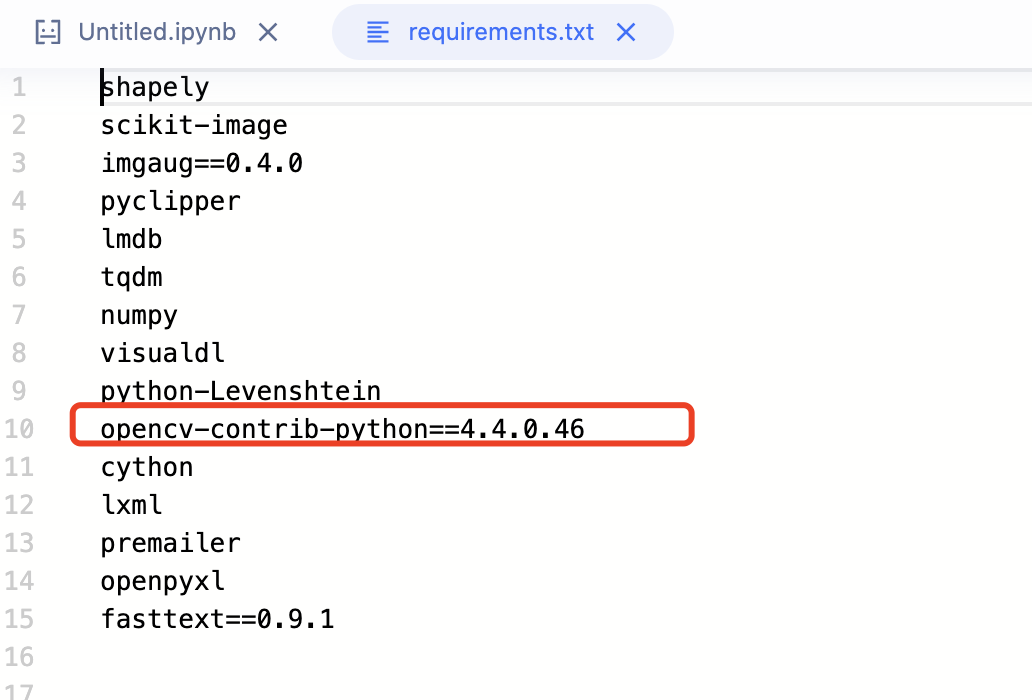
删除opencv-contrib-python==4.4.0.46
2.执行以下两个安装命令
cd /home/work/PaddleOCR
!pip install -r requirements.txt
!pip install opencv-contrib-python==4.2.0.32
第三步:修改模型训练的yml文件
进入路径PaddleOCR/configs/det/
打开det_mv3_db.yml
1.修改模型路径和保存路径
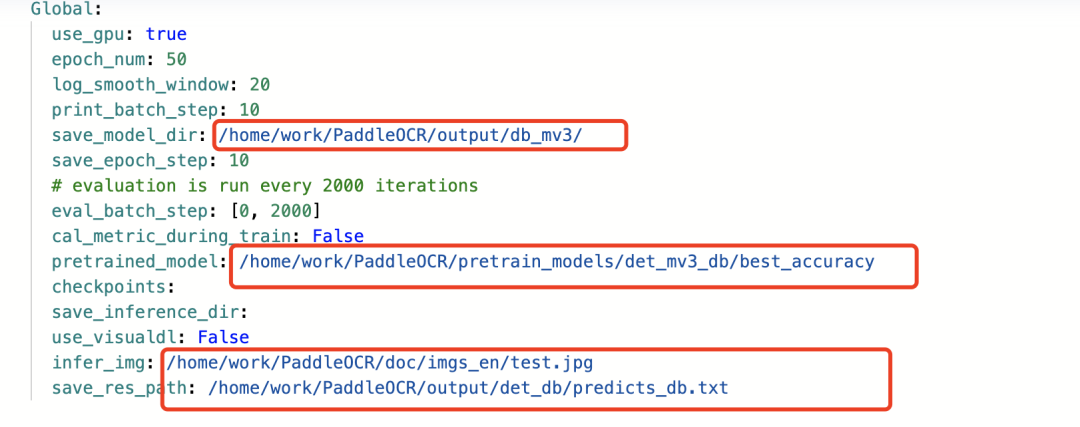
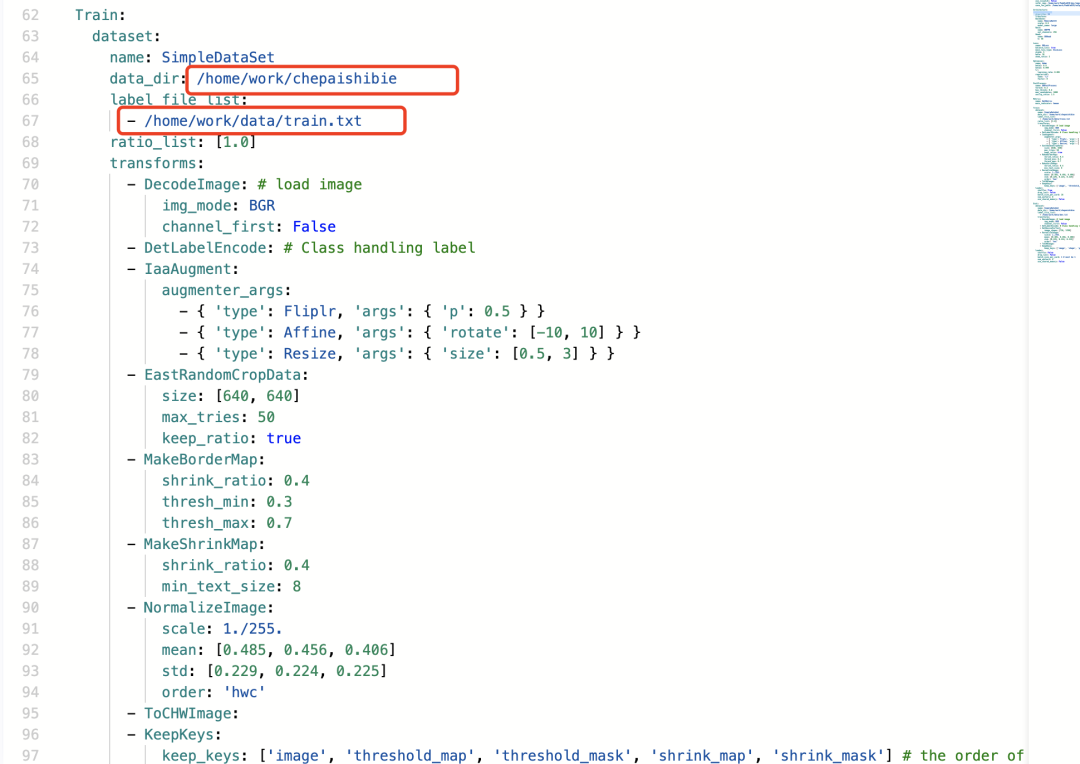
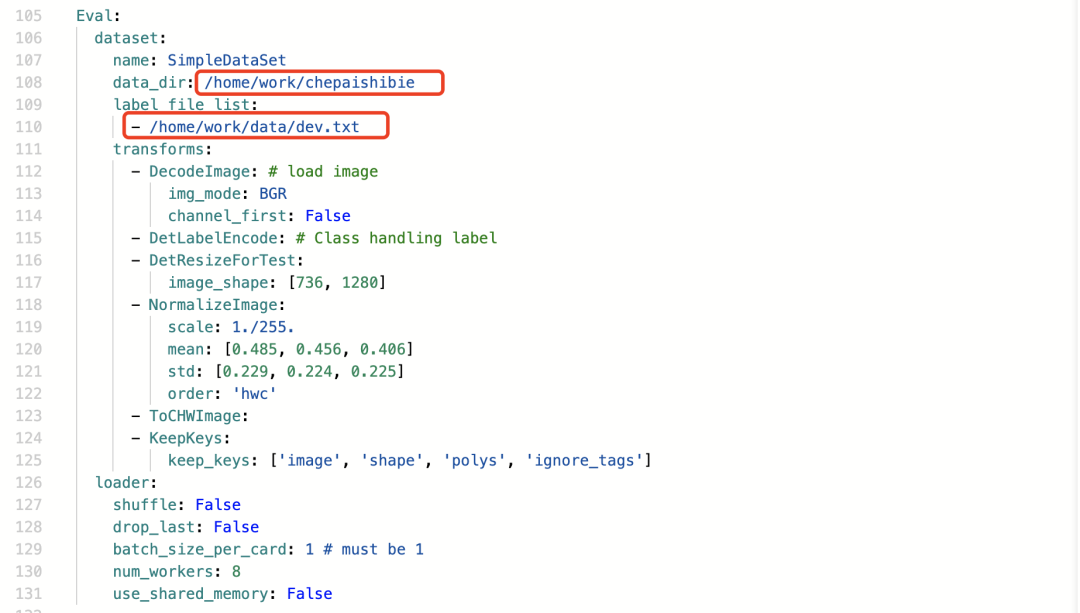
2.修改训练数据的路径
训练集:
验证集:
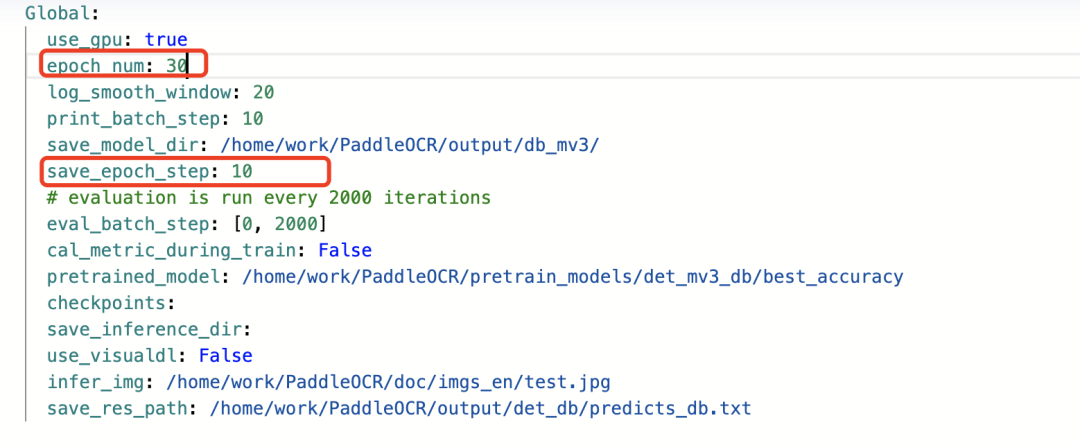
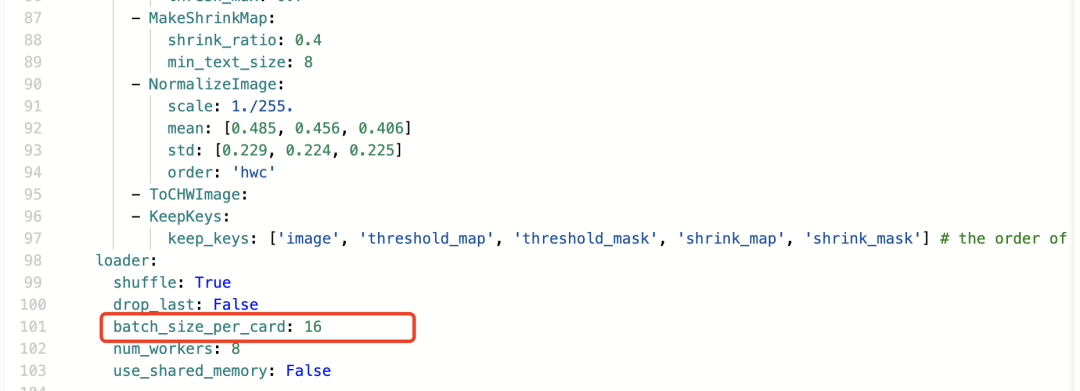
3.设置训练参数
epoch数:
batch_size:
第四步:模型训练
CUDA_VISIBLE_DEVICES=0!python3 tools/train.py -c configs/det/det_mv3_db.yml
第五步:保存Notebook并关闭、停止运行
Day03
第一步:重新安装环境
1.启动Notebook并打开
2.重新执行以下安装命令
升级PaddlePaddle

安装相关依赖


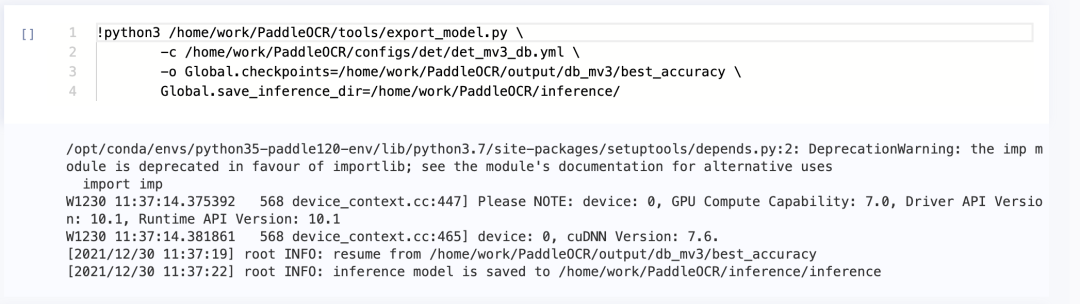
第二步:导出文字检测模型
!python3 /home/work/PaddleOCR/tools/export_model.py -c /home/work/PaddleOCR/configs/det/det_mv3_db.yml -o Global.checkpoints=/home/work/PaddleOCR/output/db_mv3/best_accuracy Global.save_inference_dir=/home/work/PaddleOCR/inference/
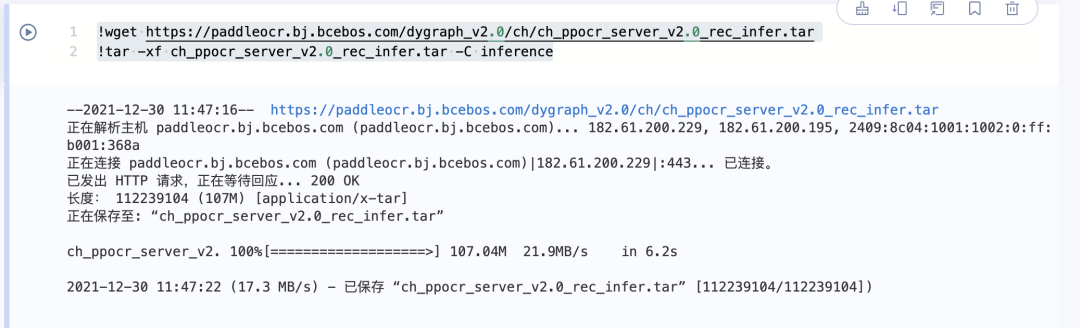
第三步:下载安装文字识别模型
!wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar!tar -xf ch_ppocr_server_v2.0_rec_infer.tar -C inference
第四步:模型预测
1.上传一张车牌图片作为预测图片

上传至home/work根目录,命名为test.jpg
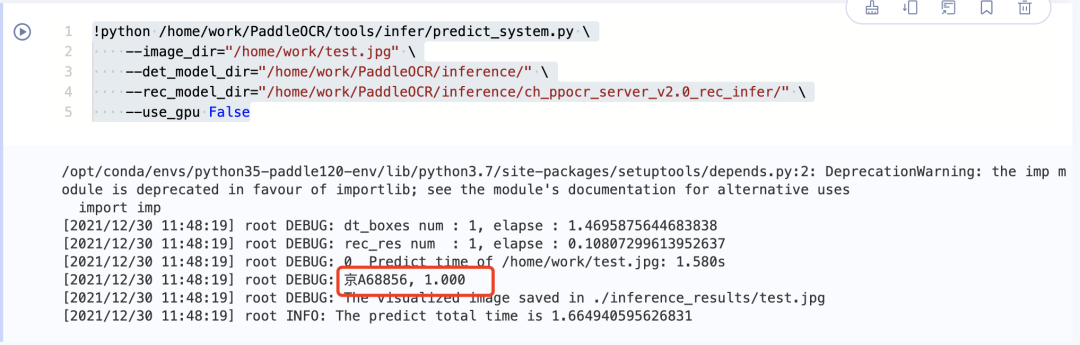
2.执行预测命令
!python /home/work/PaddleOCR/tools/infer/predict_system.py
--image_dir="/home/work/test.jpg" --det_model_dir="/home/work/PaddleOCR/inference/" --rec_model_dir="/home/work/PaddleOCR/inference/ch_ppocr_server_v2.0_rec_infer/" --use_gpu False
最后
以上就是眼睛大玫瑰最近收集整理的关于记录:百度3天AI进阶实战营——车牌识别Day0Day01Day02Day03的全部内容,更多相关记录内容请搜索靠谱客的其他文章。








发表评论 取消回复