tf.contrib.rnn.DropoutWrapper 和tf.contrib.rnn.BasicLSTMCell
tf.contrib.rnn.DropoutWrapper
__init__(
cell,
input_keep_prob=1.0,
output_keep_prob=1.0,
state_keep_prob=1.0,
variational_recurrent=False,
input_size=None,
dtype=None,
seed=None,
dropout_state_filter_visitor=None
)
创建一个带有添加的输入、状态和/或输出退出的单元格。
如果variational_recurrent设置为True (不默认行为),然后在每一步都应用相同的退出掩码,如下所述:
Y.Gal,Z Ghahramani.Dropout在递归神经网络中的理论基础应用。https://arxiv.org/abs/1512.05287
否则,在每一时间步骤中都会应用不同的退出掩码。
注意,默认情况下(除非有自定义)dropout_state_filter),则内存状态(c任何LSTMStateTuple)通过DropoutWrapper从未修改过。上述文章描述了这种行为。
args:
cell:一个RNNCell,将一个投影添加到Output_size中。input_keep_prob单位张量或浮动在0到1之间,输入保持概率;如果它是常数和1,则不会增加输入丢失。output_keep_prob单位张量或浮动在0到1之间,输出保持概率;如果它是常数和1,则不会增加输出丢失。state_keep_prob单位张量或浮动在0到1之间,输出保持概率;如果它是常数和1,则不会增加输出丢失。状态退出在单元格的传出状态上执行。注时,对其应用退出的状态组件。state_keep_prob在(0, 1)也是由论点决定的。dropout_state_filter_visitor(例如,默认情况下,从不对c成分LSTMStateTuple).variational_recurrent:Python bool。如果True,然后在每次运行调用的所有时间步骤中应用相同的退出模式。如果设置了此参数,input_size必提供。input_size:(可选)(可能是嵌套的元组)TensorShape对象,该对象包含预期传入的输入张量的深度。DropoutWrapper。所需和使用variational_recurrent = True和input_keep_prob < 1.dtype*(可选)dtype输入、状态和输出张量。所需和使用variational_recurrent = True.seed:(可选)整数,随机种子。-
dropout_state_filter_visitor*(可选),默认值:(见下文)。函数,该函数接受状态的任何层次,并返回PythonBooleans的标量或深度=1结构,描述应该删除状态中的哪些术语。此外,如果函数返回True,在这个子级别上应用了辍学。如果函数返回False,整个子级别都不应用辍学。
所谓dropout,就是指网络中每个单元在每次有数据流入时以一定的概率(keep prob)正常工作,否则输出0值。这是是一种有效的正则化方法,可以有效防止过拟合。在rnn中使用dropout的方法和cnn不同,推荐大家去把recurrent neural network regularization看一遍。
在rnn中进行dropout时,对于rnn的部分不进行dropout,也就是说从t-1时候的状态传递到t时刻进行计算时,这个中间不进行memory的dropout;仅在同一个t时刻中,多层cell之间传递信息的时候进行dropout,如下图所示
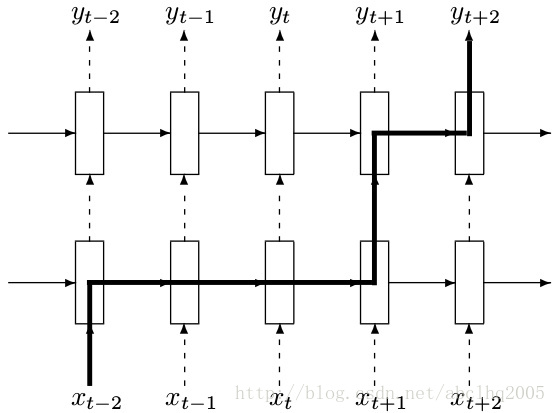
上图中,t-2时刻的输入xt−2首先传入第一层cell,这个过程有dropout,但是从t−2时刻的第一层cell传到t−1,t,t+1的第一层cell这个中间都不进行dropout。再从t+1时候的第一层cell向同一时刻内后续的cell传递时,这之间又有dropout了。
在使用tf.nn.rnn_cell.DropoutWrapper时,同样有一些参数,例如input_keep_prob,output_keep_prob等,分别控制输入和输出的dropout概率,很好理解。
可以从官方文档中看到,它有input_keep_prob和output_keep_prob,也就是说裹上这个DropoutWrapper之后,如果我希望是input传入这个cell时dropout掉一部分input信息的话,就设置input_keep_prob,那么传入到cell的就是部分input;如果我希望这个cell的output只部分作为下一层cell的input的话,就定义output_keep_prob。
备注:Dropout只能是层与层之间(输入层与LSTM1层、LSTM1层与LSTM2层)的Dropout;同一个层里面,T时刻与T+1时刻是不会Dropout的。
tf.contrib.rnn.BasicLSTMCell
__init__(
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None
)
参数说明:
num_units:int类型,LSTM单元中的神经元数量,即输出神经元数量
forget_bias:float类型,偏置增加了忘记门。从CudnnLSTM训练的检查点(checkpoin)恢复时,必须手动设置为0.0。
state_is_tuple:如果为True,则接受和返回的状态是c_state和m_state的2-tuple;如果为False,则他们沿着列轴连接。后一种即将被弃用。
activation:内部状态的激活函数。默认为tanh
reuse:布尔类型,描述是否在现有范围中重用变量。如果不为True,并且现有范围已经具有给定变量,则会引发错误。
name:String类型,层的名称。具有相同名称的层将共享权重,但为了避免错误,在这种情况下需要reuse=True.
dtype:该层默认的数据类型。默认值为None表示使用第一个输入的类型。在call之前build被调用则需要该参数。
import tensorflow as tf
output_dim=128
lstm=tf.nn.rnn_cell.BasicLSTMCell(output_dim)
batch_size=10 #批处理大小
timesteps=40 #时间步长
embedding_dim=300 #词向量维度
inputs=tf.Variable(tf.random_normal([batch_size,embedding_dim]))
previous_state = (tf.random_normal(shape=(batch_size, output_dim)), tf.random_normal(shape=(batch_size, output_dim)))
output,(new_h, new_state)=lstm(inputs,previous_state)
print(output.shape) #(10, 128)
print(new_h.shape) #(10, 128)
print(new_state.shape) #(10, 128)
tf.variable_scope和tf.name_scope()
tf.name_scope()和tf.variable_scope()是两个作用域,一般与两个创建/调用变量的函数tf.variable() 和tf.get_variable()搭配使用。它们搭配在一起的两个常见用途:1)变量共享,2)tensorboard画流程图时为了可视化封装变量,这两种用途有特定的搭配方式,掌握好就可以用了。如果您想打破砂锅问到底,想要探寻更多的知识,了解它们的用法和区别,本文中则阐述了更多的详情。
一. name_scope 和 variable_scope的用途
用途1: 共享变量
TensorFlow (TF) 中,name_scope 和 variable_scope 主要是因为 变量共享 的需求。为什么要共享变量?举个简单的例子:例如,当我们研究生成对抗网络GAN的时候,判别器的任务是如果接收到的是生成器生成的图像,判别器就尝试优化自己的网络结构来使自己输出0,如果接收到的是来自真实数据的图像,那么就尝试优化自己的网络结构来使自己输出1。也就是说,生成图像和真实图像经过判别器的时候,要共享同一套变量,所以TensorFlow引入了变量共享机制。
变量共享主要涉及两个函数:
tf.get_variable(<name>, <shape>, <initializer>)
tf.variable_scope(<scope_name>)
即就是必须要在tf.variable_scope的作用域下使用tf.get_variable()函数。这里用tf.get_variable( ) 而不用tf.Variable( ),是因为前者拥有一个变量检查机制,会检测已经存在的变量是否设置为共享变量,如果已经存在的变量没有设置为共享变量,TensorFlow 运行到第二个拥有相同名字的变量的时候,就会报错(详见本文的RNN应用例子章节)。
两个创建变量的方式。如果使用tf.Variable() 的话每次都会新建变量。但是大多数时候我们是希望重用一些变量,所以就用到了get_variable(),它会去搜索变量名,有就直接用,没有再新建。
名字域。既然用到变量名了,就涉及到了名字域的概念。通过不同的域来区别变量名,毕竟让我们给所有变量都取不同名字还是很辛苦。
这就是为什么会有scope 的概念。name_scope 作用于操作,variable_scope 可以通过设置reuse 标志以及初始化方式来影响域下的变量。
“共享变量” 的应用场景:RNN应用例子
在tf.variable_scope的作用域下,通过get_variable()使用已经创建的变量,实现了变量的共享。在 train RNN 和 test RNN 的时候, RNN 的 time_steps 会有不同的取值, 这将会影响到整个 RNN 的结构, 所以导致在 test 的时候, 不能单纯地使用 train 时建立的那个 RNN. 但是 train RNN 和 test RNN 又必须是有同样的 weights biases 的参数. 所以, 这时, 就是使用 reuse variable 的好时机.
例子:首先定义train 和 test 的不同参数.
class TrainConfig:
batch_size = 20
time_steps = 20
input_size = 10
output_size = 2
cell_size = 11
learning_rate = 0.01
class TestConfig(TrainConfig):
time_steps = 1
train_config = TrainConfig()
test_config = TestConfig()
然后让 train_rnn 和 test_rnn 在同一个 tf.variable_scope('rnn') 之下.
并且定义 scope.reuse_variables(), 使我们能把 train_rnn 的所有 weights, biases 参数全部绑定到 test_rnn 中.
这样, 不管两者的 time_steps 有多不同, 结构有多不同, train_rnn W, b 参数更新成什么样, test_rnn 的参数也更新成什么样.
with tf.variable_scope('rnn') as scope:
sess = tf.Session()
train_rnn = RNN(train_config)
scope.reuse_variables()
test_rnn = RNN(test_config)
sess.run(tf.global_variables_initializer())
RNN 例子的完整代码可以看这里.
因为想要达到变量共享的效果, 就要在 tf.variable_scope()的作用域下使用 tf.get_variable() 这种方式产生和提取变量. 不像 tf.Variable() 每次都会产生新的变量, tf.get_variable() 如果遇到了已经存在名字的变量时, 它会单纯的提取这个同样名字的变量,如果不存在名字的变量再创建.
但在重复使用的时候, 一定要在代码中强调 scope.reuse_variables(),如下面代码所示,否则系统将会报错, 以为你是不小心重复使用到了一个变量.
tf.stack
<span style="color:#37474f"><code>tf.stack(
values,
axis=<span style="color:#c53929">0</span>,
name=<span style="color:#0d904f">'stack'</span>
)
</code></span>定义于tensorflow/python/ops/array_ops.py。
将等级R张量列表堆叠成一个等级 - (R+1)张量。
将张量列表打包到values张量中values,其张力高于每个张量,通过将它们打包在axis维度上。给出一个N形状张量长度列表(A, B, C);
如果axis == 0那么output张量将具有形状(N, A, B, C)。如果axis == 1那么output张量将具有形状(A, N, B, C)。等等。
例如:
<span style="color:#37474f"><code>x = tf.constant([<span style="color:#c53929">1</span>, <span style="color:#c53929">4</span>])
y = tf.constant([<span style="color:#c53929">2</span>, <span style="color:#c53929">5</span>])
z = tf.constant([<span style="color:#c53929">3</span>, <span style="color:#c53929">6</span>])
tf.stack([x, y, z]) <span style="color:#d81b60"># [[1, 4], [2, 5], [3, 6]] (Pack along first dim.)</span>
tf.stack([x, y, z], axis=<span style="color:#c53929">1</span>) <span style="color:#d81b60"># [[1, 2, 3], [4, 5, 6]]</span>
</code></span>这与拆散相反。numpy等价物是
<span style="color:#37474f"><code>tf.stack([x, y, z]) = np.stack([x, y, z])
</code></span>
ARGS:
values:Tensor具有相同形状和类型的对象列表。axis:安int。轴堆叠起来。默认为第一个维度。负值环绕,因此有效范围是[-(R+1), R+1)。name:此操作的名称(可选)。
返回:
output:堆叠Tensor与...相同的类型values。
举:
ValueError:如果axis超出范围[ - (R + 1),R + 1)。
最后
以上就是背后发带最近收集整理的关于LSTM训练词向量:tf.contrib.rnn.DropoutWrapper和 tf.contrib.rnn.BasicLSTMCell、tf.variable_scope、tf.stack、tf.tf.contrib.rnn.DropoutWrapper 和tf.contrib.rnn.BasicLSTMCelltf.contrib.rnn.DropoutWrapper tf.variable_scope和tf.name_scope()tf.stack的全部内容,更多相关LSTM训练词向量:tf.contrib.rnn.DropoutWrapper和内容请搜索靠谱客的其他文章。








发表评论 取消回复