RNN中的梯度消失/爆炸原因
梯度消失/梯度爆炸是深度学习中老生常谈的话题,这篇博客主要是对RNN中的梯度消失/梯度爆炸原因进行公式层面上的直观理解。
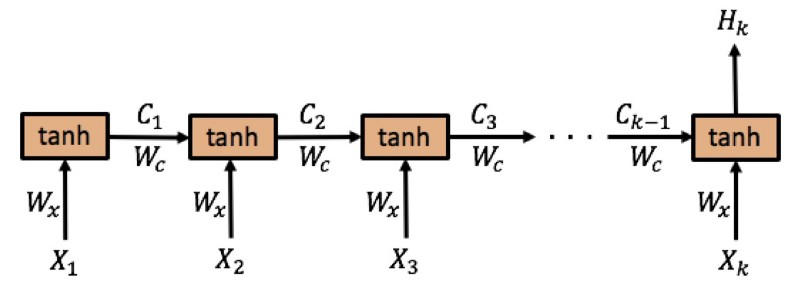
首先,上图是RNN的网络结构图, ( x 1 , x 2 , x 3 , … , ) (x_1, x_2, x_3, …, ) (x1,x2,x3,…,)是输入的序列, X t X_t Xt表示时间步为 t t t时的输入向量。假设我们总共有 k k k个时间步,用第 k k k个时间步的输出 H k H_k Hk作为输出(实际上每个时间步都有输出,这里仅考虑 H k H_k Hk),用 E k E_k Ek表示损失。
其中, C t = tanh ( W c C t − 1 + W x X t ) C_{t}=tanh left(W_{c} C_{t-1}+W_{x} X_{t}right) Ct=tanh(WcCt−1+WxXt)
从上式可以看出 W x W_x Wx和 W c W_c Wc其实是差不多的,记 W = [ W c , W x ] W=[W_c, W_x] W=[Wc,Wx],那么求偏导可以得到:
∂ E k ∂ W = ∂ E k ∂ H k ∂ H k ∂ C k ∂ C k ∂ C k − 1 … ∂ C 2 ∂ C 1 ∂ C 1 ∂ W = ∂ E k ∂ H k ∂ H k ∂ C k ( ∏ t = 2 k ∂ C t ∂ C t − 1 ) ∂ C 1 ∂ W begin{aligned} frac{partial E_{k}}{partial W}=& frac{partial E_{k}}{partial H_{k}} frac{partial H_{k}}{partial C_{k}} frac{partial C_{k}}{partial C_{k-1}} ldots frac{partial C_{2}}{partial C_{1}} frac{partial C_{1}}{partial W}=\ & frac{partial E_{k}}{partial H_{k}} frac{partial H_{k}}{partial C_{k}}left(prod_{t=2}^{k} frac{partial C_{t}}{partial C_{t-1}}right) frac{partial C_{1}}{partial W} end{aligned} ∂W∂Ek=∂Hk∂Ek∂Ck∂Hk∂Ck−1∂Ck…∂C1∂C2∂W∂C1=∂Hk∂Ek∂Ck∂Hk(t=2∏k∂Ct−1∂Ct)∂W∂C1
其中的累乘部分为:
∂ C t ∂ c t − 1 = tanh ′ ( W c C t − 1 + W x X t ) ⋅ d d C t − 1 [ W c C t − 1 + W x X t ] = tanh ′ ( W c C t − 1 + W x X t ) ⋅ W c begin{aligned} frac{partial C_{t}}{partial c_{t-1}}=& tanh ^{prime}left(W_{c} C_{t-1}+W_{x} X_{t}right) cdot frac{d}{d C_{t-1}}left[W_{c} C_{t-1}+W_{x} X_{t}right]=\ & tanh ^{prime}left(W_{c} C_{t-1}+W_{x} X_{t}right) cdot W_{c} end{aligned} ∂ct−1∂Ct=tanh′(WcCt−1+WxXt)⋅dCt−1d[WcCt−1+WxXt]=tanh′(WcCt−1+WxXt)⋅Wc
将该式代入上式有:
∂ E k ∂ W = ∂ E k ∂ H k ∂ H k ∂ C k ( ∏ t = 2 k tanh ′ ( W c C t − 1 + W x X t ) ⋅ W c ) ∂ c 1 ∂ W frac{partial E_{k}}{partial W}=frac{partial E_{k}}{partial H_{k}} frac{partial H_{k}}{partial C_{k}}left(prod_{t=2}^{k} tanh ^{prime}left(W_{c} C_{t-1}+W_{x} X_{t}right) cdot W_{c}right) frac{partial c_{1}}{partial W} ∂W∂Ek=∂Hk∂Ek∂Ck∂Hk(∏t=2ktanh′(WcCt−1+WxXt)⋅Wc)∂W∂c1
观察这个式子,和上篇文章中一样,因为链式法则,出现了累乘项,因为tanh的导数 <= 1,所以,当k很大的时候,上式的值是趋向于0的。(<1的数多次相乘),也就是:
Π t = 2 k tanh ′ ( W c C t − 1 + w x X t ) ⋅ W c → 0 , Pi_{t=2}^{k} tanh ^{prime}left(W_{c} C_{t-1}+w_{x} X_{t}right) cdot W_{c} rightarrow 0, Πt=2ktanh′(WcCt−1+wxXt)⋅Wc→0, so ∂ E k ∂ W → 0 frac{partial E_{k}}{partial W} rightarrow 0 ∂W∂Ek→0
此时,权重更新公式:
W ← W − α ∂ E k ∂ W ≈ W W leftarrow W-alpha frac{partial E_{k}}{partial W} approx W W←W−α∂W∂Ek≈W
也就是说,RNN很容易出现梯度消失现象,使得参数更新缓慢,甚至是停止更新。
最后
以上就是老迟到云朵最近收集整理的关于RNN中的梯度消失/爆炸原因的全部内容,更多相关RNN中内容请搜索靠谱客的其他文章。








发表评论 取消回复