本文PDF文件下载地址:http://download.csdn.net/download/qq_36330643/9938438
Tensorflow的数据读取有三种方式:
1. Preloaded data: 预加载数据 。
2. Feeding: Python产生数据,再把数据喂给后端。
3. Reading from file: 从文件中直接读取。
这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的。
TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活。而Python恰好相反,所以结合两种语言的优势。涉及计算的核心算子和运行框架是用C++写的,并提供API给Python。Python调用这些API,设计训练模型(Graph),再将设计好的Graph给后端去执行。简而言之,Python的角色是Design,C++是Run。
1. Preload
import tensorflow as tf
a = tf.constant(5, name="input_a")
b = tf.constant(3, name="input_b")
sess = tf.Session()
sess.run(a)
c = tf.multiply(a,b, name="mul_c")
d = tf.add(a,b, name="add_d")
print(c)
e = tf.add(c,d, name="add_e")
print(e)
sess = tf.Session()
output = sess.run(e)
print(a)
print(output)
sess.close()
2. Feeding
import tensorflow as tf
import numpy as np
a = tf.placeholder(tf.int32,shape=[2],name="my_input")
b = tf.reduce_prod(a,name="prod_b")
c = tf.reduce_sum(a,name="sum_c")
d = tf.add(b,c,name="add-d")
sess = tf.Session()
input_dict = {a:np.array([5,3],dtype=np.int32)}
output = sess.run(d,feed_dict=input_dict)
print(output)
sess.run()中的feed_dict参数,将Python产生的数据喂给后端,并计算output。
以上两种方法的区别 Preload: 将数据直接内嵌到Graph中,再把Graph传入Session中运行。当数据量比较大时,Graph的传输会遇到效率问题。 Feeding: 用占位符替代数据,待运行的时候填充数据。
3. Reading From File
前两种方法很方便,但是遇到大型数据的时候就会很吃力,即使是Feeding,中间环节的增加也是不小的开销,比如数据类型转换等等。最优的方案就是在Graph定义好文件读取的方法,让TF自己去从文件中读取数据,并解码成可使用的样本集。
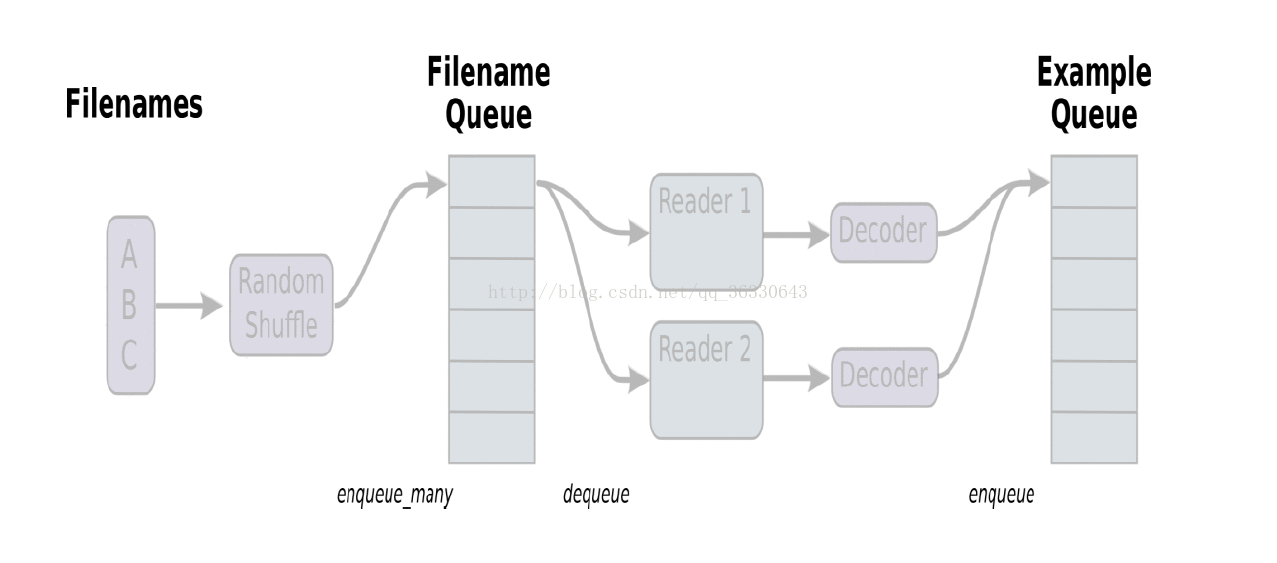
在上图中,首先由一个单线程把文件名堆入队列,两个Reader同时从队列中取文件名并读取数据,Decoder将读出的数据解码后堆入样本队列,最后单个或批量取出样本(图中没有展示样本出列)。我们这里通过三段代码逐步实现上图的数据流,这里我们不使用随机,让结果更清晰。
下面部分由于敲字慢,全部采用图片了。










最后
以上就是闪闪背包最近收集整理的关于TensorFlow学习笔记(二十二) tensorflow数据读取方法总结的全部内容,更多相关TensorFlow学习笔记(二十二)内容请搜索靠谱客的其他文章。








发表评论 取消回复