1.数据获取
数据来源于ECMWF,格式为NETCDF气象数据文件,数据是一个[时间×经度×纬度]的三维矩阵,用以下代码来读取:
dataset = nc.Dataset("data/%d/%d.nc")#文件路径
longitude_nc = dataset.variables["longitude"]
latitude_nc = dataset.variables["latitude"]
time_nc = dataset.variables["time"]
u10_nc = np.array(dataset.variables["u10"])
v10_nc = np.array(dataset.variables["v10"])
v_abs = (v10_nc ** 2 + u10_nc ** 2) ** 0.5#nc文件里的速度数据是分x,y两个方向的,所以取平方和再开根号才是该点的速度计算出最大风速,最小风速和平均风速,保存为csv文件,将1989-2017年的数据作为训练集,2018年的数据作为测试集,在pycharm里面查看一下:
,year,month,day,speed,max,average,min
0,2018,1,1,7.720214893,12.39827865,6.534754546,1.157438587
1,2018,1,2,6.534754546,9.633524721,5.555451098,1.077857595
2,2018,1,3,5.555451098,12.66565301,7.490290528,1.196667866
3,2018,1,4,7.490290528,10.01959622,5.52125861,0.147818598
4,2018,1,5,5.52125861,13.52008618,7.958868339,1.018520705
5,2018,1,6,7.958868339,12.08335956,5.725355559,0.339679507
6,2018,1,7,5.725355559,12.62008588,6.355550614,0.088038696
7,2018,1,8,6.355550614,15.61926933,9.871182364,0.361438214
8,2018,1,9,9.871182364,12.8674265,8.089844966,1.308905928这里的speed是前一天的平均风速,希望能和年,月,日一起作为特征进行预测。
2.数据读取与处理
读取数据,因为第一行都是标签,所以去掉,并且把features和labels分开:
train_data = pd.read_csv('data_train.csv')
test_data = pd.read_csv('data_test.csv')
input_features = train_data.loc[1:,['year','month','day','speed']]
input_features = np.array(input_features)#csv里的数据读取出来是dataframe格式,最好先转化成矩阵的形式方便后面处理
test_labels = test_data.loc[1:,['max','average','min']]
labels = train_data.loc[1:,['max','average','min']]
labels = np.array(labels)打印一下训练集数据和训练集的input_features和labels看看:
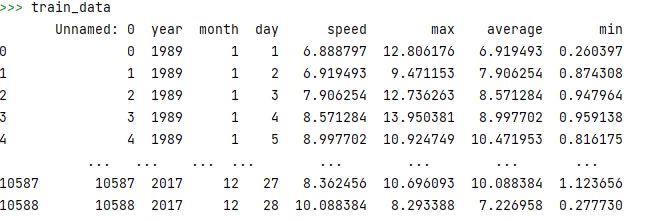


那么问题来了,观察input_features可以发现,第一个特征也就是year的数值比另外三个大很多,这样会导致后面的预测结果和其它三个特征的关系不大,所以我们要对特征进行归一化处理,这里用的是sklearn里面的preprocessing函数:
input_features_1 = preprocessing.StandardScaler().fit_transform(input_features)归一化后的数据如下:

3.神经网络
接下来开始神经网络的搭建,这里使用一个包含两层隐藏层的线性回归模型,神经网络图如下:
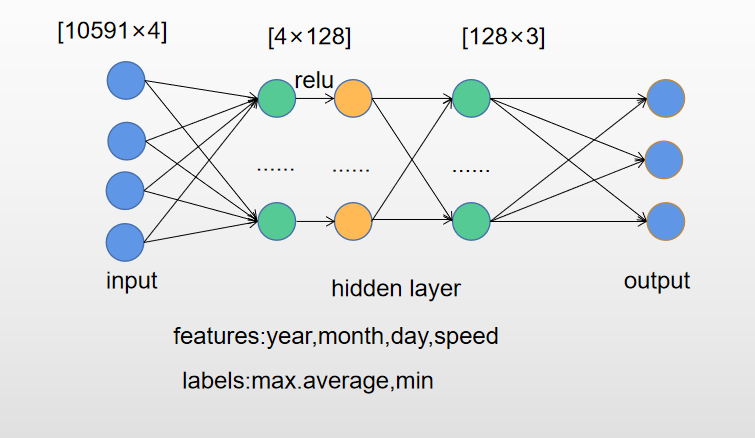
my_nn = torch.nn.Sequential(torch.nn.BatchNorm1d(7),torch.nn.Linear(input_size,hidden_size),torch.nn.ReLU(),torch.nn.Dropout()
,torch.nn.BatchNorm1d(hidden_size),torch.nn.Linear(hidden_size,output_size))
另一种写法
class my_module(nn.Module):
def __init__(self):
super(my_module,self).__init__()
self.bn = nn.BatchNorm1d(4)
self.linear1 = nn.Linear(4,128)
self.RELU = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.linear2 = nn.Linear(128,3)
def forward(self,x):
x1 = self.bn(x)
x2 = self.linear1(x1)
x3 = self.RELU(x2)
x4 = self.dropout(x3)
x5 = self.linear2(x4)
return x5使用mse误差和adam优化
cost = torch.nn.MSELoss(reduction='mean')#mse误差
optimizer = torch.optim.Adam(my_nn.parameters(),lr = 1e-2,weight_decay=0.1)#Adam优化器开始训练
losses = []
for i in range(1000):
batch_loss = []
for start in range(0,len(x),batch_size):
end = start + batch_size if start + batch_size < len(x) else len(x)
xx = torch.tensor(x[start:end],dtype=float,requires_grad=True)
xx = xx.to(torch.float32)
yy = torch.tensor(y[start:end],dtype=float,requires_grad=True)
yy = yy.to(torch.float32)
prediction = my_nn(xx)
loss = cost(prediction,yy)
optimizer.zero_grad()#清零
loss.backward(retain_graph = True)#反向传播
optimizer.step()
batch_loss.append(loss.data.numpy())
losses.append(np.mean(batch_loss))
if i % 100 == 0:#每一百步输出一次loss
test_losses =cost(my_nn(x1),test_labels)
print(i,np.mean(batch_loss),test_losses)
预测
'预测'
preds = my_nn(x1).data.numpy()
preds_tensor = torch.tensor(preds,dtype=float)
#lss = cost(preds_tensor,test_labels)
print('prediction',preds)
#print('test loss:',lss)
'预测数据保存'
df = pd.DataFrame()
df['max'] = preds[:,0]
df['average'] = preds[:,1]
df['min'] = preds[:,2]
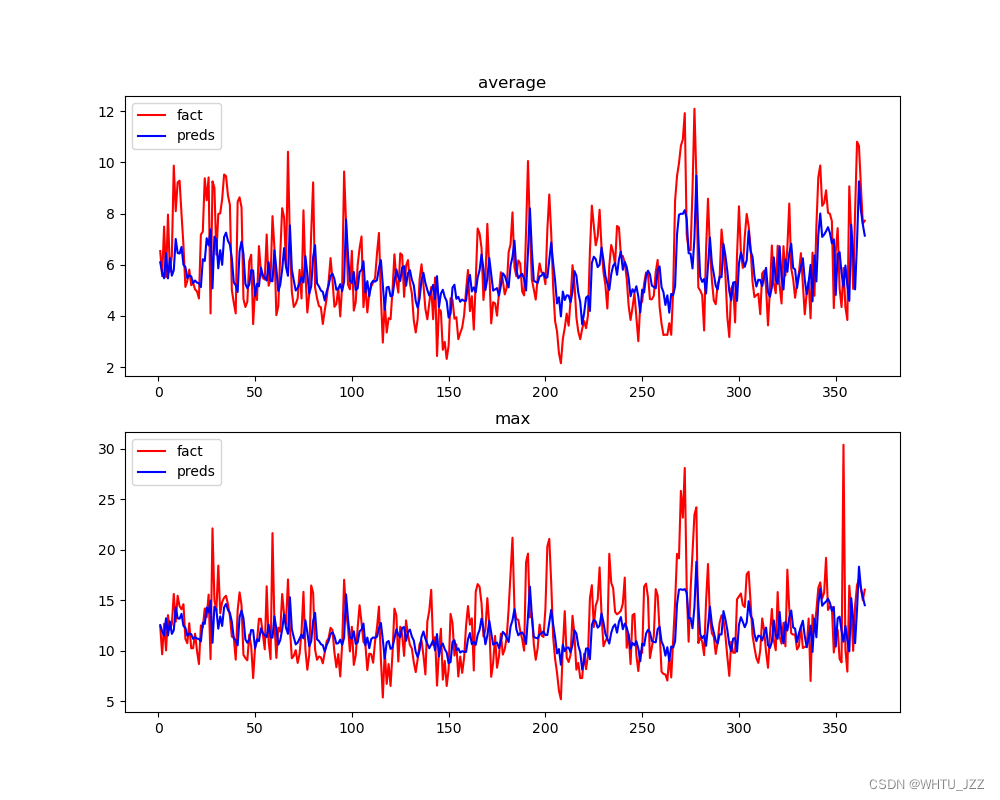
df.to_csv('bp.csv')结果对比
最后
以上就是糟糕羽毛最近收集整理的关于pytorch——线性回归——风速预测2.数据读取与处理 3.神经网络的全部内容,更多相关pytorch——线性回归——风速预测2内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复