1、Batch Normalization概念
Batch Normalization:批标准化
批: 一批数据,通常为mini-batch
标准化: 0均值,1方差
优点:
- 可以用更大学习率,加速模型收敛;
- 可以不用精心设计权值初始化;
- 可以不用dropout或较小的dropout;
- 可以不用L2或者较小的weight decay;
- 可以不用LRN(local response normalization局部响应值的标准化)
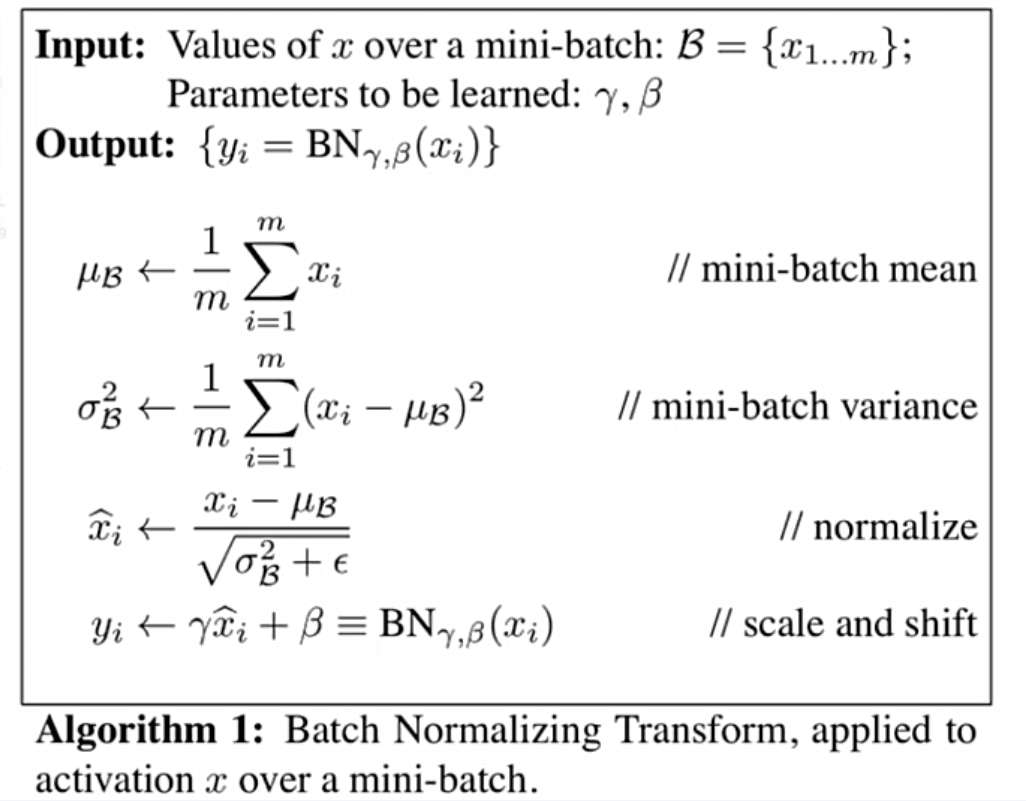
上面伪代码中最后一部分是affine transfrom,也就是scale and shift,公式中的gamma和beta是可学习参数,可以根据loss反向传播更新参数。
为什么在进行normalize更新之后要加一个affine transform呢?这一步可以增强模型的容纳能力,使模型更灵活,选择性更多,可以让模型判断是否需要对模型进行变换。
这个方法是在论文《Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift》提出的,主要是为了解决ICS问题(Internal Covariate Shift数据尺度变化)。
2、Pytorch的Batch Normalization 1d/2d/3d实现
Pytorch中nn.Batchnorm1d、nn.Batchnorm2d、nn.Batchnorm3d都继承于基类_Batchnorm;
2.1 _BatchNorm
_BatchNorm的主要参数:
- num_features:一个样本特征数量(最重要);
- eps:分母修正项,避免分母为零;
- momentum:指数加权平均估计当前mean/var;
- affine:布尔变量,是否需要affine transform;
- track_running_stats:训练状态还是测试状态;如果是训练状态,mean/var需要不断计算更新;如果在测试状态,mean/var是固定的;
def __init__(self,num_features,eps=1e-5,momentum=0.1,affine=True,track_running_stats=True)
2.2 nn.BatchNorm1d/nn.BatchNorm2d/nn.NatchNorm3d
nn.BatchNorm1d/nn.BatchNorm2d/nn.NatchNorm3d的主要属性:
- running_mean:均值;
- running_var:方差;
- weight:affine transform中的gamma;
- bias:affine transform中的beta;
BN的公式: x ^ i ← x i − μ B σ B 2 + ϵ widehat{x}_{i} leftarrow frac{x_{i}-mu_{mathcal{B}}}{sqrt{sigma_{mathcal{B}}^{2}+epsilon}} x i←σB2+ϵxi−μB y i ← γ x ^ i + β ≡ B N γ , β ( x i ) y_{i} leftarrow gamma widehat{x}_{i}+beta equiv mathrm{B} mathrm{N}_{gamma, beta}left(x_{i}right) yi←γx i+β≡BNγ,β(xi)
BN中的均值和方差在训练的时候采用指数加权平均进行计算,在测试时使用当前统计值: r u n n i n g m e a n = ( 1 − m o m e n t u m ) ∗ p r e _ r u n n i n g _ m e a n + m o m e n t u m ∗ m e a n _ t running_mean = (1-momentum) * pre_{_}running_{_}mean + momentum * mean_{_}t runningmean=(1−momentum)∗pre_running_mean+momentum∗mean_t r u n n i n g _ = ( 1 − m o m e n t u m ) ∗ p r e _ r u n n i n g _ v a r + m o m e n t u m ∗ v a r _ t running_{_}=(1-momentum)*pre_{_}running_{_}var+momentum*var_{_}t running_=(1−momentum)∗pre_running_var+momentum∗var_t
2.3 nn.BatchNorm1d/nn.BatchNorm2d/nn.NatchNorm3d对数据的要求
- nn.BatchNorm1d input = Batch_size * 特征数 * 1d特征维度
- nn.BatchNorm2d input = Batch_size * 特征数 * 2d特征维度
- nn.BatchNorm3d input = Batch_size * 特征数 * 3d特征维度
2.3.1 nn.BatchNorm1d
在全连接层使用的就是nn.BatchNorm1d,全连接层中的每一个神经元就是一个特征,假设一个网络层有五个特征,也就是一个网络层有五个神经元,如下图中的每一列是一个数据,每个数据有5个特征作为网络层的输入,每一个特征的维度是红色圆圈圈出的部分,维度为1,这样就构成了一个样本的一个特征。
每次训练数据组成一个batch,假设一个batch有三个样本,这样的三个样本组成的batch就构成了nn.BatchNorm1d的输入数据形式,输入数据的形式为[3,5,1],有时候1可以忽略,因此可以表示为[3,5];
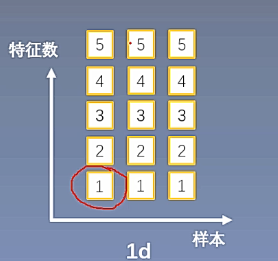
我们知道,nn.BatchNorm1d有四个参数需要计算,这四个参数需要在特征维度上进行计算,如上图,现在有三个样本,每个样本有五个特征,需要在三个样本的同样位置的特征上求取均值、方差、gamma和beta,在每一个特征维度上都有对应的均值、方差、gamma和beta。
下面通过代码学习nn.BatchNorm1d:
batch_size = 3 # batch_size
num_features = 5 # 每一个数据的特征个数
momentum = 0.3
features_shape = (1) # 特征维度为1
feature_map = torch.ones(features_shape) # [1] # 1D
feature_maps = torch.stack([feature_map*(i+1) for i in range(num_features)], dim=0) # [1,2,3,4,5] # 2D
feature_maps_bs = torch.stack([feature_maps for i in range(batch_size)], dim=0) # [[][][]] # 3D
print("input data:n{} shape is {}".format(feature_maps_bs, feature_maps_bs.shape))
bn = nn.BatchNorm1d(num_features=num_features, momentum=momentum)
running_mean, running_var = 0, 1
for i in range(2):
outputs = bn(feature_maps_bs)
print("niteration:{}, running mean: {} ".format(i, bn.running_mean))
print("iteration:{}, running var:{} ".format(i, bn.running_var))
mean_t, var_t = 2, 0
running_mean = (1 - momentum) * running_mean + momentum * mean_t
running_var = (1 - momentum) * running_var + momentum * var_t
print("iteration:{}, 第二个特征的running mean: {} ".format(i, running_mean))
print("iteration:{}, 第二个特征的running var:{}".format(i, running_var))
通过运行代码,得到输出为:
iteration:0, running mean: tensor([0.3000, 0.6000, 0.9000, 1.2000, 1.5000])
iteration:0, running var:tensor([0.7000, 0.7000, 0.7000, 0.7000, 0.7000])
iteration:0, 第二个特征的running mean: 0.6
iteration:0, 第二个特征的running var:0.7
iteration:1, running mean: tensor([0.5100, 1.0200, 1.5300, 2.0400, 2.5500])
iteration:1, running var:tensor([0.4900, 0.4900, 0.4900, 0.4900, 0.4900])
iteration:1, 第二个特征的running mean: 1.02
iteration:1, 第二个特征的running var:0.48999999999999994
2.3.2 nn.BatchNorm2d
nn.BatchNorm2d和nn.BatchNorm1d输入数据的主要不同在于特征维度上,卷积神经网络输出的一个特征图就是二维的形式。
如下图,假设一个特征图的维度为22,一个层有三个卷积核,会输出三个通道的22的特征图,一个特征图在BN中理解为一个特征,BN会在一个特征上求取均值、方差、gamma和beta。因此在nn.BatchNorm2d中输入数据的形式为[3,3,2,2]。

下面通过代码研究nn.BatchNorm2d的具体使用:
batch_size = 3
num_features = 6
momentum = 0.3
features_shape = (2, 2)
feature_map = torch.ones(features_shape) # 2d # 2D
feature_maps = torch.stack([feature_map*(i+1) for i in range(num_features)], dim=0) # 3d # 3D
feature_maps_bs = torch.stack([feature_maps for i in range(batch_size)], dim=0) # 4d # 4D
print("input data:n{} shape is {}".format(feature_maps_bs, feature_maps_bs.shape))
bn = nn.BatchNorm2d(num_features=num_features, momentum=momentum)
running_mean, running_var = 0, 1
for i in range(2):
outputs = bn(feature_maps_bs)
print("niter:{}, running_mean.shape: {}".format(i, bn.running_mean.shape))
print("iter:{}, running_var.shape: {}".format(i, bn.running_var.shape))
print("iter:{}, weight.shape: {}".format(i, bn.weight.shape))
print("iter:{}, bias.shape: {}".format(i, bn.bias.shape))
q代码对应输出为:
iter:0, running_mean.shape: torch.Size([6])
iter:0, running_var.shape: torch.Size([6])
iter:0, weight.shape: torch.Size([6])
iter:0, bias.shape: torch.Size([6])
iter:1, running_mean.shape: torch.Size([6])
iter:1, running_var.shape: torch.Size([6])
iter:1, weight.shape: torch.Size([6])
iter:1, bias.shape: torch.Size([6])
2.3.3 nn.BatchNorm3d
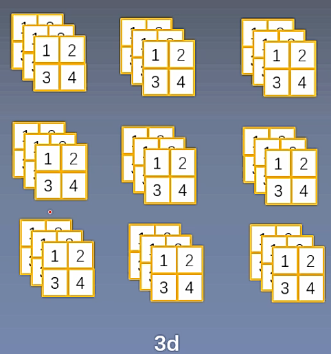
下图所示为nn.BatchNorm3d的输入数据形式,一个数据的一个特征是3维的,其形式为[2,2,3],一个数据有3个特征,一共有3个样本,所以nn.BatchNorm3d的输入数据形式为[3,3,2,2,3]。
nn.BatchNorm3d的代码如下:
batch_size = 3
num_features = 4
momentum = 0.3
features_shape = (2, 2, 3)
feature = torch.ones(features_shape) # 3D
feature_map = torch.stack([feature * (i + 1) for i in range(num_features)], dim=0) # 4D
feature_maps = torch.stack([feature_map for i in range(batch_size)], dim=0) # 5D
print("input data:n{} shape is {}".format(feature_maps, feature_maps.shape))
bn = nn.BatchNorm3d(num_features=num_features, momentum=momentum)
running_mean, running_var = 0, 1
for i in range(2):
outputs = bn(feature_maps)
print("niter:{}, running_mean.shape: {}".format(i, bn.running_mean.shape))
print("iter:{}, running_var.shape: {}".format(i, bn.running_var.shape))
print("iter:{}, weight.shape: {}".format(i, bn.weight.shape))
print("iter:{}, bias.shape: {}".format(i, bn.bias.shape))
最后
以上就是复杂小熊猫最近收集整理的关于pytorch —— Batch Normalization1、Batch Normalization概念2、Pytorch的Batch Normalization 1d/2d/3d实现的全部内容,更多相关pytorch内容请搜索靠谱客的其他文章。








发表评论 取消回复