多样性增强
在讲随机森林之前,先讨论一下多样性增强.在集成学习中需要有效的生成多样性大的个体学习器,与构造单一学习器对比而言,一般是通过在学习过程中引入随机性,常见的做法是对数据样本,输入属性,输出表示,算法参数进行扰动.
1)数据样本扰动
给定初始数据集,可从中产生生不同的数据子集,再利用不同的数据子集训练出不同的个体学习器.数据样本扰动是基于采样法,例如Bagging采用自助法采样,,对很多的常见基学习器,例如决策树,神经网络等,训练样本稍加变动就会导致学习器有显著变化,这些学习器称为‘不稳定基学习器’,但是也有稳定学习器,对于样本扰动,这样的学习器往往不会出现太显著的变化,例如线性学习器,除非特别离群的点,一般的话对拟合直线影响不大;支持向量机,与支持向量关系比较大,其他地方的点对学习器影响不大;朴素贝叶斯,在样本分布相对固定时,样本足够多时样本扰动不足以大幅度改变概率;K近邻学习器,主要与K个邻居有关,而与其他位置的点关系不大,这类学习器称为稳定学习器.对于这类学习器集成,往往需要属性扰动等机制.但是值得一提的是,数据样本扰动会改变样本初始的分布,会人为的引入偏差,也会影响基学习器的性能.
2)输入属性扰动
训练集的输入向量X通常不是一维的,这里我们假设输入数据维度是K维,从而选择不同的子属性集提供了观察数据的不同视角,显然从不同属性子空间训练出来的学习器会有所不同,著名的随机子空算法就依赖于属性扰动,该算法从初始属性集中抽出若干个子集,再基于每个属性子集训练一个基学习器.在包含大量属性的情况下,在属性子空间训练个体学习器不仅能产生多样性大的个体,还会因为属性维数减少提高训练效率,但当数据维数较小或数据的属性都有较大重要性时,不宜使用属性扰动.
3)输出表示扰动
此类做法的基本思想是对输出表示进行操纵以增强多样性,可对训练样本的类别标记稍作变动,但要注意尺度,如果变动较大,则会人为引入较大偏差,反而得不偿失.例如二分类到多分类问题,MvM中使用的ECOC法,就是通过改变输出表示,最后采用投票法决定样本类别.
4)算法参数扰动
这个和我们常说的调参比较相似,一个基学习器算法都对应着或多或少的超参数,通过对算法参数的调整,往往能够得到不同性能的学习器,例如设置神经网络的隐层神经元数,决策树的深度,支持向量机的带宽width等等.
随机森林
上一节讲到了Bagging,Bagging实际上就是通过样本扰动增加基学习器多样性,最终使用投票法得到最终结果,这一节的随机森林是Bagging的一个变体,RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择,相当于在样本属性扰动的基础上,在决策树特征选择时加入了属性扰动,又因为决策树是不稳定学习器,所以随机森林中基学习器的多样性大大增强,从而带来了更好的泛化性能.具体来说就是,传统决策树在选择属性划分时是在当前属性节点(假设有d个属性)进行最优划分属性选择,而随机森林中,则是先生成一个包含k个属性的属性子集(k≤d),然后再从k个属性中选择一个最优划分属性,这里参数k控制了随机性的引入程度,若令K=d,则生成过程与原始决策树一致,一般情况下,推荐使用k = lnd.
简单的示意图如下:
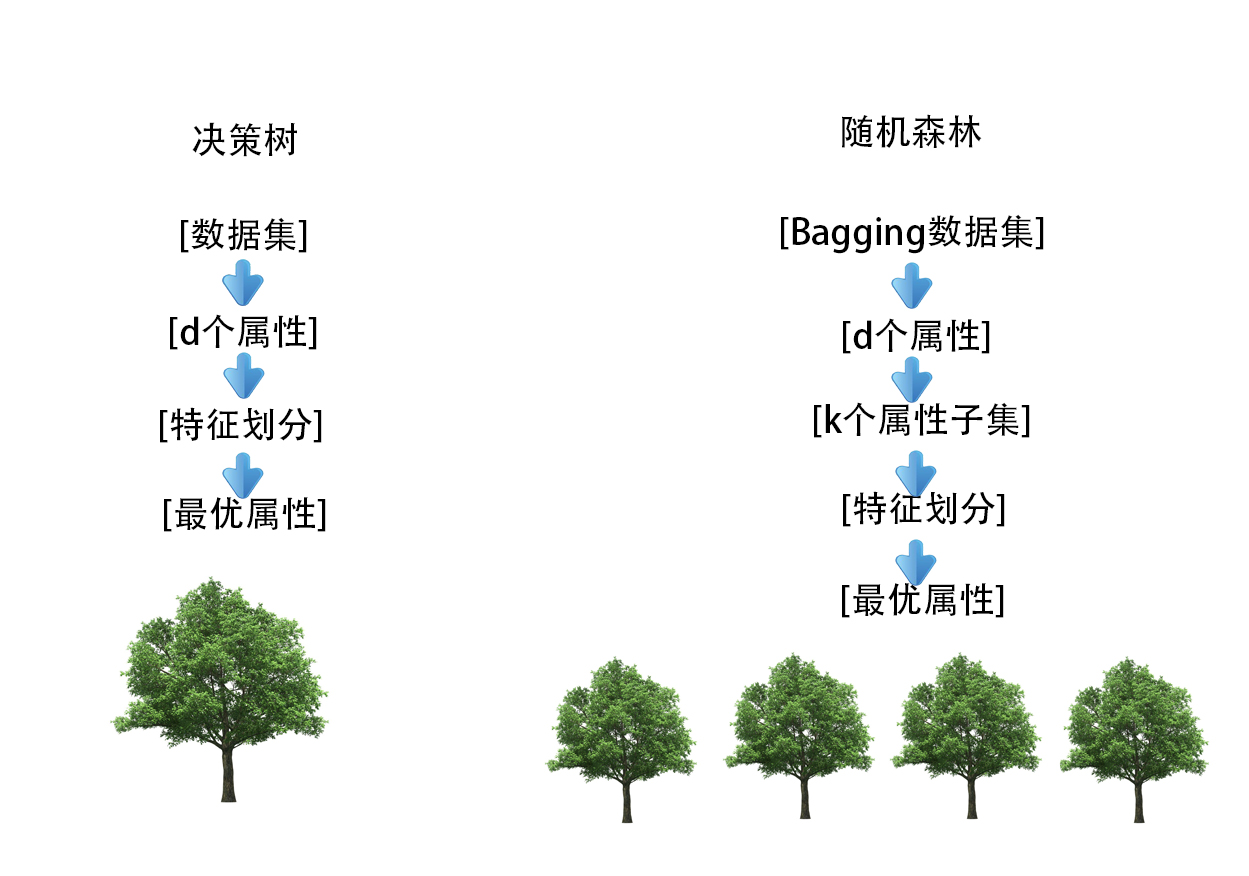
随机森林原理简单,容易实现,计算开同基学习器相当,但是往往展现出强大的性能,可以看出,在样本扰动的基础上,再加入样本扰动,最终集成的泛化性能可能进一步增加.
随机森林实现
1)函数形式与参数
RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
这里大部分参数与决策树参数的含义相同,例如特征划分方式,最大深度,最小子叶数等等,这里主要说一下与决策树不同的参数:
n_estimators:决策树的个数,相当于1你的森林需要多少棵树,10是默认的,树越多越好,但要考虑系统开销与过拟合的问题
boostrap:是否有放回采样,不放回采样的话数据不会重复
oob_score:这里对应前面讲到的自助采样的一个优点-包外估计(out-of-bag esitimate),由于基学习器使用了约63.2%的样本,所以剩下约36.8%的样本可以用作验证集对泛化性能进行评价
n_jobs:并行数,我们讲到bagging是并行是生成的,所以bagging时可以设置参数大于1,决定并行生成多少学习器,而Adaboost则需要默认1,因为它是串行生成的
2)函数实现
这里数据采用《机器学习实战》集成学习那一章的病马数据,看看分类效果怎么样.
导入相关库
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
import numpy as np 导入随机森林,交叉验证以及numpy库
读取文件
def loadDataSet(fileName):#读取数据
numFeat = len(open(fileName).readline().split('t'))
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat主程序
if __name__ == "__main__":
fileName = 'horseColicTest2.txt'#读取文件
dataMat,labelMat = loadDataSet(fileName)#提取数据集
clf = RandomForestClassifier(n_estimators=100, max_depth=None,
max_features='sqrt',min_samples_split=2, random_state=0,oob_score = True)#初始化随机森林
clf.fit(dataMat,labelMat)#适应模型
scores = cross_val_score(clf, dataMat,labelMat)#交叉验证
scores.mean()
print('交叉验证:',scores.mean())#交叉验证平均正确率
print('特征数:',clf.n_features_) #特征数
print('特征重要性:',clf.feature_importances_)#特征重要性
print('包外预测:',clf.oob_score_ )#包外预测
print('包外预测概率:',clf.oob_decision_function_)#包外预测概率
importance_list = np.argsort(-clf.feature_importances_)这里只是简单地建模,注意建模是比较关键的几个参数,决策树个数n_estimators,最大特征数max_featuress,以及如果想进行包外预测的话,要设置oob_score = True,因为包外预测是默认None的,其次boostrap是默认True的,所以这里包外估计不用设置Boostrap.
建模后通过cross_val_score方法可以求出交叉验证正确率,通过n_featuress方法可以得到预测的特征数,通过feature_importancess_方法可以得到各个特征的重要程度,通过obb_score_方法可以得到包外预测准确率,而通过obb_decision_function_方法可以得到每个样本的正负包外预测准确率.
下面看一下运行结果:
交叉验证: 0.8033126294
特征数: 21
特征重要性: [ 0.01711044 0.00919911 0.07351338 0.15271884 0.05239271 0.03671487
0.0210451 0.14226094 0.01203942 0.07059542 0.02364601 0.03109124
0.05005074 0.03305065 0.02808322 0.02442624 0.02248264 0.06917138
0.07207685 0.02974831 0.02858248]
包外预测: 0.716417910448
交叉验证准确率80.33%,共有21个特征,每个特征的重要性的归一化结果放在特征重要性一栏中,包外预测的准确率稍低,为71.64%.
包外预测概率: [[ 0.11538462 0.88461538]
[ 0.03125 0.96875 ]
[ 0.61538462 0.38461538]
[ 0.44444444 0.55555556]
[ 0.11363636 0.88636364]
[ 0.32432432 0.67567568]
[ 0.18181818 0.81818182]
[ 0.17073171 0.82926829]
[ 0.06666667 0.93333333]
[ 0.5 0.5 ]
[ 0.17948718 0.82051282]包外预测概率阵包含所有样本的正例预测率与反例预测率,样本数很多,这里就不一一列出了,大家可以自己运行看看结果,包外预测时会选择概率大的作为预测类别,正反概率相同时,具体的划分方法就不太清楚了,可能和之前一样随机生成,或者考虑置信度来抉择类别.
重要特征排序(按索引从大到小): [3, 7, 2, 18, 9, 17, 4, 12, 5, 13, 11, 19, 20, 14, 15, 10, 16, 6, 0, 8, 1]根据feature_importancess_方法得到预测变量的重要性,通过np.argsort函数得到预测变量重要性从大到小的顺序,注意这里np.argsort()返回的是索引,不是对应变量重要性的值,通过索和之前的重要性列表,可以用循环得到前几的重要特征,也可以根据阈值排除一些重要性很低的特征,降低维度,重新建模,提高模型泛化能力.
总结
集成学习的几个经典例子就介绍完了,回顾一下,串行生成Adaboost,并行生成Bagging,样本扰动Bagging,样本属性都扰动RandomForest,针对其他基学习器,还有很多的集成方法需要探讨,除此之外,集成学习器的结果汇总策略-投票法,平均法,学习法等等,以及学习器的多样性度量与多样性提升,也都和集成学习息息相关.相关内容有问题大家可以交流讨论~
最后
以上就是光亮哑铃最近收集整理的关于集成学习-随机森林原理与实现 西瓜书的全部内容,更多相关集成学习-随机森林原理与实现内容请搜索靠谱客的其他文章。








发表评论 取消回复