我是靠谱客的博主 激昂冥王星,这篇文章主要介绍随机森林算法初步实现1. 导入数据2. 划分数据集3. 数据处理4. 构建模型5. 对测试集进行预测6. 回归性能评估7. 对数据进行预测,并保存至txt文件,现在分享给大家,希望可以做个参考。
随机森林算法是一种灵活,易于使用的机器学习算法,本文主要是实现初步的模型,供大家学习参考。
文章目录
- 1. 导入数据
- 2. 划分数据集
- 3. 数据处理
- 4. 构建模型
- 5. 对测试集进行预测
- 6. 回归性能评估
- 7. 对数据进行预测,并保存至txt文件
1. 导入数据
导入我们准备的数据,这里df_train是训练使用的数据,df_test是后面需要对其进行预测的数据
import numpy as np
import pandas as pd
df_train = pd.read_table('./data/zhengqi_train.txt')
df_test = pd.read_table('./data/zhengqi_test.txt')
2. 划分数据集
对训练数据进行训练集和测试集的切分
from sklearn.model_selection import train_test_split
X = df_train.iloc[:, :-1]
y = df_train['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
3. 数据处理
数据归一化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
4. 构建模型
构建随机森林模型
# 训练随机森林解决回归问题
from sklearn.ensemble import RandomForestRegressor
regressor = RandomForestRegressor(n_estimators=200, random_state=0)
# random_state=0 # 0.1763
regressor.fit(X_train, y_train)
5. 对测试集进行预测
这里是对测试集进行预测,以便后续可以进行回归性能的评估
y_pred = regressor.predict(X_test)
6. 回归性能评估
平均绝对误差(Mean Absolute Error,MAE)
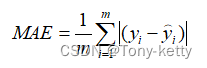
均方误差(Mean Square Error,MSE)
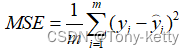
均方根误差(Root Mean Squared Error,RMSE)
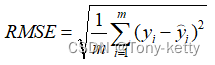
# 评估回归性能
from sklearn import metrics
print('MAE: ', metrics.mean_absolute_error(y_test, y_pred))
print('MSE: ', metrics.mean_squared_error(y_test, y_pred))
print('RMSE: ', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
7. 对数据进行预测,并保存至txt文件
pre = regressor.predict(df_test)
pre = pd.DataFrame(pre)
pre.to_csv('./result/随机森林001-2.txt', index = False, header = None)
如有错误,欢迎各位指正,感激不尽。
最后
以上就是激昂冥王星最近收集整理的关于随机森林算法初步实现1. 导入数据2. 划分数据集3. 数据处理4. 构建模型5. 对测试集进行预测6. 回归性能评估7. 对数据进行预测,并保存至txt文件的全部内容,更多相关随机森林算法初步实现1.内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复