先用pytorch训练FCN,然后把权重的pth文件,先转为wts文件,然后在NX板上转为tensorrt的engine文件
只写具体思路和遇到的问题,完整版参考github
这里写的是paper里的由vgg16而来的FCN,首先实现vgg16的tensorrt
先来看下vgg16的结构
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
其中每一层的数字表示输出的channel数,输入channel是前一个数字,每层后面带有relu层,M表示max pooling layer
参考pytorch版vgg代码,可知
每个卷积层默认kernel size=3, padding=1, max pooling的kernel size=2, stride=2
首先定义输入层(现在实现的是create engine函数)
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{3, INPUT_H, INPUT_W}); //输入size,这里是3通道
输入size根据实际需要,这里是640x640
然后从wts文件里面load weights
std::map<std::string, Weights> weightMap = loadWeights("../fcn.wts"); //wts文件对应的文件夹
这里实现一个卷积层,一个relu层,一个max pooling层,后面整个vgg以此类推
实现第一个block,也就是[64, 64, M]
注意我们这里的vgg并不需要自己训练,直接用官网的预训练权重即可,可以看到wts文件中是pretrained_net.features.X.weight, X的位置是数字,那么怎么知道X的数字对应VGG的第几层呢?我们可以数,从0开始,比如[64, 64, M]
0对应第一层,1对应64后跟着的relu,2对应第2个64, 3对应后面跟着的relu,4对应M,以此类推
那么第一层卷积层可以这样写
//64是输出channel,输入channel不需要指定
IConvolutionLayer* conv1 = network->addConvolutionNd(*data, 64, DimsHW{3, 3}, weightMap["pretrained_net.features.0.weight"], weightMap["pretrained_net.features.0.bias"]);
conv1->setPaddingNd(DimsHW{1, 1}); //H, W padding=1
然后是relu层
IActivationLayer* relu1 = network->addActivation(*conv1->getOutput(0), ActivationType::kRELU);
第二个64
conv1 = network->addConvolutionNd(*relu1->getOutput(0), 64, DimsHW{3, 3}, weightMap["pretrained_net.features.2.weight"], weightMap["pretrained_net.features.2.bias"]);
conv1->setPaddingNd(DimsHW{1, 1});
relu1 = network->addActivation(*conv1->getOutput(0), ActivationType::kRELU);
max pooling
IPoolingLayer* pool1 = network->addPoolingNd(*relu1->getOutput(0), PoolingType::kMAX, DimsHW{2, 2});
pool1->setStrideNd(DimsHW{2, 2});
这样就完成了第一个block [64, 64, ‘M’],后面的写法一样
这样就完成了VGG16的部分
VGG16一共有5个max pooling layer, 记作pool1 ~ pool5
根据paper可知,FCN是要把pool5进行反卷积,和pool4相加,还要把相加的结果过bn层和relu层后,再和pool3相加,具体见下图
这里实现把pool5进行反卷积,和pool4相加的部分,其他以此类推
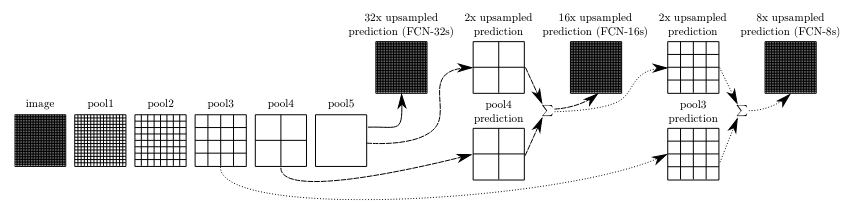 定义反卷积层
定义反卷积层
IDeconvolutionLayer* deconv1 = network->addDeconvolutionNd(*pool5->getOutput(0), 512, DimsHW{3,3}, weightMap["deconv1.weight"], weightMap["deconv1.bias"]);
deconv1->setStride(DimsHW{2, 2});
deconv1->setPrePadding(DimsHW{1, 1}); //pytorch中的padding
deconv1->setDilationNd(DimsHW{1, 1}); //pytorch中的dilation
deconv1->setPostPadding(DimsHW{2, 2}); //pytorch中的output_padding
定义相加层,把pool5的反卷积层和pool4加起来
IElementWiseLayer* out1 = network->addElementWise(*pool4->getOutput(0), *deconv1->getOutput(0), ElementWiseOperation::kSUM);
但是这里遇到了问题,出现了以下error
Error Code 9: Internal Error ((Unnamed Layer* 32) [ElementWise]: broadcast dimensions must be conformable
这是因为相加的维度不匹配,那么需要看一下输入维度分别是什么
我们把输入维度打印出来,需要看pool5, deconv1和pool4的维度
cout << "pool5 shape" << endl;
cout << pool5->getOutput(0)->getDimensions().d[0] << endl;
cout << pool5->getOutput(0)->getDimensions().d[1] << endl;
cout << pool5->getOutput(0)->getDimensions().d[2] << endl;
可以看到
pool5 shape
512
20
20
deconv1 shape
512
39
39
pool4 shape
512
40
40
可以看到pool5的size是20 x 20, 但卷积后变成了39 x 39, 和pool4的40 x 40不匹配
查了pytorch ConvTranspose2d的文档,输出的size应该是
Hout=(Hin−1)×stride[0]−2×padding[0]+dilation[0]×(kernel_size[0]−1)+output_padding[0]+1
Wout=(Win−1)×stride[1]−2×padding[1]+dilation[1]×(kernel_size[1]−1)+output_padding[1]+1
用这个公式计算,deconv1的size应该是40 x 40的,除非实现细节和pytorch不同,通过尝试,把post padding改为0,结果变成了40 x 40, 即需要把这行注释掉,具体实现底层细节不是很清楚
//deconv1->setPostPadding(DimsHW{2, 2}); //pytorch中的output_padding
然后过一个bn层
IScaleLayer* bn1 = addBatchNorm2d(network, weightMap, *out1->getOutput(0), "bn1", 1e-5);
addBatchNorm2d的实现细节如下
IScaleLayer* addBatchNorm2d(INetworkDefinition *network, std::map<std::string, Weights>& weightMap, ITensor& input, std::string lname, float eps) {
float *gamma = (float*)weightMap[lname + ".weight"].values;
float *beta = (float*)weightMap[lname + ".bias"].values;
float *mean = (float*)weightMap[lname + ".running_mean"].values;
float *var = (float*)weightMap[lname + ".running_var"].values;
int len = weightMap[lname + ".running_var"].count;
std::cout << "len " << len << std::endl;
float *scval = reinterpret_cast<float*>(malloc(sizeof(float) * len));
for (int i = 0; i < len; i++) {
scval[i] = gamma[i] / sqrt(var[i] + eps);
}
Weights scale{DataType::kFLOAT, scval, len};
float *shval = reinterpret_cast<float*>(malloc(sizeof(float) * len));
for (int i = 0; i < len; i++) {
shval[i] = beta[i] - mean[i] * gamma[i] / sqrt(var[i] + eps);
}
Weights shift{DataType::kFLOAT, shval, len};
float *pval = reinterpret_cast<float*>(malloc(sizeof(float) * len));
for (int i = 0; i < len; i++) {
pval[i] = 1.0;
}
Weights power{DataType::kFLOAT, pval, len};
weightMap[lname + ".scale"] = scale;
weightMap[lname + ".shift"] = shift;
weightMap[lname + ".power"] = power;
IScaleLayer* scale_1 = network->addScale(input, ScaleMode::kCHANNEL, shift, scale, power);
assert(scale_1);
return scale_1;
}
到这里,所有的模块实现都已完成,剩下的就是组装了
可能还会遇到一个error
Error Code 10: Internal Error (Could not find any implementation for node
这个问题的原因大概率是内存没分配够
config->setMaxWorkspaceSize(XX) //具体依情况而定
这样就能生成fcn.engine文件了
最后
以上就是漂亮汽车最近收集整理的关于FCN8s 转 tensorrt(通过wts文件)的全部内容,更多相关FCN8s内容请搜索靠谱客的其他文章。








发表评论 取消回复