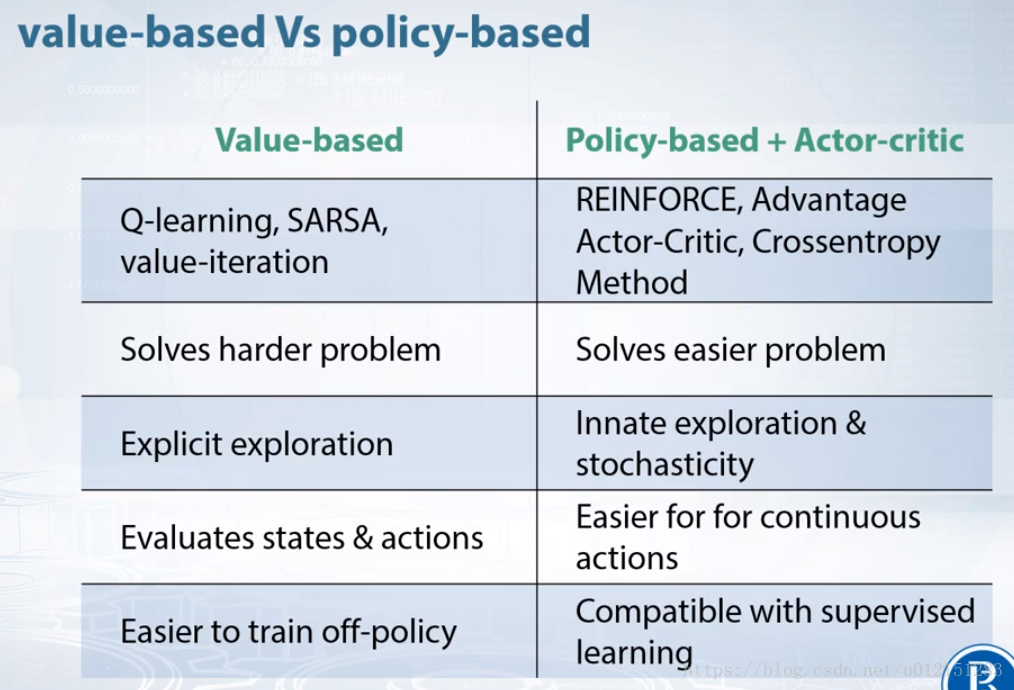
基于策略RL和基于值函数RL
直觉


不同种类的策略


策略梯度形式

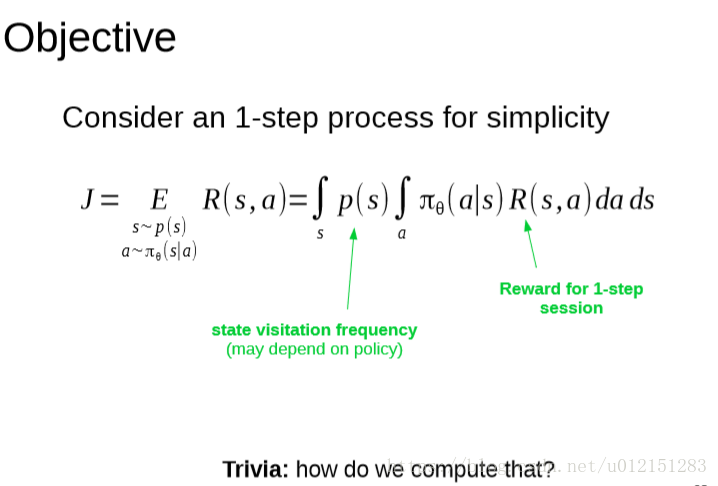


LOG技巧

REINFORCE


with baseline


Actor-Critic
Advantage Actor Critic

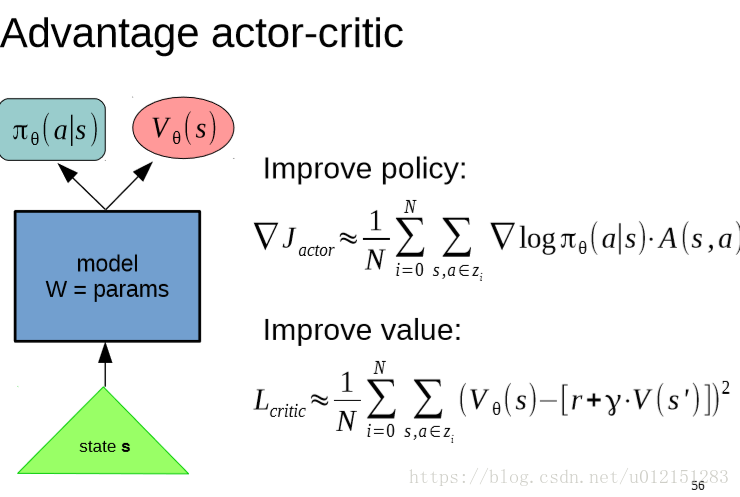

policy based 和 Value based
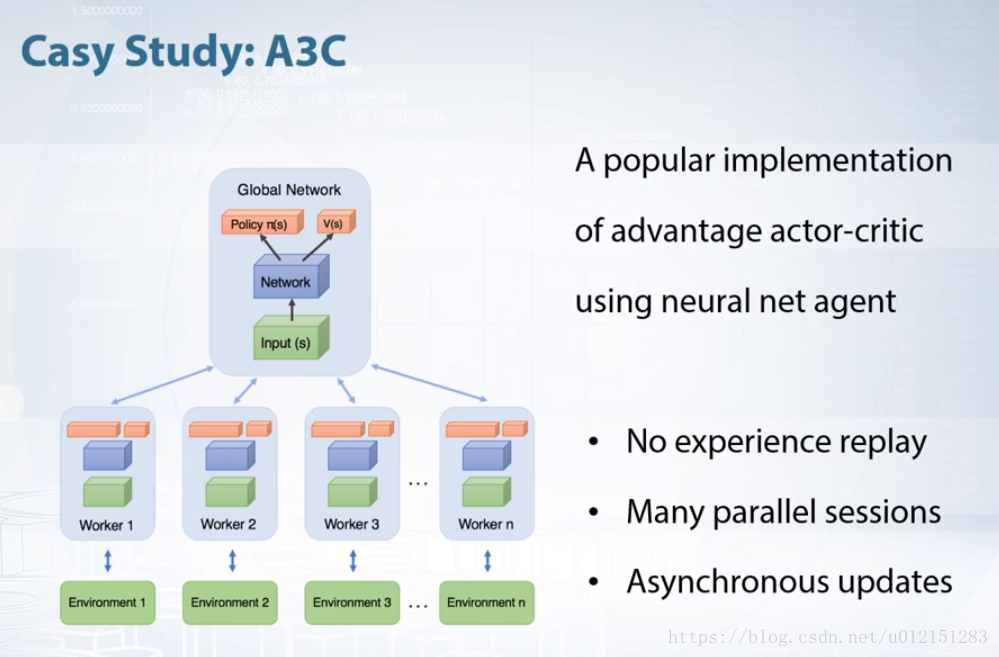
A3C
结合监督学习和强化学习



最后
以上就是健康大碗最近收集整理的关于《强化学习》基于策略的方法基于策略RL和基于值函数RLREINFORCEActor-Critic结合监督学习和强化学习的全部内容,更多相关《强化学习》基于策略内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。

![行为型-策略模式案例 Comparator: Arrays.sort(T[], Comparator)案例 Spring 后置处理器: applyBeanPostProcessorsBeforeInstantiation案例 spring ApplicationContextAware案例 spring @Enable XXX](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)






发表评论 取消回复