前言
本篇旨在总结强化学习相关术语,主要参考了邹伟等人所著的《强化学习》(清华大学出版社)这本书。
策略
在状态s下执行动作a的概率。
π
(
a
∣
s
)
=
P
(
A
t
=
a
∣
S
t
=
s
)
pi(a mid s)=Pleft(A_{t}=a mid S_{t}=sright)
π(a∣s)=P(At=a∣St=s)
确定性策略:输出动作a为确定的一个动作。
随机性策略:输出动作a多个动作的概率分布。
预测与控制
预测(评估):评估当前的策略有多好,即求解既定策略下的状态值函数。
控制(改善):改善当前策略,即求解所有可能策略中最优价值函数及最优策略。
贝尔曼方程
状态值函数
状态值函数指从状态s开始,遵循当前策略
π
pi
π时所获得的期望回报。
V
π
(
s
)
=
E
π
[
G
t
∣
S
t
=
s
]
=
E
π
[
R
t
+
1
+
γ
R
t
+
2
+
⋯
∣
S
t
=
s
]
V_{pi}(s)=E_{pi}left[G_{t} mid S_{t}=sright]=E_{pi}left[R_{t+1}+gamma R_{t+2}+cdots mid S_{t}=sright]
Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+1+γRt+2+⋯∣St=s]
通过下面的推导,可以将其化成迭代形式:
V
π
(
s
)
=
E
π
[
G
t
∣
S
t
=
s
]
=
E
π
[
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
⋯
∣
S
t
=
s
]
=
E
π
[
R
t
+
1
+
γ
(
R
t
+
2
+
γ
R
t
+
3
+
⋯
)
∣
S
t
=
s
]
=
E
π
[
R
t
+
1
+
γ
G
t
+
1
∣
S
t
=
s
]
=
E
π
[
R
t
+
1
+
γ
V
(
S
t
+
1
)
∣
S
t
=
s
]
begin{aligned} V_{pi}(s) &=E_{pi}left[G_{t} mid S_{t}=sright] \ &=E_{pi}left[R_{t+1}+gamma R_{t+2}+gamma^{2} R_{t+3}+cdots mid S_{t}=sright] \ &=E_{pi}left[R_{t+1}+gammaleft(R_{t+2}+gamma R_{t+3}+cdotsright) mid S_{t}=sright] \ &=E_{pi}left[R_{t+1}+gamma G_{t+1} mid S_{t}=sright] \ &=E_{pi}left[R_{t+1}+gamma Vleft(S_{t+1}right) mid S_{t}=sright] end{aligned}
Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+1+γRt+2+γ2Rt+3+⋯∣St=s]=Eπ[Rt+1+γ(Rt+2+γRt+3+⋯)∣St=s]=Eπ[Rt+1+γGt+1∣St=s]=Eπ[Rt+1+γV(St+1)∣St=s]
动作值函数
和状态值函数类似,动作值函数在状态s下多了一个选择动作a。
Q
π
(
s
,
a
)
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
E
π
[
R
t
+
1
+
γ
Q
π
(
S
t
+
1
,
A
t
+
1
)
∣
S
t
=
s
,
A
t
=
a
]
begin{aligned} Q_{pi}(s, a) &=E_{pi}left[G_{t} mid S_{t}=s, A_{t}=aright] \ &=E_{pi}left[R_{t+1}+gamma Q_{pi}left(S_{t+1}, A_{t+1}right) mid S_{t}=s, A_{t}=aright] end{aligned}
Qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+1+γQπ(St+1,At+1)∣St=s,At=a]
贝尔曼期望方程
贝尔曼期望方程有四种表达方式。(其实就是将一个迭代图进行了拆分)
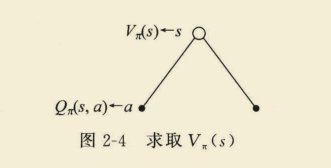
(1)基于状态s,采取动作a,求
V
π
(
s
)
V_{pi}(s)
Vπ(s)
V
π
(
s
)
=
∑
a
∈
A
π
(
a
∣
s
)
Q
π
(
s
,
a
)
V_{pi}(s)=sum_{a in A} pi(a mid s) Q_{pi}(s, a)
Vπ(s)=a∈A∑π(a∣s)Qπ(s,a)
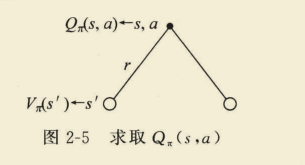
(2)采取行为a,状态转变成s’,求
Q
π
(
s
,
a
)
Q_{pi}(s, a)
Qπ(s,a)
Q
π
(
s
,
a
)
=
R
s
a
+
γ
∑
s
′
∈
S
P
s
s
′
a
V
π
(
s
′
)
Q_{pi}(s, a)=R_{s}^{a}+gamma sum_{s^{prime} in S} P_{s s^{prime}}^{a} V_{pi}left(s^{prime}right)
Qπ(s,a)=Rsa+γs′∈S∑Pss′aVπ(s′)
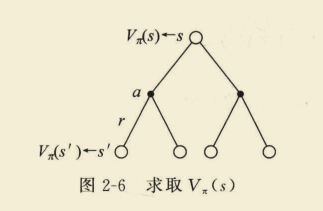
(3)基于状态s,采取行为a,状态转变至s’,求
V
π
(
s
)
V_{pi}(s)
Vπ(s)
V
π
(
s
)
=
∑
a
∈
A
π
(
a
∣
s
)
(
R
s
a
+
γ
∑
s
′
∈
S
P
s
s
′
a
V
π
(
s
′
)
)
V_{pi}(s)=sum_{a in A} pi(a mid s)left(R_{s}^{a}+gamma sum_{s^{prime} in S} P_{s s^{prime}}^{a} V_{pi}left(s^{prime}right)right)
Vπ(s)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′aVπ(s′))
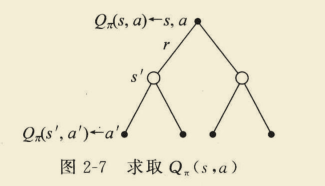
(4)采取行为a,状态转变至s’,采取行为a’,求
Q
π
(
s
,
a
)
Q_{pi}(s, a)
Qπ(s,a)
Q
π
(
s
,
a
)
=
R
s
a
+
γ
∑
s
′
∈
S
P
s
s
′
a
∑
a
′
∈
A
π
(
a
′
∣
s
′
)
Q
π
(
s
′
,
a
′
)
Q_{pi}(s, a)=R_{s}^{a}+gamma sum_{s^{prime} in S} P_{s s^{prime}}^{a} sum_{a^{prime} in A} pileft(a^{prime} mid s^{prime}right) Q_{pi}left(s^{prime}, a^{prime}right)
Qπ(s,a)=Rsa+γs′∈S∑Pss′aa′∈A∑π(a′∣s′)Qπ(s′,a′)
贝尔曼最优方程
首先定义两个符号:
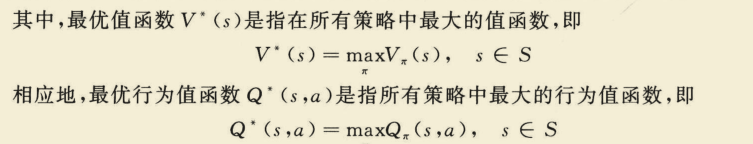
同样,贝尔曼最优方程也可表达成四种形式。
(1)基于状态s,采取动作a,求
V
∗
(
s
)
V^{*}(s)
V∗(s)
V
∗
(
s
)
=
max
Q
∗
(
s
,
a
)
V^{*}(s)=max Q^{*}(s, a)
V∗(s)=maxQ∗(s,a)
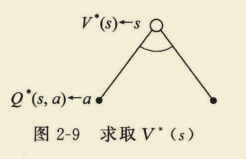
(2)采取动作a,状态转变成s‘,求
Q
∗
(
s
,
a
)
Q^{*}(s, a)
Q∗(s,a)。
Q
∗
(
s
,
a
)
=
R
s
a
+
γ
∑
s
′
∈
S
P
s
s
′
a
V
∗
(
s
′
)
Q^{*}(s, a)=R_{s}^{a}+gamma sum_{s^{prime} in S} P_{s s^{prime}}^{a} V^{*}left(s^{prime}right)
Q∗(s,a)=Rsa+γs′∈S∑Pss′aV∗(s′)
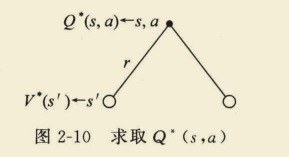
(3)基于状态s,采取行为a,状态转变至s’,求
V
∗
(
s
)
V^{*}(s)
V∗(s)
V
∗
(
s
)
=
max
a
R
s
a
+
γ
∑
s
′
∈
S
P
s
s
′
a
V
∗
(
s
′
)
V^{*}(s)=max _{a} R_{s}^{a}+gamma sum_{s^{prime} in S} P_{s s^{prime}}^{a} V^{*}left(s^{prime}right)
V∗(s)=amaxRsa+γs′∈S∑Pss′aV∗(s′)
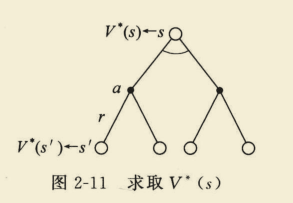
(4)采取动作a,状态转变成s‘,采取行为a‘,求
Q
∗
(
s
,
a
)
Q^{*}(s, a)
Q∗(s,a)。
Q
∗
(
s
,
a
)
=
R
s
a
+
γ
∑
s
′
∈
S
P
s
s
′
a
max
a
′
Q
∗
(
s
′
,
a
′
)
Q^{*}(s, a)=R_{s}^{a}+gamma sum_{s^{prime} in S} P_{s s^{prime}}^{a} max _{a^{prime}} Q^{*}left(s^{prime}, a^{prime}right)
Q∗(s,a)=Rsa+γs′∈S∑Pss′aa′maxQ∗(s′,a′)
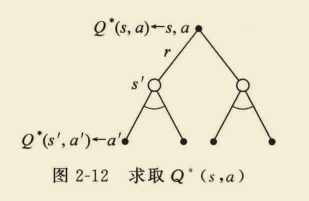
策略评估
策略评估:给定一个策略
π
pi
π,计算该策略下的值函数
V
π
(
s
)
V_{pi}(s)
Vπ(s)
使用贝尔曼期望方程进行迭代:
V
π
(
s
)
=
∑
a
∈
A
π
(
a
∣
s
)
(
R
s
a
+
γ
∑
s
′
∈
S
P
s
s
′
a
V
π
(
s
′
)
)
V_{pi}(s)=sum_{a in A} pi(a mid s)left(R_{s}^{a}+gamma sum_{s^{prime} in S} P_{s s^{prime}}^{a} V_{pi}left(s^{prime}right)right)
Vπ(s)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′aVπ(s′))
该方式利用后继状态s’的值来求当前值,也称作自举法
策略改进
策略评估之后,值函数已经计算出来。因此策略改进就是利用值函数来找到最优策略。
采用贪心算法来选取动作:
Q
π
(
s
,
a
)
=
R
s
a
+
γ
∑
s
′
∈
S
P
s
s
′
a
V
π
(
s
′
)
Q_{pi}(s, a)=R_{s}^{a}+gamma sum_{s^{prime} in S} P_{s s^{prime}}^{a} V_{pi}left(s^{prime}right)
Qπ(s,a)=Rsa+γs′∈S∑Pss′aVπ(s′)
π
′
=
max
a
∈
A
Q
π
(
s
,
a
)
pi^{prime}=max _{a in A} Q_{pi}(s, a)
π′=a∈AmaxQπ(s,a)
理论可证明,通过这样操作可以不断迭代,总而让值函数
V
π
(
s
)
V_{pi}(s)
Vπ(s)变大。
动态规划
动态规划(DP)即反复使用策略评估和策略改进进行迭代,每次迭代都会让值函数增加。逐渐收敛后,就找到了最优策略。
蒙特卡罗
动态规划(DP)方法必须依赖于状态转移概率和回报已知的情况,参照策略评估的式子,P和R必须是已知的值,因此这个方法属于有模型方法。
然而实际中,这两个量通常是未知的,需要智能体不断和环境交互才能估计出来,这就引入了无模型方法中的蒙特卡罗方法(MC)。
蒙特卡罗评估
和策略评估类似,蒙特卡罗评估指的是用蒙特卡罗的方式来估计值函数。蒙特卡罗本质上就是利用了大数定律,通过大量多次实验来逼近真实值。
因此,要评估值函数,首先利用策略
π
pi
π产生多个轨迹,每个轨迹都是从任意的初始状态开始到终止状态。
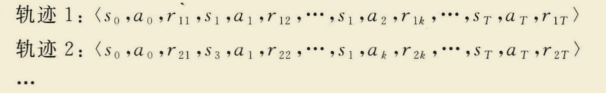
对于每个轨迹,都可以用下面的公式来计算累积回报:
G
t
=
r
t
+
1
+
γ
r
t
+
2
+
⋯
=
∑
k
=
0
∞
γ
k
r
t
+
k
+
1
G_{t}=r_{t+1}+gamma r_{t+2}+cdots=sum_{k=0}^{infty} gamma^{k} r_{t+k+1}
Gt=rt+1+γrt+2+⋯=k=0∑∞γkrt+k+1
得到累积回报之后,对于每个状态的价值有两种做法来计算:
第一种是首次访问法,每次只利用状态第一次出现的累积回报。
V
(
s
1
)
=
G
12
+
G
2
k
+
⋯
N
(
s
1
)
Vleft(s_{1}right)=frac{G_{12}+G_{2 k}+cdots}{Nleft(s_{1}right)}
V(s1)=N(s1)G12+G2k+⋯
第二种是每次访问法,将所有的状态回报纳入计算。
V
(
s
1
)
=
G
12
+
G
1
k
+
G
2
k
+
⋯
N
(
s
1
)
Vleft(s_{1}right)=frac{G_{12}+G_{1 k}+G_{2 k}+cdots}{Nleft(s_{1}right)}
V(s1)=N(s1)G12+G1k+G2k+⋯
除此之外,还可以采用增量式更新对评估公式进行优化。
V
(
s
t
)
←
V
(
s
t
)
+
1
k
+
1
(
G
t
−
V
(
s
t
)
)
Vleft(s_{t}right) leftarrow Vleft(s_{t}right)+frac{1}{k+1}left(G_{t}-Vleft(s_{t}right)right)
V(st)←V(st)+k+11(Gt−V(st))
将1/(k+1)替换成常数
α
alpha
α,就可以将上面的更新公式进一步简化。
V
(
s
t
)
←
V
(
s
t
)
+
α
(
G
t
−
V
(
s
t
)
)
Vleft(s_{t}right) leftarrow Vleft(s_{t}right)+alphaleft(G_{t}-Vleft(s_{t}right)right)
V(st)←V(st)+α(Gt−V(st))
α
alpha
α可视作更新步长,这样,就和机器学习比较类似。
同样,可以用类似的方式来更新动作值函数,公式如下:
Q
(
s
t
,
a
t
)
←
Q
(
s
t
,
a
t
)
+
α
(
G
t
−
Q
(
s
t
,
a
t
)
)
Qleft(s_{t}, a_{t}right) leftarrow Qleft(s_{t}, a_{t}right)+alphaleft(G_{t}-Qleft(s_{t}, a_{t}right)right)
Q(st,at)←Q(st,at)+α(Gt−Q(st,at))
蒙特卡罗控制
前面提到,控制即策略改进。蒙特卡罗方法同样可以采用贪心算法来改进策略。
π
′
(
s
t
)
=
argmax
a
t
∈
A
Q
(
s
t
,
a
t
)
pi^{prime}left(s_{t}right)=underset{a_{t} in A}{operatorname{argmax}} Qleft(s_{t}, a_{t}right)
π′(st)=at∈AargmaxQ(st,at)
然而,如果一直采用贪心算法存在一个问题。例如,有多家餐馆,每次吃饭时总选取当前认为最好吃的一家(这家的动作价值最大),如此,其它餐馆就得不到品鉴的机会,他们可能更好吃。
因此,引入一个随机机制,保证所有的动作都会被选中执行,即
ε
varepsilon
ε-贪心探索。以
ε
varepsilon
ε的概率从所有动作中随机选取一个,以
1
−
ε
1-varepsilon
1−ε的概率选取当前最优动作,策略数学表达如下:
π
(
a
∣
s
)
{
ε
m
+
1
−
ε
a
∗
=
arg
max
a
a
∈
A
Q
(
s
,
a
)
ε
m
其他
pi(a mid s)left{begin{array}{ll} frac{varepsilon}{m}+1-varepsilon & a^{*}=underset{a in A}{arg max _{a}} Q(s, a) \ frac{varepsilon}{m} & text { 其他 } end{array}right.
π(a∣s){mε+1−εmεa∗=a∈AargmaxaQ(s,a) 其他
这里的m表示动作总数。
该方法能够保证改进后的策略比原策略要好,相关证明书里有提到,这里省略。
同轨策略/离轨策略
在蒙特卡罗学习以及后面的时序差分方法中,都会涉及这个概念:同轨策略和离轨策略。
同轨策略(on-policy)指产生数据的策略与评估改进的策略是同一个策略。
离轨策略(off-policy)指产生数据的策略与评估改进的策略不是同一个策略。
举个例子,同轨策略就是篮球运动员在场上自己根据环境交互来改进自己的策略;离轨策略就是篮球运动员在场上和环境交互来产生数据,这些数据输送到篮球教练那里,改进篮球教练的策略。这一块更多内容可参看B站的这个视频【强化学习】蒙特卡洛方法-同轨VS离轨
(注:由于英译的问题,书里的同轨、离轨分别翻译为在线和离线,这里以Sutton《Reinforcement Learning》中译版的翻译为主)
时序差分
蒙特卡罗的方法固然合理,但存在一个致命缺陷是更新时间太长,因为每次轨迹的采样需要一直到终止状态,对于某些不具有终止状态的场景就不太适用。因此,时序差分法就起到作用。
时序差分法(TD)并不是到每次的终止状态再进行更新,而是每走一步就进行更新,因此,对蒙特卡罗法的Gt进行改进,公式如下:
V
(
s
t
)
←
V
(
s
t
)
+
α
(
R
t
+
1
+
γ
V
(
S
t
+
1
)
−
V
(
s
t
)
)
Vleft(s_{t}right) leftarrow Vleft(s_{t}right)+alphaleft(R_{t+1}+gamma Vleft(S_{t+1}right)-Vleft(s_{t}right)right)
V(st)←V(st)+α(Rt+1+γV(St+1)−V(st))
其中,
R
t
+
1
+
γ
V
(
S
t
+
1
)
R_{t+1}+gamma Vleft(S_{t+1}right)
Rt+1+γV(St+1)称为TD目标值;
δ
t
=
R
t
+
1
+
γ
V
(
S
t
+
1
)
−
V
(
s
t
)
delta_{t}=R_{t+1}+gamma Vleft(S_{t+1}right)-Vleft(s_{t}right)
δt=Rt+1+γV(St+1)−V(st)称为TD误差。
三种方式对比
上面总共有三种方式:动态规划(DP)、蒙特卡罗(MC)、时序差分(TD),下面进行一个简单的对比。


Sarsa
Sarsa是同轨策略的TD。
动作值函数更新公式如下:
Q
(
S
,
A
)
←
Q
(
S
,
A
)
+
α
(
R
+
γ
Q
(
S
′
,
A
′
)
−
Q
(
S
,
A
)
)
Q(S, A) leftarrow Q(S, A)+alphaleft(R+gamma Qleft(S^{prime}, A^{prime}right)-Q(S, A)right)
Q(S,A)←Q(S,A)+α(R+γQ(S′,A′)−Q(S,A))
从公式中可以发现,Sarsa的更新主要依赖于五个值:当前状态S,当前选择动作A,回报R,下一状态S’,下一状态选择动作A’。这也就是Sarsa起名的由来。
Sarsa算法的伪代码如下图所示:

Q-learning
Q-learning是离轨策略的TD。
动作值函数更新公式如下:
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
(
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
′
)
−
Q
(
S
t
,
A
t
)
)
Qleft(S_{t}, A_{t}right) leftarrow Qleft(S_{t}, A_{t}right)+alphaleft(R_{t+1}+gamma Qleft(S_{t+1}, A^{prime}right)-Qleft(S_{t}, A_{t}right)right)
Q(St,At)←Q(St,At)+α(Rt+1+γQ(St+1,A′)−Q(St,At))
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
′
)
=
R
t
+
1
+
γ
Q
(
S
t
+
1
,
argmax
Q
(
S
t
+
1
,
a
′
)
)
=
R
t
+
1
+
max
a
′
γ
Q
(
S
t
+
1
,
a
′
)
R_{t+1}+gamma Qleft(S_{t+1}, A^{prime}right)=R_{t+1}+gamma Qleft(S_{t+1}, operatorname{argmax} Qleft(S_{t+1}, a^{prime}right)right)=R_{t+1}+max _{a^{prime}} gamma Qleft(S_{t+1}, a^{prime}right)
Rt+1+γQ(St+1,A′)=Rt+1+γQ(St+1,argmaxQ(St+1,a′))=Rt+1+a′maxγQ(St+1,a′)
产生采样的策略是 ε varepsilon ε-贪心策略,评估改进的策略是贪心策略。
Q-learning算法的伪代码如下图所示:

Sarsa/Q-learning实例
为了进一步理解比较Sarsa和Q-learning的区别,选择两个实例来对两者进行分析。由于涉及程序与环境介绍,内容较多,我将其单独成篇。
【强化学习】迷宫寻宝:Sarsa和Q-Learning
【强化学习】悬崖寻路:Sarsa和Q-Learning
多步TD评估
在前面记录时序差分(TD)方法时,每次评估只取了一步,再引申一下可以变成多步TD。
n步TD的更新目标为n步回报:
G
t
n
=
r
t
+
1
+
γ
r
t
+
2
+
⋯
+
γ
n
−
1
r
t
+
n
+
γ
n
V
(
s
t
+
n
)
G_{t}^{n}=r_{t+1}+gamma r_{t+2}+cdots+gamma^{n-1} r_{t+n}+gamma^{n} Vleft(s_{t+n}right)
Gtn=rt+1+γrt+2+⋯+γn−1rt+n+γnV(st+n)
n步状态值函数更新为:
V
(
s
t
)
←
V
(
s
t
)
+
α
(
G
t
n
−
V
(
s
t
)
)
Vleft(s_{t}right) leftarrow Vleft(s_{t}right)+alphaleft(G_{t}^{n}-Vleft(s_{t}right)right)
V(st)←V(st)+α(Gtn−V(st))
TD( λ lambda λ)
在多步TD的基础上,还能再做进一步延申。 TD(
λ
lambda
λ)就是将多个TD(n)进行组合,引入
λ
lambda
λ作为权重,保证所有的TD(n)的权重之和为1。
这样可以更新回报:
G
t
λ
=
(
1
−
λ
)
∑
n
=
1
T
−
t
−
1
λ
n
−
1
G
t
n
+
λ
T
−
t
−
1
G
t
G_{t}^{lambda}=(1-lambda) sum_{n=1}^{T-t-1} lambda^{n-1} G_{t}^{n}+lambda^{T-t-1} G_{t}
Gtλ=(1−λ)n=1∑T−t−1λn−1Gtn+λT−t−1Gt
状态值函数更新为:
V
(
s
t
)
←
V
(
s
t
)
+
α
(
G
t
λ
−
V
(
s
t
)
)
Vleft(s_{t}right) leftarrow Vleft(s_{t}right)+alphaleft(G_{t}^{lambda}-Vleft(s_{t}right)right)
V(st)←V(st)+α(Gtλ−V(st))
从更新公式不难看出,该方法使用了后面的状态值函数来计算回报,可以用前向视图来进行理解。
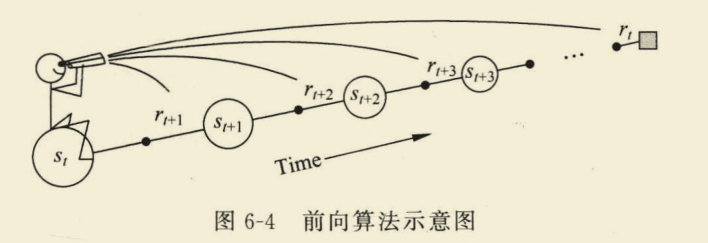
资格迹
TD(
λ
lambda
λ)更新是运用前向视图,也就是每次更新需要用到后面很多步的信息,但是这并不高效。
为了解决这一问题,引入资格迹。
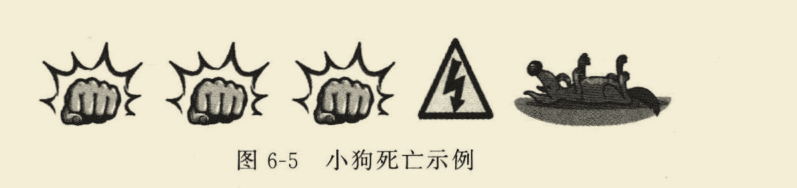
首先通过一个例子来简单理解什么是资格迹。
假设存在这么一个场景:一只小狗在接受3次拳击和1次电击后死亡,那么究竟是拳击还是电击更导致了小狗的死亡,也就是说,需要这么一个量来衡量两者对既定事实的贡献度,这个量就是资格迹。
累积迹
假设所有状态都有一个初始资格迹,设置为0,即
E
0
(
s
)
=
0
E_{0}(s)=0
E0(s)=0
之后,对于每个被访问到状态,资格迹乘以迹退化参数
λ
lambda
λ和衰减因子
γ
gamma
γ,然后加1;对于未被访问到的状态,只进行衰减而不加1。将两种情况融合,可以得到下面的更新公式。
E
t
(
s
)
=
γ
λ
E
t
−
1
(
s
)
+
1
(
S
t
=
s
)
E_{t}(s)=gamma lambda E_{t-1}(s)+1left(S_{t}=sright)
Et(s)=γλEt−1(s)+1(St=s)
其实这种定义方式就是累积迹,是资格迹的一种形式。
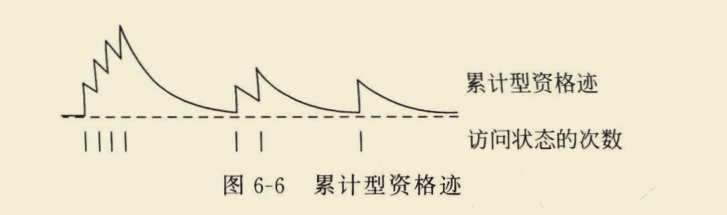
这个图比较清晰的解释了累积迹,被访问到,+1形成跳变;未被访问,持续衰减。
下面代入“小狗死亡”的例子,来计算拳击s1和电击s2的资格迹。

计算得到,s1的资格迹为1.61,大于电击的资格迹1,因此拳击是小狗致死的主要原因。
我们将累积迹引入TD的更新中,用资格迹来衡量当TD误差发生时,各状态的值函数更新会受到多大程度的影响。
TD误差公式如下:
δ
t
=
R
t
+
1
+
γ
V
t
(
S
t
+
1
)
−
V
t
(
S
t
)
delta_{t}=R_{t+1}+gamma V_{t}left(S_{t+1}right)-V_{t}left(S_{t}right)
δt=Rt+1+γVt(St+1)−Vt(St)
状态价值更新:
V
(
s
)
←
V
(
s
)
+
α
δ
t
E
t
(
s
)
V(s) leftarrow V(s)+alpha delta_{t} E_{t}(s)
V(s)←V(s)+αδtEt(s)
从公式上可以看出,使用资格迹进行依赖以前的状态,这就是所谓后向视图。
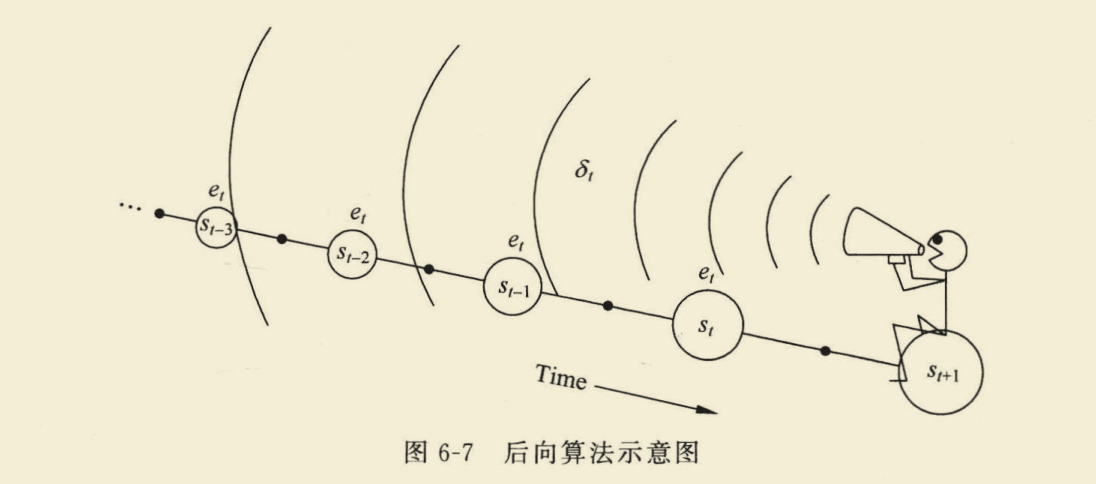
引入累积迹后,TD(
λ
lambda
λ)的后向算法流程如下:

替换迹
上面的运用到的是累积迹,除此之外还有替换迹。
主要原理都是一样的,区别在于更新公式。
替换迹的计算公式如下:
E
t
(
S
)
=
{
γ
λ
E
t
−
1
(
s
)
s
t
≠
s
1
s
t
=
s
E_{t}(S)=left{begin{array}{ll} gamma lambda E_{t-1}(s) & s_{t} neq s \ 1 & s_{t}=s end{array}right.
Et(S)={γλEt−1(s)1st=sst=s
可以发现,衰减其实是不变的,唯一变化的是当状态访问到时,不再是资格迹的累加,而是直接置1.
下面的图直观展示了累积迹和替换迹的区别。
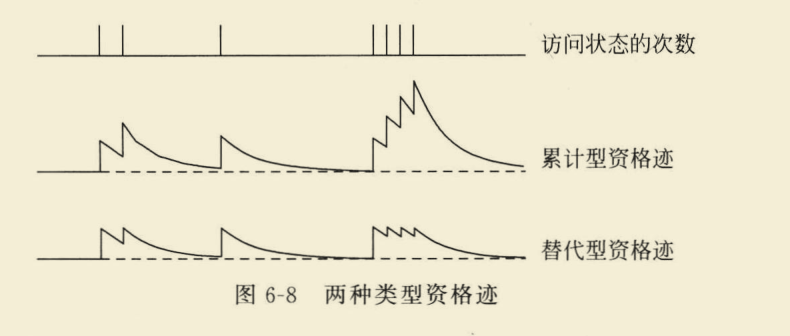
资格迹除了累积迹、替换迹之外,sutton的书里还提到一个荷兰迹,但荷兰迹适用条件有限(仅适用于线性情况),这里不作过多解读。
值函数逼近
前面所有的理论均适用于小样本的离散情况,而当处于大量样本的连续情况时,再适用Q表格显然无法满足需求。因此,我们引入函数逼近的方式来对值函数进行改写。
V
(
s
)
=
V
^
(
s
,
θ
)
V(s)=hat{V}(s, theta)
V(s)=V^(s,θ)
θ
theta
θ表示引入的参数,通常为一个向量。
具体的逼近形式大致可分为线性逼近和非线性逼近。
线性逼近
线性逼近并不常用,因此这里简单记录一下几种形式,不作进一步解读。
增量法
1.基于蒙特卡罗方法的参数逼近
参数更新公式:
∇
θ
=
α
(
G
t
−
θ
T
x
(
s
t
)
)
x
(
s
t
)
nabla boldsymbol{theta}=alphaleft(G_{t}-boldsymbol{theta}^{mathrm{T}} boldsymbol{x}left(boldsymbol{s}_{t}right)right) boldsymbol{x}left(boldsymbol{s}_{t}right)
∇θ=α(Gt−θTx(st))x(st)
2.基于时序差分方法的参数逼近
参数更新公式:
∇
θ
=
α
(
R
t
+
1
+
γ
θ
T
x
(
s
t
+
1
)
−
θ
T
x
(
s
t
)
)
x
(
s
t
)
nabla boldsymbol{theta}=alphaleft(R_{t+1}+gamma boldsymbol{theta}^{mathrm{T}} boldsymbol{x}left(boldsymbol{s}_{t+1}right)-boldsymbol{theta}^{mathrm{T}} boldsymbol{x}left(boldsymbol{s}_{t}right)right) boldsymbol{x}left(boldsymbol{s}_{t}right)
∇θ=α(Rt+1+γθTx(st+1)−θTx(st))x(st)
批量法
损失函数:
L
(
θ
)
=
∑
t
=
1
T
(
V
t
π
−
θ
T
x
(
s
t
)
)
2
L(boldsymbol{theta})=sum_{t=1}^{T}left(V_{t}^{pi}-boldsymbol{theta}^{mathrm{T}} boldsymbol{x}left(boldsymbol{s}_{t}right)right)^{2}
L(θ)=t=1∑T(Vtπ−θTx(st))2
对参数求导,令导数为0:
−
∂
L
(
θ
)
∂
θ
=
2
∑
t
=
1
T
(
V
t
π
−
θ
T
x
(
s
t
)
)
x
(
s
t
)
=
0
-frac{partial L(boldsymbol{theta})}{partial boldsymbol{theta}}=2 sum_{t=1}^{T}left(V_{t}^{pi}-boldsymbol{theta}^{mathrm{T}} boldsymbol{x}left(boldsymbol{s}_{t}right)right) boldsymbol{x}left(boldsymbol{s}_{t}right)=0
−∂θ∂L(θ)=2t=1∑T(Vtπ−θTx(st))x(st)=0
3.蒙特卡罗参数为
θ
=
(
∑
t
=
1
T
x
(
s
t
)
x
(
s
t
)
T
)
−
1
∑
t
=
1
T
x
(
s
t
)
G
t
boldsymbol{theta}=left(sum_{t=1}^{T} boldsymbol{x}left(boldsymbol{s}_{t}right) boldsymbol{x}left(boldsymbol{s}_{t}right)^{mathrm{T}}right)^{-1} sum_{t=1}^{T} boldsymbol{x}left(boldsymbol{s}_{t}right) G_{t}
θ=(t=1∑Tx(st)x(st)T)−1t=1∑Tx(st)Gt
4.时序差分法参数为
θ
=
(
∑
t
=
1
T
x
(
s
t
)
(
x
(
s
t
)
−
γ
x
(
s
t
+
1
)
)
T
)
−
1
∑
t
=
1
T
x
(
s
t
)
R
t
+
1
boldsymbol{theta}=left(sum_{t=1}^{T} boldsymbol{x}left(boldsymbol{s}_{t}right)left(boldsymbol{x}left(boldsymbol{s}_{t}right)-gamma boldsymbol{x}left(boldsymbol{s}_{t+1}right)right)^{mathrm{T}}right)^{-1} sum_{t=1}^{T} boldsymbol{x}left(boldsymbol{s}_{t}right) R_{t+1}
θ=(t=1∑Tx(st)(x(st)−γx(st+1))T)−1t=1∑Tx(st)Rt+1
非线性逼近
非线性逼近主流方式是通过神经网络来进行实现,这一内容是重点,后面会详细解读。
DQN
DQN全称Deep Q-Network,从这里开始就进入到深度强化学习。
DQN创新点
DQN是基于Q-Learning,主要有做了三点创新。
1.使用深度神经网路从原始数据提取特征来近似动作值函数(Q函数)
这个就是非线性逼近。
DQN的神经网络结构是三个卷积层和两个全连接层。
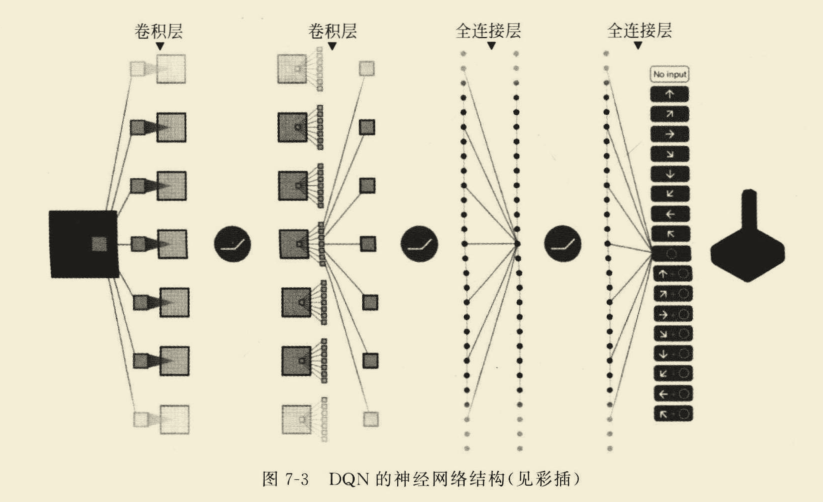
2.采用了经验回放机制
经验回放的设计是受到人脑中海马体的启发。人在与环境交互时,类似的经验不会直接吸收到大脑皮层,而是会存放到海马体(类似内存),在夜间会把一天的记忆重放给大脑皮层(硬盘)。
因此,DQN建立了一个数据库,每一次进行参数更新时,采用随机采样的方式从数据库中抽取数据,这样做的好处在于能够打破数据之间的关联,令神经网络的训练收敛且稳定。
3.设置单独的目标网络来处理TD偏差
利用神经网络对参数更新时,采用的是梯度下降法,更新公式如下:
θ
t
+
1
=
θ
t
+
α
(
r
+
γ
max
a
′
Q
(
s
′
,
a
′
;
θ
t
)
−
Q
(
s
,
a
;
θ
t
)
)
∇
Q
(
s
,
a
;
θ
t
)
boldsymbol{theta}_{t+1}=boldsymbol{theta}_{t}+alphaleft(r+gamma max _{a^{prime}} Qleft(boldsymbol{s}^{prime}, boldsymbol{a}^{prime} ; boldsymbol{theta}_{t}right)-Qleft(boldsymbol{s}, boldsymbol{a} ; boldsymbol{theta}_{t}right)right) nabla Qleft(s, boldsymbol{a} ; boldsymbol{theta}_{t}right)
θt+1=θt+α(r+γa′maxQ(s′,a′;θt)−Q(s,a;θt))∇Q(s,a;θt)
但是这样做存在一个问题,目标值和要更新的Q值共用同一个网络,这会导致每次更新后,目标也发生变化,从而导致训练不稳定。比如,猎人拿枪射猎物,每次射击猎物同时运动。
为了解决这一问题,使用了一个目标网络。起初目标网络是将原网络进行复制,之后每隔一段固定步数,目标网络再次进行复制,期间保持不变,这样就让目标稳定。
因此,参数的更新公式修改为:
θ
t
+
1
=
θ
t
+
α
(
r
+
γ
max
a
′
Q
(
s
′
,
a
′
;
θ
t
−
)
−
Q
(
s
,
a
;
θ
t
)
)
∇
Q
(
s
,
a
;
θ
t
)
boldsymbol{theta}_{t+1}=boldsymbol{theta}_{t}+alphaleft(r+gamma max _{a^{prime}} Qleft(boldsymbol{s}^{prime}, boldsymbol{a}^{prime} ; boldsymbol{theta}_{t}^{-}right)-Qleft(boldsymbol{s}, boldsymbol{a} ; boldsymbol{theta}_{t}right)right) nabla Qleft(boldsymbol{s}, boldsymbol{a} ; boldsymbol{theta}_{t}right)
θt+1=θt+α(r+γa′maxQ(s′,a′;θt−)−Q(s,a;θt))∇Q(s,a;θt)
DQN实例:Flappy Bird
下面将通过一个实例,从编程的角度来更深入的理解DQN。
2022.4.10
目前暂时更到这里,后面还有策略梯度,DDQN,DDPG,A2C等更复杂的网络,待日后研究透彻再更新。
最后
以上就是矮小菠萝最近收集整理的关于【强化学习】理论知识整理汇总前言策略预测与控制贝尔曼方程策略评估策略改进动态规划蒙特卡罗同轨策略/离轨策略时序差分三种方式对比SarsaQ-learningSarsa/Q-learning实例多步TD评估TD( λ \lambda λ)资格迹值函数逼近DQN的全部内容,更多相关【强化学习】理论知识整理汇总前言策略预测与控制贝尔曼方程策略评估策略改进动态规划蒙特卡罗同轨策略/离轨策略时序差分三种方式对比SarsaQ-learningSarsa/Q-learning实例多步TD评估TD( 内容请搜索靠谱客的其他文章。


![行为型-策略模式案例 Comparator: Arrays.sort(T[], Comparator)案例 Spring 后置处理器: applyBeanPostProcessorsBeforeInstantiation案例 spring ApplicationContextAware案例 spring @Enable XXX](https://www.shuijiaxian.com/files_image/reation/bcimg15.png)





发表评论 取消回复