主机设置
- 修改主机名:
hostnamectl set-hostname <目标修改名> - 查看主机名:
hostname
防火墙设置
- 查看防火墙状态:
systemctl status firewalld - 关闭防火墙:
systemctl stop firewalld - 禁用防火墙:
systemctl disable firewalld
免密登录设置
- 生成密匙对:
ssh-keygen -t rsa(一直enter) - 拷贝密匙对:
ssh-copy-id root@<目标主机名> - 免密登录:
ssh <目标主机名>
Hadoop部署模式
- 独立模式
- 在独立模式下,所有程序都在单个JVM上执行,调试Hadoop集群的MapReduce程序也非常方便。一般情况下,该模式常用于学习或开发阶段进行调试程序
- 伪分布模式
- 在伪分布式模式下, Hadoop程序的守护进程都运行在一台节点上,该模式主要用于调试Hadoop分布式程序的代码,以及程序执行是否正确。伪分布式模式是完全分布式模式的一个特例。
- 完全分布模式
- 在完全分布式模式下,Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色,在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
Java安装与配置
- 下载JDK:pass
- 解压JDK:
tar -zxvf jdk-8u231-linux-x64.tar.gz -C <目标目录> - 配置环境变量:
vim /etc/profile
export JAVA_HOME=/usr/local/<jdk版本号,安装目录下查看>
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 环境生效:
source /etc/profile - 查看JDK版本:
java -version
Hadoop 安装与配置
- 下载Hadoop:hadoop-3.3.4
- 解压Hadoop:
tar -xzvf hadoop-3.3.4.tar.gz -C <目标目录> - 配置环境变量:
vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 环境生效:
source /etc/profile - 查看Hadoop版本:
hadoop version - Hadoop集群配置文件:
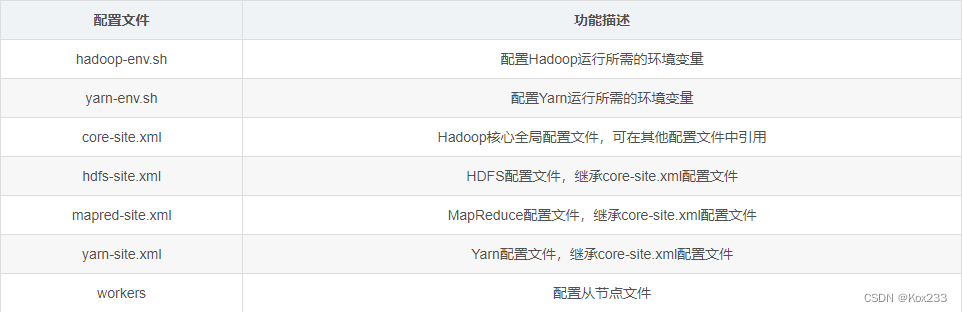
- 进入hadoop配置文件目录:
cd $HADOOP_HOME/etc/hadoop - hadoop-env.sh:
vim hadoop-env.sh
export JAVA_HOME=/usr/local/<jdk版本号,安装目录下查看>
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- core-site.xml:
vim core-site.xml
<configuration>
<!--用来指定hdfs的老大-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.4/tmp</value>
</property>
</configuration>
- hdfs-site.xlm:
vim hdfs-site.xml
<configuration>
<!--设置名称节点的目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop-3.3.4/tmp/namenode</value>
</property>
<!--设置数据节点的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop-3.3.4/tmp/datanode</value>
</property>
<!--设置辅助名称节点-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!--hdfs web的地址,默认为9870,可不配置-->
<!--注意如果使用hadoop2,默认为50070-->
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
<!--副本数,默认为3,可不配置-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--是否启用hdfs权限,当值为false时,代表关闭-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
- yarn-site.xml:
vim yarn-site.xml
<configuration>
<!--配置资源管理器:集群master-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--配置节点管理器上运行的附加服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--关闭虚拟内存检测,在虚拟机环境中不做配置会报错-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
- 格式化文件系统:
hdfs namenode -format - 启动集群:
start-all.sh - 关闭集群:
stop-all.sh
最后
以上就是单纯小懒虫最近收集整理的关于Hadoop安装部署与测试的全部内容,更多相关Hadoop安装部署与测试内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复