以resnet作为前置网络的ssd目标提取检测
1.目标
本文的目标是将resnet结构作为前置网络,在imagenet数据集上进行预训练,随后将ssd目标提取检测网络(一部分)接在resnet前置网络之后,形成一个完整的ssd网络。
ssd网络下载和配置参考点击打开链接
2.resnet前置网络pretrain
2.1 利用imagenet数据生成lmdb,采用create_imagenet.sh生成,内容如下:
#!/usr/bin/env sh
# Create the imagenet lmdb inputs
# N.B. set the path to the imagenet train + val data dirs
set -e
EXAMPLE=models/resnet
DATA=/home/jzhang/data/VOCdevkit/VOC2007
TOOLS=build/tools
TRAIN_DATA_ROOT=/home/jzhang/data/VOCdevkit/VOC2007/JPEGImages/
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool.
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=224
RESIZE_WIDTH=224
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path"
"where the ImageNet training data is stored."
exit 1
fi
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset
--resize_height=$RESIZE_HEIGHT
--resize_width=$RESIZE_WIDTH
--shuffle
$TRAIN_DATA_ROOT
$DATA/train.txt
$EXAMPLE/resnet_train_lmdb
echo "Done."
train.txt的内容大致如下:
000001.jpg 0
000002.jpg 1
000003.jpg 2
000004.jpg 3
000005.jpg 4
000006.jpg 5
000007.jpg 6
000008.jpg 7
000009.jpg 8
000010.jpg 9
运行create_imagenet.sh后就会在EXAMPLE目录下生成lmdb文件夹,其中包含data.mdb和lock.mdb。这些都是caffe需要使用的数据格式。
2.2 编写solver和prototxt
先写各层网络结构的定义res_pretrain.prototxt:
name: "ResNet-50"
layer {
name: "imagenet"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
data_param {
source: "models/resnet/resnet_train_lmdb" //刚才产生的train的lmdb
batch_size: 8
backend: LMDB
}
}
layer {
name: "imagenet"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
data_param {
source: "models/resnet/resnet_test_lmdb" //同理可以产生的test的lmdb
batch_size: 1
backend: LMDB
}
}
/
resnet结构
/
layer {
bottom: "data"
top: "conv1"
name: "conv1"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 7
pad: 3
stride: 2
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "bn_conv1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "scale_conv1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "conv1_relu"
type: "ReLU"
}
layer {
bottom: "conv1"
top: "pool1"
name: "pool1"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: MAX
}
}
layer {
bottom: "pool1"
top: "res2a_branch1"
name: "res2a_branch1"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2a_branch1"
top: "res2a_branch1"
name: "bn2a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
//...............................
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2a"
name: "bn5c_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2a"
name: "scale5c_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2a"
name: "res5c_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2b"
name: "res5c_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2b"
name: "bn5c_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2b"
name: "scale5c_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2b"
name: "res5c_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2c"
name: "res5c_branch2c"
type: "Convolution"
convolution_param {
num_output: 2048
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res5c_branch2c"
top: "res5c_branch2c"
name: "bn5c_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5c_branch2c"
top: "res5c_branch2c"
name: "scale5c_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5b"
bottom: "res5c_branch2c"
top: "res5c"
name: "res5c"
type: "Eltwise"
}
layer {
bottom: "res5c"
top: "res5c"
name: "res5c_relu"
type: "ReLU"
}
layer {
bottom: "res5c"
top: "pool5"
name: "pool5"
type: "Pooling"
pooling_param {
kernel_size: 7
stride: 1
pool: AVE
}
}
layer {
bottom: "pool5"
top: "fc1000"
name: "fc1000"
type: "InnerProduct"
inner_product_param {
num_output: 1000
}
}
//loss function
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc1000"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc1000"
bottom: "label"
top: "loss"
}
写好了网络层的prototxt之后,写solver,res_pretrain_solver.prototxt内容如下:
net: "models/resnet/res_pretrain.prototxt" //上一步中写的网络层次结构
test_iter: 10
test_interval: 10
base_lr: 0.01 //基础学习率 learning-rate
lr_policy: "step" //学习策略
gamma: 0.1
stepsize: 100000
display: 20
max_iter: 450000 //迭代次数
momentum: 0.9 //学习率衰减系数
weight_decay: 0.0005 //权重衰减系数,防止过拟合
snapshot: 1000 //每1000次迭代保存一次参数中间结果
snapshot_prefix: "models/resnet/resnet_train"
solver_mode: CPU2.3 进行pretrain训练
在caffe目录下运行
./build/tools/caffe train --solver=models/resnet/res_pretrain_solver.prototxt
solver=之后写的是上面的prototxt地址。
至此,在imagenet上的预训练到此为止。训练之后会生成一个caffemodel,这就是之后需要接到ssd之前网络的参数。
3.接入ssd网络
ssd网络finetuning的流程与之前pretrain基本一致。
3.1
产生lmdb
ssd使用的lmdb与之前略有不同。
其train.txt文件下不再是图片对应类型,因为有boundingbox的存在, 所以一个图片对应一个xml文件,如下:
VOC2007/JPEGImages/000001.jpg VOC2007/Annotations/000001.xml
VOC2007/JPEGImages/000002.jpg VOC2007/Annotations/000002.xml
VOC2007/JPEGImages/000003.jpg VOC2007/Annotations/000003.xml
VOC2007/JPEGImages/000004.jpg VOC2007/Annotations/000004.xml
VOC2007/JPEGImages/000006.jpg VOC2007/Annotations/000006.xml
VOC2007/JPEGImages/000008.jpg VOC2007/Annotations/000008.xml
VOC2007/JPEGImages/000010.jpg VOC2007/Annotations/000010.xml
VOC2007/JPEGImages/000011.jpg VOC2007/Annotations/000011.xml
VOC2007/JPEGImages/000013.jpg VOC2007/Annotations/000013.xml
VOC2007/JPEGImages/000014.jpg VOC2007/Annotations/000014.xmlcd $root_dir
redo=1
data_root_dir="$HOME/data/VOCdevkit"
dataset_name="VOC0712"
mapfile="$root_dir/data/$dataset_name/labelmap_voc.prototxt"
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
do
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim
--resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir $root_dir/data/$dataset_name/$subset.txt
$data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name
done
3.2 编写solver和prototxt
首先定义ssd网络层次结构ssd_finetuning.prototxt:
//ssd中输入层的定义非常复杂,但其中只有一些需要改动,其余的照搬就行
layer {
name: "data"
type: "AnnotatedData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
mean_value: 104
mean_value: 117
mean_value: 123
resize_param {
prob: 1
resize_mode: WARP
height: 300
width: 300
interp_mode: LINEAR
interp_mode: AREA
interp_mode: NEAREST
interp_mode: CUBIC
interp_mode: LANCZOS4
}
emit_constraint {
emit_type: CENTER
}
}
data_param {
source: "models/resnet/<span style="font-size:14px;">ssd_train_lmdb</span>" //刚才生成的新的lmdb
batch_size: 32
backend: LMDB
}
annotated_data_param {
batch_sampler {
max_sample: 1
max_trials: 1
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.1
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.3
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.5
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.7
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.9
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
max_jaccard_overlap: 1.0
}
max_sample: 1
max_trials: 50
}
label_map_file: "data/VOC0712/labelmap_voc.prototxt"
}
}
//resnet结构
layer {
bottom: "data"
top: "conv1"
name: "conv1"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 7
pad: 3
stride: 2
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "bn_conv1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "data"
top: "conv1"
name: "conv1"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 7
pad: 3
stride: 2
}
}
//省略很多resnet层
layer {
bottom: "res5c"
top: "res5c"
name: "res5c_relu"
type: "ReLU"
}
layer {
bottom: "res5c"
top: "pool5"
name: "pool5"
type: "Pooling"
pooling_param {
kernel_size: 7
stride: 1
pool: AVE
}
}
//至此resnet主体结构完成,随后接上ssd的结构
//用pool5作为bottom分别产生mbox_loc/mbox_conf/mbox_priorbox
layer {
name: "pool5_mbox_loc"
type: "Convolution"
bottom: "pool5" //选取pool5作为bottom,产生mbox_loc
top: "pool5_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "pool5_mbox_loc_perm" //将上一层产生的mbox_loc重新排序
type: "Permute"
bottom: "pool5_mbox_loc"
top: "pool5_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "pool5_mbox_loc_flat" //将上一层展平(例如7*7的展平成1*49,方便之后的拼接)
type: "Flatten"
bottom: "pool5_mbox_loc_perm"
top: "pool5_mbox_loc_flat"
flatten_param {
axis: 1
}
}
layer {
name: "pool5_mbox_conf"
type: "Convolution"
bottom: "pool5" //选取pool5作为bottom,产生mbox_conf(之后的排序展平同理)
top: "pool5_mbox_conf"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 126
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "pool5_mbox_conf_perm"
type: "Permute"
bottom: "pool5_mbox_conf"
top: "pool5_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "pool5_mbox_conf_flat"
type: "Flatten"
bottom: "pool5_mbox_conf_perm"
top: "pool5_mbox_conf_flat"
flatten_param {
axis: 1
}
}
layer {
name: "pool5_mbox_priorbox"
type: "PriorBox"
bottom: "pool5" //选取pool5作为bottom,产生mbox_priorbox(之后排序展平)
bottom: "data"
top: "pool5_mbox_priorbox"
prior_box_param {
min_size: 276.0
max_size: 330.0
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: true
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
}
}
//同理用res5c作为bottom分别产生mbox_loc/mbox_conf/mbox_priorbox
layer {
name: "res5c_mbox_loc"
type: "Convolution"
bottom: "res5c"
top: "res5c_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "res5c_mbox_loc_perm"
type: "Permute"
bottom: "res5c_mbox_loc"
top: "res5c_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "res5c_mbox_loc_flat"
type: "Flatten"
bottom: "res5c_mbox_loc_perm"
top: "res5c_mbox_loc_flat"
flatten_param {
axis: 1
}
}
layer {
name: "res5c_mbox_conf"
type: "Convolution"
bottom: "res5c"
top: "res5c_mbox_conf"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 126
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "res5c_mbox_conf_perm"
type: "Permute"
bottom: "res5c_mbox_conf"
top: "res5c_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "res5c_mbox_conf_flat"
type: "Flatten"
bottom: "res5c_mbox_conf_perm"
top: "res5c_mbox_conf_flat"
flatten_param {
axis: 1
}
}
layer {
name: "res5c_mbox_priorbox"
type: "PriorBox"
bottom: "res5c"
bottom: "data"
top: "res5c_mbox_priorbox"
prior_box_param {
min_size: 276.0
max_size: 330.0
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: true
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
}
}
//Concat层将刚才的res5c和pool5产生的mbox_loc/mbox_conf/mbox_priorbox拼接起来形成一个层
layer {
name: "mbox_loc"
type: "Concat"
bottom: "res5c_mbox_loc_flat"
bottom: "pool5_mbox_loc_flat"
top: "mbox_loc"
concat_param {
axis: 1
}
}
layer {
name: "mbox_conf"
type: "Concat"
bottom: "res5c_mbox_conf_flat"
bottom: "pool5_mbox_conf_flat"
top: "mbox_conf"
concat_param {
axis: 1
}
}
layer {
name: "mbox_priorbox"
type: "Concat"
bottom: "res5c_mbox_priorbox"
bottom: "pool5_mbox_priorbox"
top: "mbox_priorbox"
concat_param {
axis: 2
}
}
<span style="color:#ff0000;">//mbox_loc,mbox_conf,mbox_priorbox一起做的loss-function</span>
layer {
name: "mbox_loss"
type: "MultiBoxLoss"
bottom: "mbox_loc"
bottom: "mbox_conf"
bottom: "mbox_priorbox"
bottom: "label"
top: "mbox_loss"
include {
phase: TRAIN
}
propagate_down: true
propagate_down: true
propagate_down: false
propagate_down: false
loss_param {
normalization: VALID
}
multibox_loss_param {
loc_loss_type: SMOOTH_L1
conf_loss_type: SOFTMAX
loc_weight: 1.0
num_classes: 21
share_location: true
match_type: PER_PREDICTION
overlap_threshold: 0.5
use_prior_for_matching: true
background_label_id: 0
use_difficult_gt: true
do_neg_mining: true
neg_pos_ratio: 3.0
neg_overlap: 0.5
code_type: CENTER_SIZE
}
}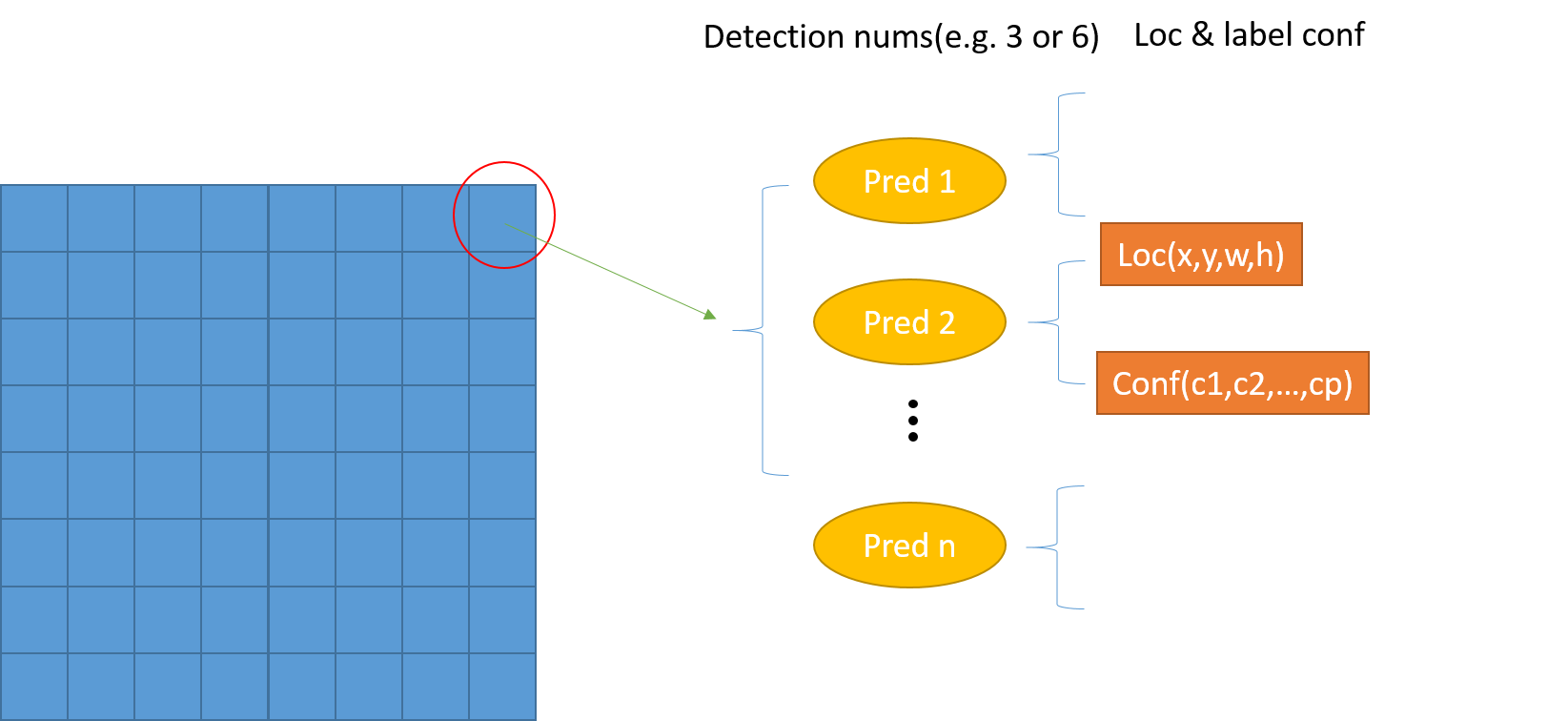
ssd中,mbox_loc层产生x,y,w,h四个值,mbox_conf对于每一个分类都有一个值,如果有20个分类,那就会产生20个值。
对于刚才的prototxt中,res5c层的尺寸为7*7,每一个像素会产生6个boundingbox,pool5层的尺寸为1*1,每一个像素会产生6个boundingbox。总共是7*7*6+1*1*6个候选的boundingbox。
如果需要增加候选的数量,那么就和pool5一样,在resnet中任意选取中间层randomlayer,在这些层之后加入randomlayer_mbox_loc/randomlayer_mbox_conf/randomlayer_mbox_priorbox,最终将这些层都展平并拼接在一起。
至此,ssd的整体网络结构prototxt已经编写完成。
对于solver,与之前没有什么区别,ssd_finetuning_solver:
net: "models/resnet/ssd_finetuning.prototxt"
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 100000
display: 20
max_iter: 450000
momentum: 0.9
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "models/resnet/resnet_train"
solver_mode: CPU3.3 训练网络
在caffe目录下运行:
./build/tools/caffe train --solver=models/resnet/ssd_finetuning_solver.prototxt -weights models/resnet/res_pretrain.caffemodel
solver=之后加solver地址, weights参数后加预训练pretrain中res_pretrain.caffemodel的参数。
至此,就将pretrain好的resnet网络接入了ssd前面。
最后
以上就是悦耳咖啡豆最近收集整理的关于以resnet作为前置网络的ssd目标提取检测的全部内容,更多相关以resnet作为前置网络内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复