数据结构与算法——双链表
文章目录
- 数据结构与算法——双链表
- 学习思路
- 双链表的基本结构
- 双链表的基本操作
- 定义双链表——C++版
- 插入结点
- 在某个结点后插入元素
- 在某个结点前插入元素
- 记忆方法
- 在头部插入元素s
- 在尾部插入元素s
- 删除结点
- 遍历元素
- 求长度
- 双链表的进阶操作
- 输出
- 销毁
- 头插法建表
- 尾插法建表
- 删除第i个元素
- 在第i个元素后插入值为value的元素
学习思路
与单链表一样,我还是建议用过掌握基础操作来拼凑成大的操作。
双链表的基本结构
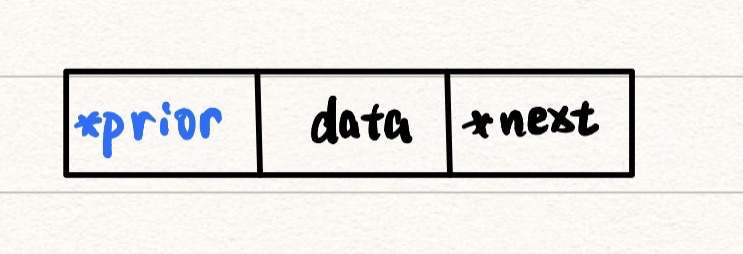
单链表指针域只有一个next指针,指向下一个结点,这就导致了它只能从前往后访问。为了弥补这一缺陷,我们可以往指针域里再加入一个指针prior,用于指向前面的结点,这样就可以实现双向访问了:
struct node{
int data;
node *next;
node *prior; //多一个前指针prior
};

双链表的基本操作
定义双链表——C++版
与单链表相似,创建双链表其实就是创建头指针,我们还是将初始化写在下面这个initList函数里:
void initList(node *&head){
head=new node();
head->next=NULL;
head->prior=NULL;
}
在此基础上,我们要定义一个双链表只需要:
node *head;
initList(head);
插入结点
在某个结点后插入元素
虽然双链表的prior指针使得逆向操作成为可能,但习惯期间,还是经常在某个节点之后插入新的结点,比如我要在p结点之后插入q结点,插入过程是这样的:
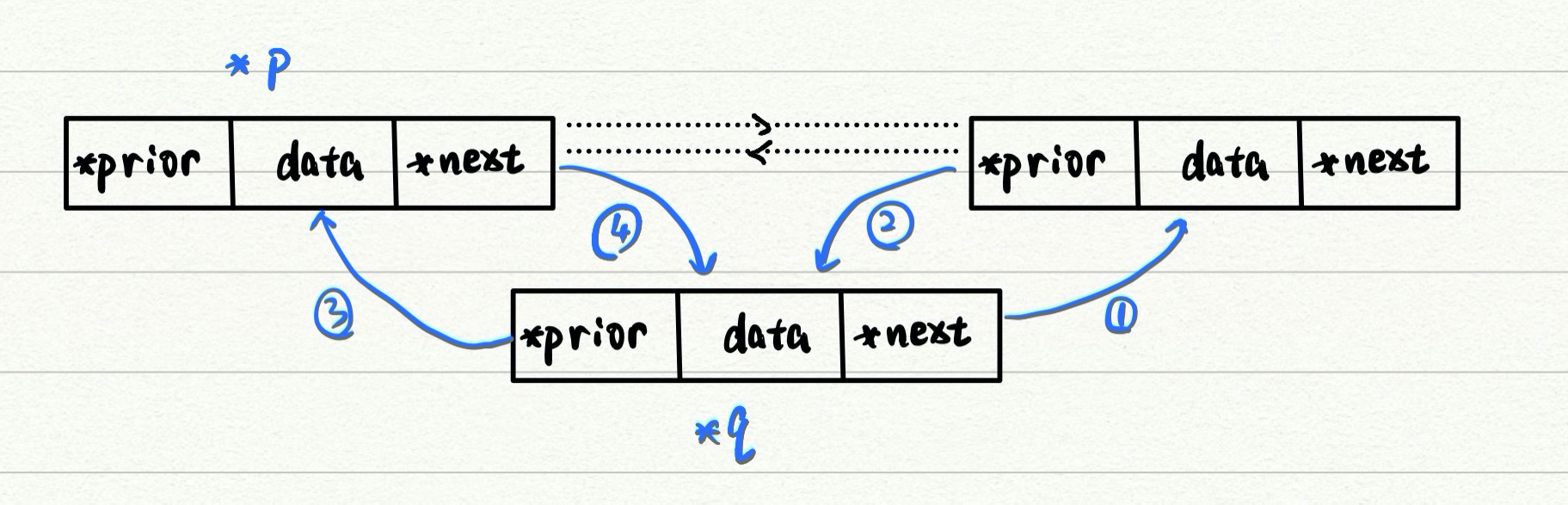
q->next=p->next; //1
if(p->next!=NULL) //判断p是不是尾结点
p->next->prior=q; //2
q->prior=p; //3
p->next=q; //4
在某个结点前插入元素
毕竟是双链表,思来想去还是决定把这个也写一下。在结点nxt之前插入p结点:
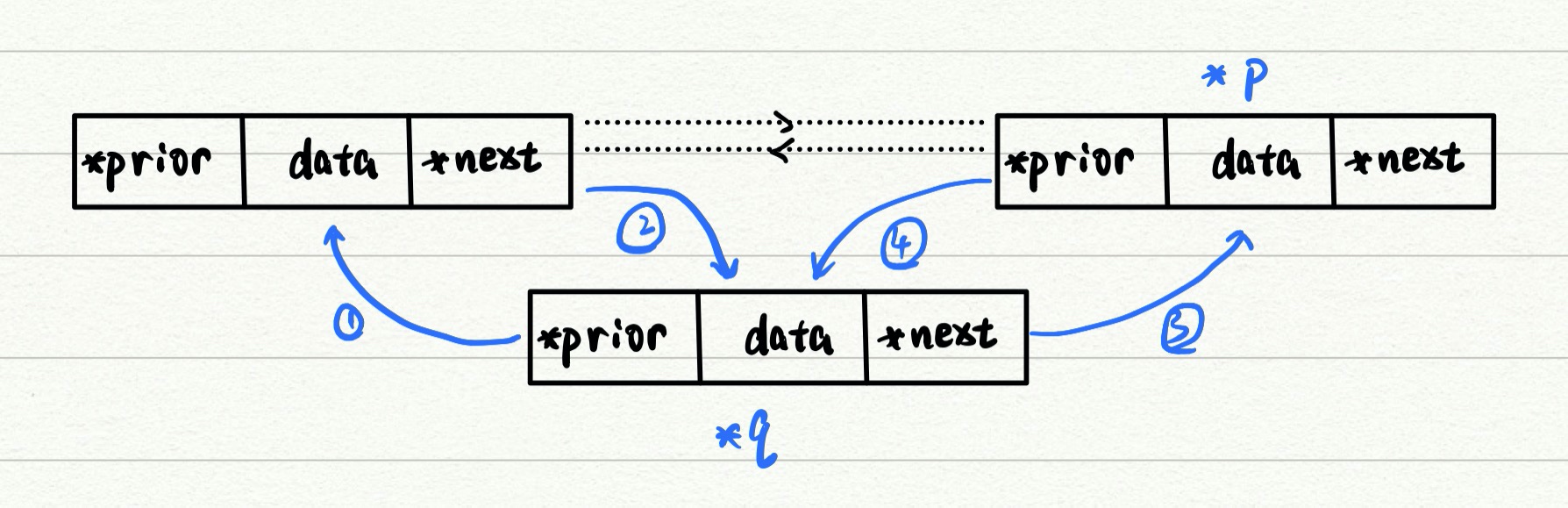
q->prior=p->prior;
if(p->prior!=NULL)
p->prior->next=q;
q->next=p;
p->prior=q;
记忆方法
发现规律没有?无论是往前插入结点,还是往后插入结点,都是只能用到待插入结点q和两个结点中的一个p,因此,我们称另一个没被用到的结点为打酱油的结点(一本正经)
无论是哪种插法,打酱油的结点总是最先被针对。因此我们只要再记住,每次q与p或q与酱油结点连接的过程中,都是q先动的手,就能顺利地记住连接顺序。
在头部插入元素s
s->next=head->next;
if(head->next!=NULL)
head->next->prior=s;
s->prior=head;
head->next=s;
在尾部插入元素s
s->data=a[i];
tail->next=s;
s->prior=tc;
tail=s;
删除结点
删除结点p的时候,我们可以将p前面的结点用p->prior表示,p后面的结点用p->next表示,也就是说代码里可以只有p
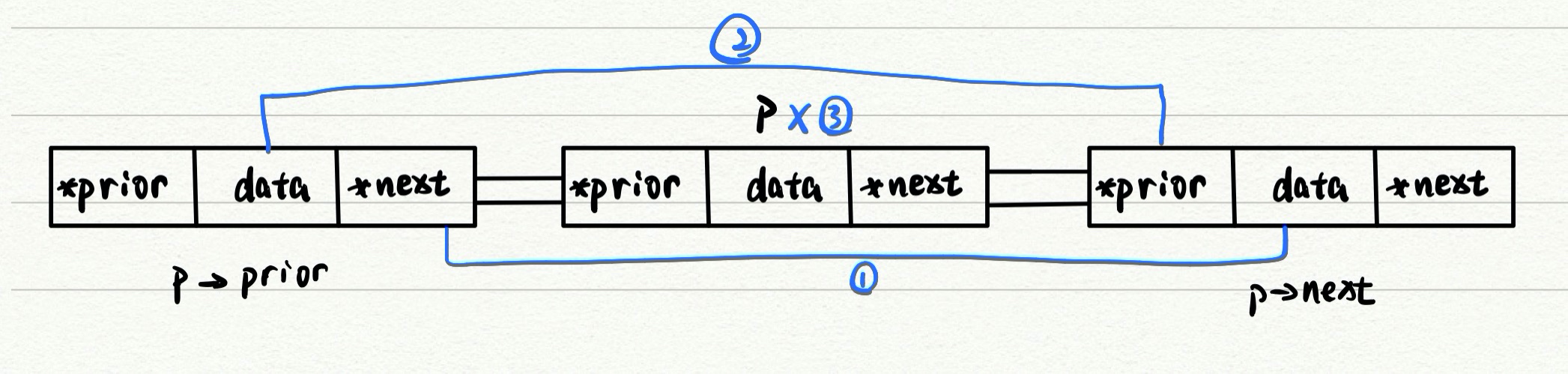
if(p->prior!=NULL) //判断p是不是第一个
p->prior->next=p->next; //1
if(p->next!=NULL) //判断p是不是最后一个
p->next->prior=p->prior; //2
delete p;
ps. 这里的1和2可以换顺序
遍历元素
与单链表几乎没啥区别
void findBro(node *head){
node *p=head; //工作指针
//或:node *p=head->next;
while(p!=NULL){ //判断当前的人是不是最底层小弟
//操作
p=p->next; //找他的小弟
}
}
求长度
int getLength(node *head){ //求长度
int count=0;
node *p=head->next; //工作指针
while(p!=NULL){
p=p->next;
count++;
}
return count;
}
双链表的进阶操作
基本都和单链表一样,只是在基本操作上有细微差别。只要把基本操作一换,大框架保持原样就好啦
输出
void output(node *head)
{
node *p=head->next;
while (p!=NULL){
cout<<p->data<<" ";
p=p->next;
}
cout<<endl;
}
销毁
void deleElem(node *&head,int i){ //删除第i个元素
int count=0;
node *p=head;
while(p!=NULL&&count!=i) //直接找第i个,改变它的指针域
count++,p=p->next;
node *pre=new node ();
pre=p->prior;
if(p->next!=NULL)
p->next->prior=pre;
pre->next=p->next;
delete p;
}
头插法建表
void createList_Head(node *&head,int a[],int len){
for(int i=0;i<len;i++){
node *s=new node ();
s->data=a[i];
s->next=head->next;
if(head->next!=NULL)
head->next->prior=s;
s->prior=head;
head->next=s;
}
}
尾插法建表
void createList_Tail(node *&head,int a[],int len){
node *tc=head;
for(int i=0;i<len;i++){
node *s=new node ();
s->data=a[i];
tc->next=s;
s->prior=tc;
tc=s;
}
tc->next=NULL;
}
删除第i个元素
void deleElem(node *&head,int i){ //删除第i个元素
int count=0;
node *p=head;
while(p!=NULL&&count!=i) //直接找第i个,改变它的指针域
count++,p=p->next;
node *pre=new node ();
pre=p->prior;
if(p->next!=NULL)
p->next->prior=pre;
pre->next=p->next;
delete p;
}
在第i个元素后插入值为value的元素
void insElem(node *&head,int value,int i){ //在第i个元素后插入元素,值为value
node *p=head;
int count=1;
while (p!=NULL&&count!=i) //找到第i-1个结点
count++,p=p->next;
node *q=new node ();
q->data=value;
q->next=p->next;
if(p->next!=NULL)
p->next->prior=q;
q->prior=p;
p->next=q;
}
最后
以上就是知性花生最近收集整理的关于数据结构与算法——双链表数据结构与算法——双链表的全部内容,更多相关数据结构与算法——双链表数据结构与算法——双链表内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复