一、Shell 操作
使用如下命令进入hbase 的shell 客户端,输入quit或exit退出
$ hbase shell
查看hbase 所有命令
$ help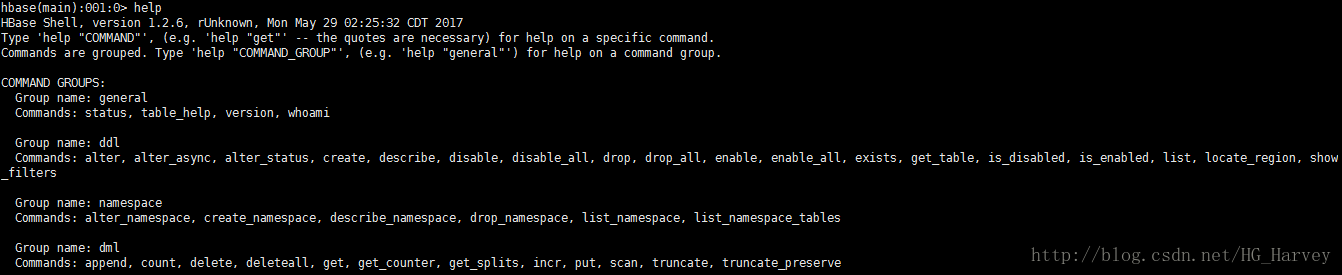
如果忘记了命令如何使用,使用help ‘命令’查看帮助文档,如下
hbase(main):048:0> help 'list'
List all tables in hbase. Optional regular expression parameter could
be used to filter the output. Examples:
hbase> list
hbase> list 'abc.*'
hbase> list 'ns:abc.*'
hbase> list 'ns:.*'常用命令操作
1.一般操作
| 作用 | 命令表达式 |
|---|---|
| 查看服务器状态 | status |
| 查看hbase 版本 | version |
| 查看当前用户 | whoami |
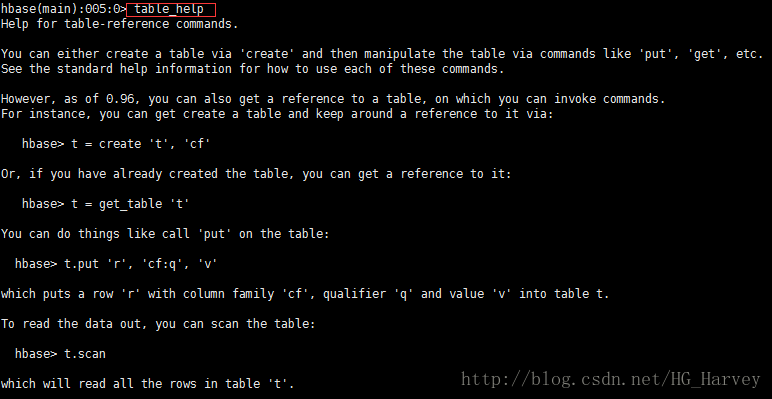
| 表引用命令提供帮助 | table_help |
1).查看服务器状态
hbase(main):002:0> status
1 active master, 1 backup masters, 3 servers, 0 dead, 1.0000 average load2).查看hbase 版本
hbase(main):003:0> version
1.2.6, rUnknown, Mon May 29 02:25:32 CDT 20173).查看当前用户
hbase(main):004:0> whoami
hadoop (auth:SIMPLE)
groups: hadoop, wheel4).表引用命令提供帮助
2.DDL操作(数据定义语言)
| 作用 | 命令表达式 |
|---|---|
| 创建表 | create ‘表名’, ‘列族名1’,’列族名2’,’列族名N’ |
| 查看表结构 | desc ‘表名’ 或 describe ‘表名’ |
| 判断表是否存在 | exists ‘表名’ |
| 判断是否禁用启用表 | is_enabled ‘表名’; is_disabled ‘表名’ |
| 禁用表 | disable ‘表名’ |
| 启用表 | enable ‘表名’ |
| 查看所有表 | list |
| 删除列族 | alter ‘表名’,’delete’=>’列族’ |
| 新增列族 | alter ‘表名’,NAME=>’列族’ |
| 删除单个表 | 先禁用表, 再删除表, 第一步disable ‘表名’,第二步 drop ‘表名’ |
| 批量删除表 | drop_all ‘正则表达式’ |
1).创建表
hbase(main):008:0> create 'students','info','address'
0 row(s) in 10.5040 seconds
=> Hbase::Table - students2).查看表结构
hbase(main):029:0> desc 'students'
Table students is ENABLED
students
COLUMN FAMILIES DESCRIPTION
{NAME => 'address', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VER
SIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIO
NS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.2450 seconds
hbase(main):030:0> describe 'students'
Table students is ENABLED
students
COLUMN FAMILIES DESCRIPTION
{NAME => 'address', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VER
SIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIO
NS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.2470 seconds3).判断表是否存在(exit)
hbase(main):011:0> exists 'students'
Table students does exist
0 row(s) in 0.0830 seconds4).判断是否禁用启用表(is_enabled,is_disabled)
is_enabled 是否启用、is_disabled 是否禁用
hbase(main):012:0> is_enabled 'students'
true
0 row(s) in 0.0690 seconds
hbase(main):013:0> is_disabled 'students'
false
0 row(s) in 0.0860 seconds5).禁用表(disable)
hbase(main):016:0> disable 'students'
0 row(s) in 2.6340 seconds
hbase(main):017:0> is_disabled 'students'
true
0 row(s) in 0.0520 seconds6).启用表(enable)
hbase(main):018:0> enable 'students'
0 row(s) in 2.5390 seconds
hbase(main):019:0> is_enabled 'students'
true
0 row(s) in 0.0860 seconds7).查看所有表(list)
hbase(main):020:0> list
TABLE
students
user
2 row(s) in 0.0400 seconds
=> ["students", "user"]8).删除列族(alter)
删除students表中的列族 address
hbase(main):024:0> alter 'students','delete'=>'address'
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 4.0260 seconds9).新增列族(alter)
students 表中新增列族address
hbase(main):027:0> alter 'students',NAME=>'address'
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 3.6260 seconds10).删除表(drop,drop_all)
注意:删除前必须先disable表,然后再使用drop删除
删除单个表使用drop,删除students表
hbase(main):031:0> disable 'students'
0 row(s) in 2.3640 seconds
hbase(main):032:0> drop 'students'
0 row(s) in 2.5820 seconds
hbase(main):033:0> exists 'students'
Table students does not exist
0 row(s) in 0.0850 seconds批量删除表使用drop_all,使用正则匹配,删除前先disable表,例如有如下表,删除所有以stu开头的表
hbase(main):038:0> list
TABLE
stu
students1
students2
user
3 row(s) in 0.0570 seconds
=> ["stu", "students1", "students2"]
hbase(main):041:0> disable_all 'stu.*'
stu
students1
students2
Disable the above 3 tables (y/n)?
y
3 tables successfully disabled2.DML 操作(数据操作语言)
| 作用 | 命令表达式 |
|---|---|
| 插入数据 | put ‘表名’,’rowkey’,’列族:列’,’列值’ |
| 获取某个列族 | get ‘表名’,’rowkey’,’列族’ |
| 获取某个列族的某个列 | get ‘表名’,’rowkey’,’列族:列’ |
| 全表扫描 | scan ‘表名’ |
| 查询表历史记录 | scan ‘表名’,{RAW => true,VERSION => 10} |
| 删除记录 | delete ‘表名’ ,‘rowkey’ , ‘列族:列’ |
| 删除整行 | deleteall ‘表名’,’rowkey’ |
| 清空表 | truncate ‘表名’ |
| 查看表中的记录总数 | count ‘表名’ |
1).插入数据(put)
hbase(main):003:0> put 'students','1001','info:name','zhangsan'
0 row(s) in 0.9800 seconds
hbase(main):006:0> put 'students','1001','info:sex','0'
0 row(s) in 0.0520 seconds
hbase(main):006:0> put 'students','1001','address:province','Henan'
0 row(s) in 0.1540 seconds
hbase(main):005:0> put 'students','1001','address:city','BeiJing'
0 row(s) in 0.3730 seconds
hbase(main):018:0> put 'students','1002','info:name','wangwu'
0 row(s) in 0.0690 seconds
hbase(main):019:0> put 'students','1003','info:sex','1'
0 row(s) in 0.0640 seconds2).更新数据(put)
- 更新行健为1001,列族为info,列为name的学生姓名为lisi
hbase(main):009:0> put 'students','1001','info:name','lisi'
0 row(s) in 0.1040 seconds
- 更新行健为1001,列族为address,列为province的学生省份为Hebei
hbase(main):011:0> put 'students','1001','address:province','Hebei'
0 row(s) in 0.0650 seconds
3).查询数据(get、scan)
根据rowkey获取:get
全表扫描:scan
- 获取行健为1001的学生信息
hbase(main):025:0> get 'students','1001'
COLUMN CELL
address:city timestamp=1502172494982, value=BeiJing
address:province timestamp=1502172919511, value=Hebei
info:name timestamp=1502172821032, value=lisi
info:sex timestamp=1502171941941, value=0
4 row(s) in 0.3110 seconds- 获取行健为1001且列族为address的学生信息
hbase(main):026:0> get 'students','1001','address'
COLUMN CELL
address:city timestamp=1502172494982, value=BeiJing
address:province timestamp=1502172919511, value=Hebei
2 row(s) in 0.0380 seconds- 获取行健为1001、列族为address、列为ciry的学生信息
hbase(main):027:0> get 'students','1001','address:city'
COLUMN CELL
address:city timestamp=1502172494982, value=BeiJing
1 row(s) in 0.1150 seconds- 获取所有的学生信息
hbase(main):028:0> scan 'students'
ROW COLUMN+CELL
1001 column=address:city, timestamp=1502172494982, value=BeiJing
1001 column=address:province, timestamp=1502172919511, value=Hebei
1001 column=info:name, timestamp=1502172821032, value=lisi
1001 column=info:sex, timestamp=1502171941941, value=0
1002 column=info:name, timestamp=1502173540238, value=wangwu
1003 column=info:sex, timestamp=1502173566515, value=1
3 row(s) in 0.1370 seconds4).删除数据
- 删除列族中的某个列
删除students表行健1001,列族为address,列为city的数据
hbase(main):036:0> delete 'students','1001','address:city'
0 row(s) in 0.1750 seconds删除前:

删除后:删除了列族中列city为BeiJing的数据

删除某个列族(参考DDL操作中的示例8)
删除整行数据
hbase(main):049:0> deleteall 'students','1002'
0 row(s) in 0.0510 seconds删除前:

删除后:删除了行健为1002的数据

使用scan 命令可以查看到students的历史记录,可以看到已被删除的列族,修改前的数据
scan 'students',{RAW => true,VERSION => 10}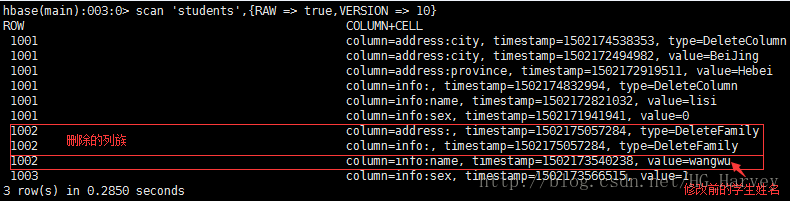
- 清空表中所有数据
hbase(main):010:0> truncate 'students'
Truncating 'students' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 5.5080 seconds
hbase(main):012:0> scan 'students'
ROW COLUMN+CELL
0 row(s) in 0.2060 seconds5).查看表中的总记录数(count)
hbase(main):001:0> count 'students'
2 row(s) in 1.7030 seconds
=> 2
hbase(main):002:0> scan 'students'
ROW COLUMN+CELL
1001 column=address:province, timestamp=1502172919511, value=Hebei
1001 column=info:name, timestamp=1502172821032, value=lisi
1001 column=info:sex, timestamp=1502171941941, value=0
1003 column=info:sex, timestamp=1502173566515, value=1
2 row(s) in 0.3620 seconds二、Java API 操作
HBase提供了Java API的访问接口,实际开发中我们经常用来操作HBase,就和我们通过Java API操作RDBMS一样。笔者对HBase 中的常用Java API做了个简要的总结,如下
| Java API | 作用 |
|---|---|
| HBaseAdmin | HBase 客户端,用来操作HBase |
| Configuration | 配置对象 |
| Connection | 连接对象 |
| TableName | HBase 中的表名 |
| HTableDescriptor | HBase 表描述信息对象 |
| HColumnDescriptor | HBase 列族描述对象 |
| Table | HBase 表对象 |
| Put | 用于插入数据 |
| Get | 用于查询单条记录 |
| Delete | 删除数据对象 |
| Scan | 全表扫描对象,查询所有记录 |
| ResultScanner | 查询数据返回结果集 |
| Result | 查询返回的单条记录结果 |
| Cell | 对应HBase中的列 |
| SingleColumnValueFilter | 列值过滤器(过滤列植的相等、不等、范围等) |
| ColumnPrefixFilter | 列名前缀过滤器(过滤指定前缀的列名) |
| multipleColumnPrefixFilter | 多个列名前缀过滤器(过滤多个指定前缀的列名) |
| RowFilter | rowKey过滤器(通过正则,过滤rowKey值) |
笔者针对上面提到的常用的 Java API 写了一个Demo,代码如下
package com.bigdata.study.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.ArrayList;
import java.util.List;
/**
* HBase Java API 操作
* 一般我们使用Java API 主要操作的是数据即DML操作,DDL的操作较少
*/
public class HBaseTest {
static Configuration conf = null;
private Connection conn = null;
private HBaseAdmin admin = null;
private TableName tableName = null;
private Table table = null;
// 初始化配置
@Before
public void init() throws Exception {
conf = HBaseConfiguration.create();
// 如果不设置zookeeper地址,可以将hbase-site.xml文件复制到resource目录下
conf.set("hbase.zookeeper.quorum","node3,node4,node5");// zookeeper 地址
// conf.set("hbase.zookeeper.property.clientPort","2188");// zookeeper 客户端端口,默认为2188,可以不用设置
conn = ConnectionFactory.createConnection(conf);// 创建连接
// admin = new HBaseAdmin(conf); // 已弃用,不推荐使用
admin = (HBaseAdmin) conn.getAdmin(); // hbase 表管理类
tableName = TableName.valueOf("students"); // 表名
table = conn.getTable(tableName);// 表对象
}
// --------------------DDL 操作 Start------------------
// 创建表 HTableDescriptor、HColumnDescriptor、addFamily()、createTable()
@Test
public void createTable() throws Exception {
// 创建表描述类
HTableDescriptor desc = new HTableDescriptor(tableName);
// 添加列族info
HColumnDescriptor family_info = new HColumnDescriptor("info");
desc.addFamily(family_info);
// 添加列族address
HColumnDescriptor family_address = new HColumnDescriptor("address");
desc.addFamily(family_address);
// 创建表
admin.createTable(desc);
}
// 删除表 先弃用表disableTable(表名),再删除表 deleteTable(表名)
@Test
public void deleteTable() throws Exception {
admin.disableTable(tableName);
admin.deleteTable(tableName);
}
// 添加列族 addColumn(表名,列族)
@Test
public void addFamily() throws Exception {
admin.addColumn(tableName, new HColumnDescriptor("hobbies"));
}
// 删除列族 deleteColumn(表名,列族)
@Test
public void deleteFamily() throws Exception {
admin.deleteColumn(tableName, Bytes.toBytes("hobbies"));
}
// --------------------DDL 操作 End---------------------
// ----------------------DML 操作 Start-----------------
// 添加数据 Put(列族,列,列值)(HBase 中没有修改,插入时rowkey相同,数据会覆盖)
@Test
public void insertData() throws Exception {
// 添加一条记录
// Put put = new Put(Bytes.toBytes("1001"));
// put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("San-Qiang Zhang"));
// put.addColumn(Bytes.toBytes("address"), Bytes.toBytes("province"), Bytes.toBytes("Hebei"));
// put.addColumn(Bytes.toBytes("address"), Bytes.toBytes("city"), Bytes.toBytes("Shijiazhuang"));
// table.put(put);
// 添加多条记录(批量插入)
List<Put> putList = new ArrayList<Put>();
Put put1 = new Put(Bytes.toBytes("1002"));
put1.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("Lisi"));
put1.addColumn(Bytes.toBytes("info"), Bytes.toBytes("sex"), Bytes.toBytes("1"));
put1.addColumn(Bytes.toBytes("address"), Bytes.toBytes("city"), Bytes.toBytes("Shanghai"));
Put put2 = new Put(Bytes.toBytes("1003"));
put2.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("Lili"));
put2.addColumn(Bytes.toBytes("info"), Bytes.toBytes("sex"), Bytes.toBytes("0"));
put2.addColumn(Bytes.toBytes("address"), Bytes.toBytes("city"), Bytes.toBytes("Beijing"));
Put put3 = new Put(Bytes.toBytes("1004"));
put3.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name_a"), Bytes.toBytes("Zhaosi"));
Put put4 = new Put(Bytes.toBytes("1004"));
put4.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name_b"), Bytes.toBytes("Wangwu"));
putList.add(put1);
putList.add(put2);
putList.add(put3);
putList.add(put4);
table.put(putList);
}
// 删除数据 Delete
@Test
public void deleteData() throws Exception {
// 删除一条数据(行健为1002)
// Delete delete = new Delete(Bytes.toBytes("1002"));
// table.delete(delete);
// 删除行健为1003,列族为info的数据
// Delete delete = new Delete(Bytes.toBytes("1003"));
// delete.addFamily(Bytes.toBytes("info"));
// table.delete(delete);
// 删除行健为1,列族为address,列为city的数据
Delete delete = new Delete(Bytes.toBytes("1001"));
delete.addColumn(Bytes.toBytes("address"), Bytes.toBytes("city"));
table.delete(delete);
}
// 单条查询 Get
@Test
public void getData() throws Exception {
Get get = new Get(Bytes.toBytes("1001"));
// get.addFamily(Bytes.toBytes("info")); //指定获取某个列族
// get.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name")); //指定获取某个列族中的某个列
Result result = table.get(get);
System.out.println("行健:" + Bytes.toString(result.getRow()));
byte[] name = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"));
byte[] sex = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex"));
byte[] city = result.getValue(Bytes.toBytes("address"), Bytes.toBytes("city"));
byte[] province = result.getValue(Bytes.toBytes("address"), Bytes.toBytes("province"));
if (name != null) System.out.println("姓名:" + Bytes.toString( name));
if (sex != null) System.out.println("性别:" + Bytes.toString( sex));
if (province != null) System.out.println("省份:" + Bytes.toString(province));
if (city != null) System.out.println("城市:" + Bytes.toString(city));
}
// 全表扫描 Scan
@Test
public void scanData() throws Exception {
Scan scan = new Scan(); // Scan 全表扫描对象
// 行健是以字典序排序,可以使用scan.setStartRow(),scan.setStopRow()设置行健的字典序
// scan.addFamily(Bytes.toBytes("info")); // 只查询列族info
//scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name")); // 只查询列name
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
}
// 全表扫描:列值过滤器(过滤列植的相等、不等、范围等) SingleColumnValueFilter
@Test
public void singleColumnValueFilter() throws Exception {
/**
* CompareOp 是一个枚举,有如下几个值
* LESS 小于
* LESS_OR_EQUAL 小于或等于
* EQUAL 等于
* NOT_EQUAL 不等于
* GREATER_OR_EQUAL 大于或等于
* GREATER 大于
* NO_OP 无操作
*/
// 查询列名大于San-Qiang Zhang的数据
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
Bytes.toBytes("info"), Bytes.toBytes("name"),
CompareFilter.CompareOp.EQUAL, Bytes.toBytes("San-Qiang Zhang"));
Scan scan = new Scan();
scan.setFilter(singleColumnValueFilter);
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
}
// 全表扫描:列名前缀过滤器(过滤指定前缀的列名) ColumnPrefixFilter
@Test
public void columnPrefixFilter() throws Exception {
// 查询列以name_开头的数据
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter(Bytes.toBytes("name_"));
Scan scan = new Scan();
scan.setFilter(columnPrefixFilter);
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
}
// 全表扫描:多个列名前缀过滤器(过滤多个指定前缀的列名) MultipleColumnPrefixFilter
@Test
public void multipleColumnPrefixFilter() throws Exception {
// 查询列以name_或c开头的数据
byte[][] bytes = new byte[][]{Bytes.toBytes("name_"), Bytes.toBytes("c")};
MultipleColumnPrefixFilter multipleColumnPrefixFilter = new MultipleColumnPrefixFilter(bytes);
Scan scan = new Scan();
scan.setFilter(multipleColumnPrefixFilter);
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
}
// rowKey过滤器(通过正则,过滤rowKey值) RowFilter
@Test
public void rowFilter() throws Exception {
// 匹配rowkey以100开头的数据
// Filter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^100"));
// 匹配rowkey以2结尾的数据
RowFilter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("2$"));
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
}
// 多个过滤器一起使用
@Test
public void multiFilterTest() throws Exception {
/**
* Operator 为枚举类型,有两个值 MUST_PASS_ALL 表示 and,MUST_PASS_ONE 表示 or
*/
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
// 查询性别为0(nv)且 行健以10开头的数据
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
Bytes.toBytes("info"), Bytes.toBytes("sex"),
CompareFilter.CompareOp.EQUAL, Bytes.toBytes("0"));
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^10"));
filterList.addFilter(singleColumnValueFilter);
filterList.addFilter(rowFilter);
Scan scan = new Scan();
scan.setFilter(rowFilter);
ResultScanner scanner = table.getScanner(scan);
// printResult1(scanner);
printResult2(scanner);
}
// --------------------DML 操作 End-------------------
/** 打印查询结果:方法一 */
public void printResult1(ResultScanner scanner) throws Exception {
for (Result result: scanner) {
System.out.println("行健:" + Bytes.toString(result.getRow()));
byte[] name = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"));
byte[] sex = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex"));
byte[] city = result.getValue(Bytes.toBytes("address"), Bytes.toBytes("city"));
byte[] province = result.getValue(Bytes.toBytes("address"), Bytes.toBytes("province"));
if (name != null) System.out.println("姓名:" + Bytes.toString( name));
if (sex != null) System.out.println("性别:" + Bytes.toString( sex));
if (province != null) System.out.println("省份:" + Bytes.toString(province));
if (city != null) System.out.println("城市:" + Bytes.toString(city));
System.out.println("------------------------------");
}
}
/** 打印查询结果:方法二 */
public void printResult2(ResultScanner scanner) throws Exception {
for (Result result: scanner) {
System.out.println("-----------------------");
// 遍历所有的列及列值
for (Cell cell : result.listCells()) {
System.out.print(Bytes.toString(CellUtil.cloneQualifier(cell)) + ":");
System.out.print(Bytes.toString(CellUtil.cloneValue(cell)) + "t");
}
System.out.println();
System.out.println("-----------------------");
}
}
// 释放资源
@After
public void destory() throws Exception {
admin.close();
}
}
最后
以上就是辛勤短靴最近收集整理的关于HBase Shell及JavaAPI操作的全部内容,更多相关HBase内容请搜索靠谱客的其他文章。








发表评论 取消回复