文章目录
- CAP定义
- 取舍策略
- 推导
- 结论
- 数据一致性
- 引用
CAP定义
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统有在以下三个特性[1]:
一致性(Consistency)
可用性(Availability)
分区容错性(Partition tolerance)
- (Particion tolerance)三者最多同时只能实现两点,无法三者兼顾
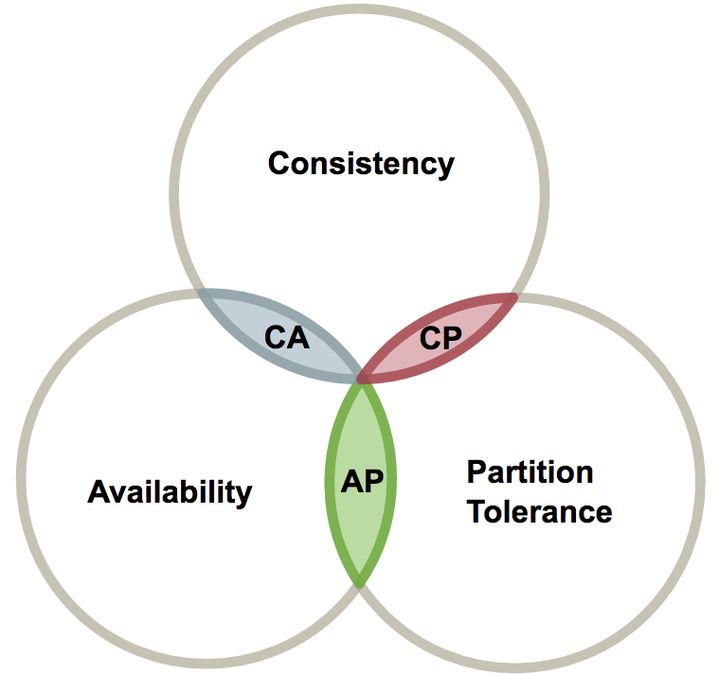
这三个特性最多只能同时实现两点,不可能三者兼顾,即出现 CA、CP、AP 三种情况。
-
一致性(C)
即更新操作成功后,所有节点在同一时间的数据完全一致,在并发读写时会出现这个问题。 -
可用性(A)
用户访问数据时,系统能在正常响应时间内返回结果。 -
分区容错性(P)
分布式系统在遇到某个节点或网络分区故障时,仍然能够对外提供满足一致性和可用性的服务。
也就是说部分故障不影响整体使用。
取舍策略
CAP三个特性只能满足其中两个,那么取舍的策略就共有三种:
-
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。传统的关系型数据库RDBMS:Oracle、MySQL就是CA。
-
CP without A:如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
-
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。典型的应用就如某米的抢购手机场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。
推导
- 如果要求对数据进行分区,就说明节点之间必须进行通信,涉及到通信,就无法保证在有限时间内完成指定任务
- 如果要求两个操作之间要完整的进行,因为涉及到通信,所以肯定存在某一个时刻之完成一部分的业务操作,在通信完成的这段时间内,数据不一致。
- 如果要求数据一致性,那么就必须在通信完成这段时间内保护数据,使得任何访问这些数据的操作不可用
结论
- 在大型网站中,数据是快速增加的,因此分区容错性必不可少。当数据变得庞大之后,网络和服务器会频繁出现故障,要想保证应用可用,必须把正分布式处理系统的高可用性。
- 在大型网站中,通常会选择强化分布式存储系统的可用性和伸缩性,在一定程度上放弃一致性。
数据一致性
-
强一致性(加锁)
- 一旦有写操作写入任何一个服务器,立即在其他服务器之间同步复制新的数据,这样任何服务器上任何读操作总是能看到最近写入的新数据。
-
弱一致性
- 和强一致性相对,系统并不保证连续进程或者线程的访问都会返回最新的更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。但会尽可能保证在某个时间级别(比如秒级别)之后,可以让数据达到一致性状态[2]。
-
最终一致性
- 属于弱一致性
- 应用于分布式系统中
- 当写入请求达到半数以上的时候,就认为是写入成功
引用
[1].https://leetcode-cn.com/circle/article/mMsOBF/
[2].https://www.jianshu.com/p/056c55935194
最后
以上就是火星上小蘑菇最近收集整理的关于CAP原则和数据一致性CAP定义取舍策略推导结论数据一致性引用的全部内容,更多相关CAP原则和数据一致性CAP定义取舍策略推导结论数据一致性引用内容请搜索靠谱客的其他文章。








发表评论 取消回复