一、基本知识:
1.基本术语
| 术语 | 英语单词 | 术语描述 |
| 内存屏障 | Memory barriers | 是一组处理器指令,用于实现对内存操作的顺序限制 |
| 缓冲行 | Cache line | 缓存中可以分配的最小存储单位。处理器填写缓存线时会加载整个缓存线,需要使用多个主内存读周期 |
| 原子操作 | Atomic operations | 不可中断的一个或一系列操作 |
| 缓存行填充 | Cache line fill | 当处理器识别到从内存中读取操作数可缓存的,处理器读取整个缓存行到适当的缓存(L1、L2、L3的或所有) |
| 缓存命中 | Cache hit | 如果进行高速缓存行填充操作的内存位置仍然是下次处理器访问的地址时,处理器从缓存中读取操作数,而不是从内存读取 |
| 写命中 | Write hit | 当处理器将操作数写回到一个内存缓存的区域时,它首先会检查这个缓存的内存地址是否在缓存行中,如果存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存,这个操作被称为写命中 |
| 写缺失 | Write misses the cache | 一个有效的缓存行被写入到不存在的内存区域 |
2.内存模型
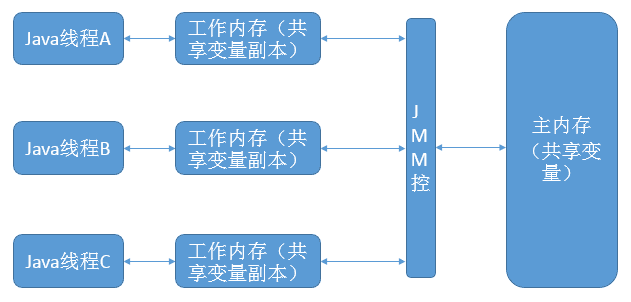
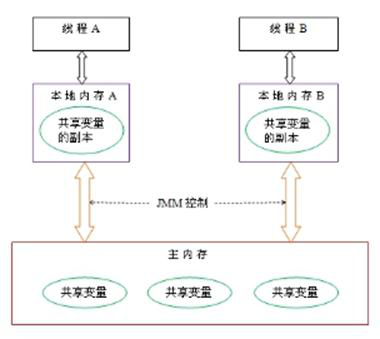
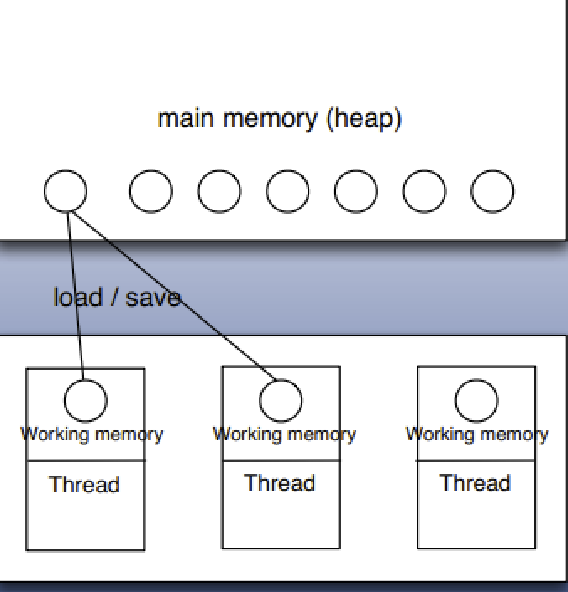
每一个线程有一个工作内存和主存独立
工作内存存放主存中变量的值的拷贝
Java内存模型规定了所有的变量都存储在主内存中。每条线程中还有自己的工作内存,线程的工作内存中保存了被该线程所使用到的变量(这些变量是从主内存中拷贝而来)。线程对变量的所有操作(读取,赋值)都必须在工作内存中进行。不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
举个简单的例子:在java中,执行下面这个语句:
i = 10;
执行线程必须先在自己的工作线程中对变量i所在的缓存行进行赋值操作,然后再写入主存当中。而不是直接将数值10写入主存当中。
比如同时有2个线程执行这段代码,假如初始时i的值为10,那么我们希望两个线程执行完之后i的值变为12。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的工作内存当中,然后线程1进行加1操作,然后把i的最新值11写入到内存。此时线程2的工作内存当中i的值还是10,进行加1操作之后,i的值为11,然后线程2把i的值写入内存。
最终结果i的值是11,而不是12。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
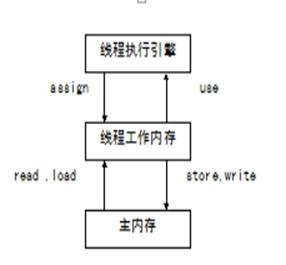
当数据从主内存复制到工作存储时,必须出现两个动作:
1.由主内存执行的读(read)操作;
2.由工作内存执行的相应的load操作;当数据从工作内存拷贝到主内存时,也出现两个操作:
1)由工作内存执行的存储(store)操作;
2)由主内存执行的相应的写(write)操作
每一个操作都是原子的,即执行期间不会被中断
对于普通变量,一个线程中更新的值,不能马上反应在其他变量中
如果需要在其他线程中立即可见,需要使用 volatile 关键字
注:CAS(Compare And Swap)
非阻塞同步指令之一,硬件指令集支持。先进行操作,如果有并发操作,则不断重试直到成功。
二、保存一致性可以使用一下几个修饰:
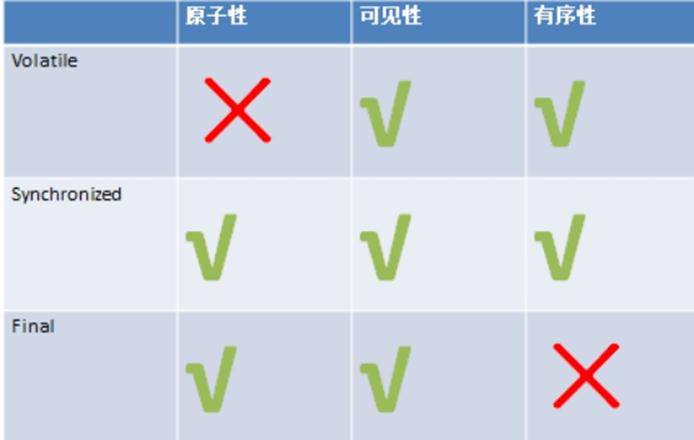
1.final不可变
作用于类、方法、成员变量、局部变量。初始化完成后的不可变对象,其它线程可见。常量不会改变不会因为其它线程产生影响。Final修饰的引用类型的地址不变,同时需要保证引用类型各个成员和操作的线程安全问题。因为引用类型成员可能是可变的。
2.synchronized同步
作用域代码块、方法上。通过线程互斥,同一时间的同样操作只允许一个线程操作。通过字节码指令实现。
3.Volatile
多线程的内存模型:main memory(主存)、working memory(线程栈),在处理数据时,线程会把值从主存load到本地栈,完成操作后再save回去(volatile关键词的作用:每次针对该变量的操作都激发一次load and save)。
(1)volatile 修饰的变量的变化保证对其它线程立即可见。
volatile变量的写,先发生于读。每次使用volatile修饰的变量个线程都会刷新保证变量一致性。但同步之前各线程可能仍有操作。(如:各个根据volatile变量初始值分别进行一些列操作,然后再同步写赋值。每个线程的操作有先后,当一个最早的线程给线程赋值时,其它线程同步。但这时其它线程可能根据初始值做了改变,同步的结果导致其它线程工作结果丢失。)
因此,根据volatile的语意使用条件:运算结果不依赖变量的当前值。
(2)volatile禁止指令重排优化。
这个语意导致写操作会慢一些。因为读操作跟这个没关系。
并发包概述
java.util.concurrent 包含许多线程安全、测试良好、高性能的并发构建块。不客气地说,创建java.util.concurrent 的目的就是要实现 Collection 框架对数据结构所执行的并发操作。通过提供一组可靠的、高性能并发构建块,开发人员可以提高并发类的线程安全、可伸缩性、性能、可读性和可靠性。
此包包含locks,concurrent,atomic 三个包。
1.Atomic:原子数据的构建。
2.Locks:基本的锁的实现,最重要的AQS框架和lockSupport
3.Concurrent:构建的一些高级的工具,如线程池,并发队列等。
其中都用到了CAS(compare-and-swap)操作。
CAS 是一种低级别的、细粒度的技术,它允许多个线程更新一个内存位置,同时能够检测其他线程的冲突并进行恢复。它是许多高性能并发算法的基础。在 JDK 5.0 之前,Java 语言中用于协调线程之间的访问的惟一原语是同步,同步是更重量级和粗粒度的。公开 CAS 可以开发高度可伸缩的并发 Java 类。这些更改主要由 JDK 库类使用,而不是由开发人员使用。
CAS操作都封装在java 不公开的类库中,sun.misc.Unsafe。此类包含了对原子操作的封装,具体用本地代码实现。本地的C代码直接利用到了硬件上的原子操作。
最后
以上就是默默钢笔最近收集整理的关于数据一致性如何保证?的全部内容,更多相关数据一致性如何保证内容请搜索靠谱客的其他文章。








发表评论 取消回复