以下内容分别转载或摘录自:
【1】松若章,你猜一个 TCP 连接上面能发多少个 HTTP 请求。
【2】烛秋,HTTP的长连接和短连接
【3】吴秦(Tyler),HTTP协议及其POST与GET操作差异 & C#中如何使用POST、GET等
【4】JanzzZ,粘包
【5】大老虎打老虎,tcp长连接分包方法
(一)一个 TCP 连接上面能发多少个 HTTP 请求
一道经典的面试题是从 URL 在浏览器被被输入到页面展现的过程中发生了什么,大多数回答都是说请求响应之后 DOM 怎么被构建,被绘制出来。但是你有没有想过,收到的 HTML 如果包含几十个图片标签,这些图片是以什么方式、什么顺序、建立了多少连接、使用什么协议被下载下来的呢?
要搞懂这个问题,我们需要先解决下面五个问题:
- 现代浏览器在与服务器建立了一个 TCP 连接后是否会在一个 HTTP 请求完成后断开?什么情况下会断开?
- 一个 TCP 连接可以对应几个 HTTP 请求?
- 一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
- 为什么有的时候刷新页面不需要重新建立 SSL 连接?
- 浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
先来谈谈第一个问题:现代浏览器在与服务器建立了一个 TCP 连接后是否会在一个 HTTP 请求完成后断开?什么情况下会断开?
在 HTTP/1.0 中,一个服务器在发送完一个 HTTP 响应后,会断开 TCP 链接。但是这样每次请求都会重新建立和断开 TCP 连接,代价过大。
所以虽然标准中没有设定,某些服务器对 Connection: keep-alive 的 Header 进行了支持。意思是说,完成这个 HTTP 请求之后,不要断开 HTTP 请求使用的 TCP 连接。
这样的好处是连接可以被重新使用,之后发送 HTTP 请求的时候不需要重新建立 TCP 连接,以及如果维持连接,那么 SSL 的开销也可以避免,两张图片是我短时间内两次访问 https://www.github.com 的时间统计:
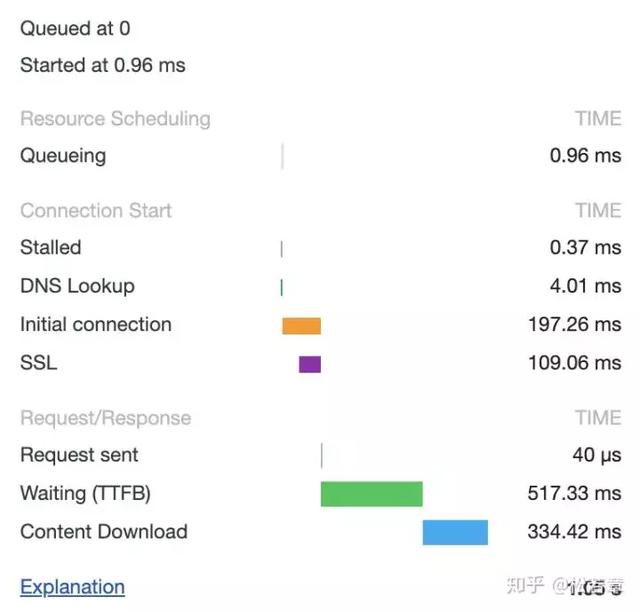
头一次访问,有初始化连接和 SSL 开销
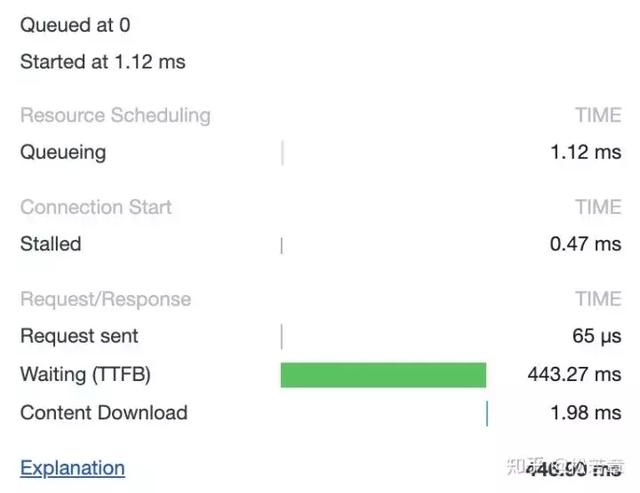
初始化连接和 SSL 开销消失了,说明使用的是同一个 TCP 连接
持久连接:既然维持 TCP 连接好处这么多,HTTP/1.1 就把 Connection 头写进标准,并且默认开启持久连接,除非请求中写明 Connection: close,那么浏览器和服务器之间是会维持一段时间的 TCP 连接,不会一个请求结束就断掉。
所以第一个问题的答案是:默认情况下建立 TCP 连接不会断开,只有在请求报头中声明 Connection: close 才会在请求完成后关闭连接。(详细文档见链接https://tools.ietf.org/html/rfc2616#section-8.1)
第二个问题:一个 TCP 连接可以对应几个 HTTP 请求?
了解了第一个问题之后,其实这个问题已经有了答案,如果维持连接,一个 TCP 连接是可以发送多个 HTTP 请求的。
第三个问题:一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
HTTP/1.1 存在一个问题,单个 TCP 连接在同一时刻只能处理一个请求,意思是说:两个请求的生命周期不能重叠,任意两个 HTTP 请求从开始到结束的时间在同一个 TCP 连接里不能重叠。
虽然 HTTP/1.1 规范中规定了 Pipelining 来试图解决这个问题,但是这个功能在浏览器中默认是关闭的。
先来看一下 Pipelining 是什么,RFC 2616 中规定了:
A client that supports persistent connections MAY “pipeline” its requests (i.e., send multiple requests without waiting for each response). A server MUST send its responses to those requests in the same order that the requests were received.一个支持持久连接的客户端可以在一个连接中发送多个请求(不需要等待任意请求的响应)。收到请求的服务器必须按照请求收到的顺序发送响应。
至于标准为什么这么设定,我们可以大概推测一个原因:由于 HTTP/1.1 是个文本协议,同时返回的内容也并不能区分对应于哪个发送的请求,所以顺序必须维持一致。
比如你向服务器发送了两个请求 GET /query?q=A 和 GET /query?q=B,服务器返回了两个结果,浏览器是没有办法根据响应结果来判断响应对应于哪一个请求的。
Pipelining 这种设想看起来比较美好,但是在实践中会出现许多问题:
- 一些代理服务器不能正确的处理 HTTP Pipelining。
- 正确的流水线实现是复杂的。详见HTTP 流水线。
- Head-of-line Blocking 连接头阻塞:在建立起一个 TCP 连接之后,假设客户端在这个连接连续向服务器发送了几个请求。按照标准,服务器应该按照收到请求的顺序返回结果,假设服务器在处理首个请求时花费了大量时间,那么后面所有的请求都需要等着首个请求结束才能响应。
所以现代浏览器默认是不开启 HTTP Pipelining 的。
但是,HTTP2 提供了 Multiplexing 多路传输特性,可以在一个 TCP 连接中同时完成多个 HTTP 请求。至于 Multiplexing 具体怎么实现的就是另一个问题了。我们可以看一下使用 HTTP2 的效果。
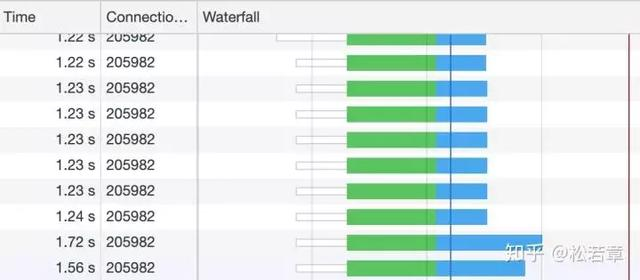
绿色是发起请求到请求返回的等待时间,蓝色是响应的下载时间,可以看到都是在同一个 Connection,并行完成的
所以这个问题也有了答案:在 HTTP/1.1 存在 Pipelining 技术可以完成这个多个请求同时发送,但是由于浏览器默认关闭,所以可以认为这是不可行的。在 HTTP2 中由于 Multiplexing 特点的存在,多个 HTTP 请求可以在同一个 TCP 连接中并行进行。
那么在 HTTP/1.1 时代,浏览器是如何提高页面加载效率的呢?主要有下面两点:
- 维持和服务器已经建立的 TCP 连接,在同一连接上顺序处理多个请求。
- 和服务器建立多个 TCP 连接。
第四个问题:为什么有的时候刷新页面不需要重新建立 SSL 连接?
在第一个问题的讨论中已经有答案了,TCP 连接有的时候会被浏览器和服务端维持一段时间。TCP 不需要重新建立,SSL 自然也会用之前的。
第五个问题:浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
假设我们还处在 HTTP/1.1 时代,那个时候没有多路传输,当浏览器拿到一个有几十张图片的网页该怎么办呢?肯定不能只开一个 TCP 连接顺序下载,那样用户肯定等的很难受,但是如果每个图片都开一个 TCP 连接发 HTTP 请求,那电脑或者服务器都可能受不了,要是有 1000 张图片的话总不能开 1000 个TCP 连接吧,你的电脑同意 NAT 也不一定会同意。
所以答案是:有。Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。(https://developers.google.com/web/tools/chrome-devtools/network/issues#queued-or-stalled-requests)
那么回到最开始的问题,收到的 HTML 如果包含几十个图片标签,这些图片是以什么方式、什么顺序、建立了多少连接、使用什么协议被下载下来的呢?
如果图片都是 HTTPS 连接并且在同一个域名下,那么浏览器在 SSL 握手之后会和服务器商量能不能用 HTTP2,如果能的话就使用 Multiplexing 功能在这个连接上进行多路传输。
不过也未必会所有挂在这个域名的资源都会使用一个 TCP 连接去获取,但是可以确定的是 Multiplexing 很可能会被用到。
如果发现用不了 HTTP2 呢?或者用不了 HTTPS(现实中的 HTTP2 都是在 HTTPS 上实现的,所以也就是只能使用 HTTP/1.1)。
那浏览器就会在一个 HOST 上建立多个 TCP 连接,连接数量的最大限制取决于浏览器设置,这些连接会在空闲的时候被浏览器用来发送新的请求,如果所有的连接都正在发送请求呢?那其他的请求就只能等等了。
(二)http连接(长连接)什么时候结束
1. 长连接的过期时间
客户端的长连接不可能无限期的拿着,会有一个超时时间,服务器有时候会告诉客户端超时时间,譬如:
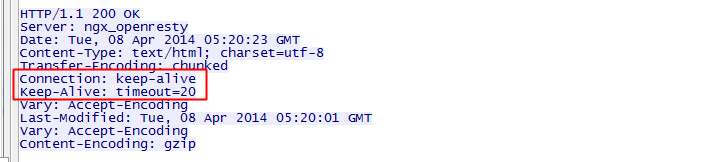
上图中的Keep-Alive: timeout=20,表示这个TCP通道可以保持20秒。另外还可能有max=XXX,表示这个长连接最多接收XXX次请求就断开。对于客户端来说,如果服务器没有告诉客户端超时时间也没关系,服务端可能主动发起四次挥手断开TCP连接,客户端能够知道该TCP连接已经无效;另外TCP还有心跳包来检测当前连接是否还活着,方法很多,避免浪费资源。
2. 即使关闭/刷新了该标签页,其对应的连接依然会保持(连接是"浏览器"那个进程维护的, 而非标签页的进程),所以只有关闭浏览器才会断开连接。
(三)请求方法和状态码
1. HTTP请求方法
(1)HTTP/1.1协议中共定义了八种方法来表明Request-URI指定的资源的不同操作方式:
- OPTIONS :返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送'*'的请求来测试服务器的功能性。
- HEAD :向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
- GET :向特定的资源发出请求。注意:GET方法不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
- POST :向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
- PUT :向指定资源位置上传其最新内容。
- DELETE :请求服务器删除Request-URI所标识的资源。
- TRACE :回显服务器收到的请求,主要用于测试或诊断。
- CONNECT :HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed);当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
(2)get和post的区别:
- GET是从服务器上获取数据,POST是向服务器传送数据。
- GET是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段一一对应,在URL中可以看到。POST是通过HTTP POST机制,将表单内各个字段与其内容放置在HTML HEADER内一起传送到ACTION属性所指的URL地址。用户看不到这个过程。
- 对于GET方式,服务器端用Request.QueryString获取变量的值,对于POST方式,服务器端用Request.Form获取提交的数据。
- GET传送的数据量较小,不能大于2KB(这主要是因为受URL长度限制)。POST传送的数据量较大,一般被默认为不受限制。但理论上,限制取决于服务器的处理能力。
- GET安全性较低,POST安全性较高。因为GET在传输过程,数据被放在请求的URL中,而如今现有的很多服务器、代理服务器或者用户代理都会将请求URL记录到日志文件中,然后放在某个地方,这样就可能会有一些隐私的信息被第三方看到。另外,用户也可以在浏览器上直接看到提交的数据,一些系统内部消息将会一同显示在用户面前。POST的所有操作对用户来说都是不可见的。
在FORM提交的时候,如果不指定Method,则默认为GET请求(.net默认是POST),Form中提交的数据将会附加在url之后,以?分开与url分开。字母数字字符原样发送,但空格转换为“+”号,其它符号转换为%XX,其中XX为该符号以16进制表示的ASCII(或ISO Latin-1)值。GET提交的数据放置在HTTP请求协议头中,而POST提交的数据则放在实体数据中;GET方式提交的数据最多只能有2048字节,而POST则没有此限制。POST传递的参数在doc里,也就http协议所传递的文本,接受时再解析参数部分,获得参数。一般用POST比较好。POST提交数据是隐式的,GET是通过在url里面传递的,用来传递一些不需要保密的数据,GET是通过在URL里传递参数,POST不是。
2. 状态码
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
(四)长连接如何分包
1. 粘包
(1)粘包的概念
粘包:多个数据包被连续存储于连续的缓存中,在对数据包进行读取时由于无法确定发生方的发送边界,而采用某一估测值大小来进行数据读出,若双方的size不一致时就会使指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。
(2)出现粘包的原因
出现粘包现象的原因是多方面的,它既可能由发送方造成,也可能由接收方造成。
发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一包数据。若连续几次发送的数据都很少,通常TCP会根据优化算法把这些数据合成一包后一次发送出去,这样接收方就收到了粘包数据。
接收方引起的粘包是由于接收方用户进程不及时接收数据,从而导致粘包现象。这是因为接收方先把收到的数据放在系统接收缓冲区,用户进程从该缓冲区取数据,若下一包数据到达时前一包数据尚未被用户进程取走,则下一包数据放到系统接收缓冲区时就接到前一包数据之后,而用户进程根据预先设定的缓冲区大小从系统接收缓冲区取数据,这样就一次取到了多包数据。
2. 长连接分包的方法
- 消息长度固定
- 使用特殊的字符串作为消息边界。比如http协议的headers以“rn”为字段的分隔符
- 在每条消息的头部加一个长度字段。这是最常见的
- 利用消息本身的格式来分包。比如xml中的<root></root>的配对等
最后
以上就是故意爆米花最近收集整理的关于HTTP - 长连接(Keep-Alive)模式的全部内容,更多相关HTTP内容请搜索靠谱客的其他文章。








发表评论 取消回复