本文笔者将用具体例子讲述决策树的构建过程,分析:决策树生成过程中有什么样的问题?

一、基本概念
决策树的定义:
首先,决策树是一种有监督的分类算法——即给定X,Y值,构建X,Y的映射关系。
不同于线性回归等是多项式,决策树是一种树形的结构,一般由根节点、父节点、子节点、叶子节点构成如图所示。
父节点和子节点是相对的,子节点可以由父节点分裂而来,而子节点还能作为新的父节点继续分裂;根节点是没有父节点,即初始分裂节点,叶子节点是没有子节点的节点,为终节点。
每一个分支代表着一个判断,每个叶子节点代表一种结果。
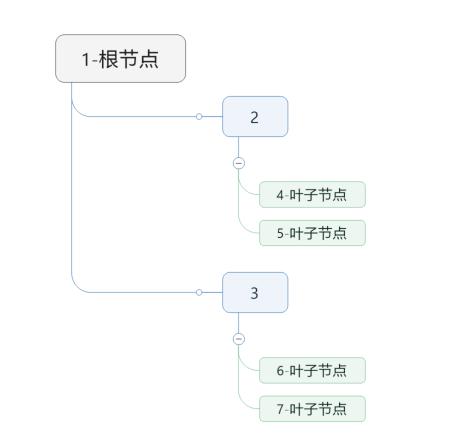
这是在已知各种情况的发生的概率的基础上,通过构建决策树来进行分析的一种方式。
预测方式:
- 根据输入的样本X的特征属性和决策树的取值,将输入的X样本分配到某一个叶子节点中。
- 将叶子节点中出现最多的Y值,作为输入的X样本的预测类别。
目的:
最优的模型应该是:叶子节点中只包含一个类别的数据。
但是,事实是不可能将数据分的那么的纯,因此,需要“贪心”策略,力争在每次分割时都比上一次好一些,分的更纯一些。
二、决策树构建过程
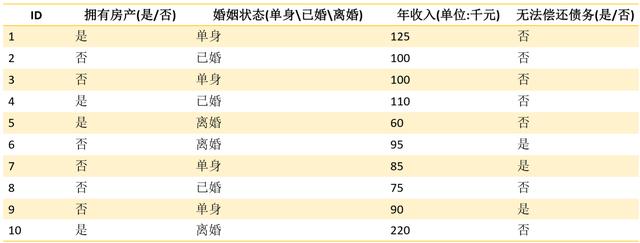
步骤一:将所有的特征看成一个一个的节点,eg(拥有房产、婚姻状态、年收入这些特征,我们可以看成一个一个的节点。)
步骤二:遍历当前特征的每一种分割方式,找到最好的分割点eg(婚姻状态这个特征,我们可以按照单身、已婚、离婚进行划分;也可以按照结过婚、没有结过婚进行划分);将数据划分为不同的子节点,eg: N1、 N2….Nm;计算划分之后所有子节点的“纯度”信息
步骤三:使用第二步遍历所有特征,选择出最优的特征,以及该特征的最优的划分方式,得出最终的子节点N1、 N2….Nm
步骤四:对子节点N1、N2….Nm分别继续执行2-3步,直到每个最终的子节点都足够“纯”。
从上述步骤可以看出,决策生成过程中有两个重要的问题:
- 对数据进行分割。
- 选择分裂特征。
- 什么时候停止分裂。
1. 对数据进行分割
根据属性值的类型进行划分:
如果值为离散型,且不生成二叉决策树,则此时一个属性就是可以一个分支,比如:上图数据显示,婚姻状态为一个属性,而下面有三个值,单身、已婚、离婚,则这三个值都可以作为一个分类。
如果值为离散型,且生成二叉决策树,可以按照 “属于此子集”和“不属于此子集”分成两个分支。还是像上面的婚姻状态,这可以按照已婚,和非婚,形成两个分支。
如果值为连续性,可以确定一个值作为分裂点,按照大于分割点,小于或等于分割点生成两个分支,如上图数据,我可以按照6千元的点划分成:大于6千元和小于6千元。
2. 找到最好的分裂特征
决策树算法是一种“贪心”算法策略——只考虑在当前数据特征情况下的最好分割方式。
在某种意义上的局部最优解,也就是说我只保证在当分裂的时候,能够保证数据最纯就好。
对于整体的数据集而言:按照所有的特征属性进行划分操作,对所有划分操作的结果集的“纯度”进行比较,选择“纯度”越高的特征属性作为当前需要分割的数据集进行分割操作。
决策树使用信息增益作为选择特征的依据,公式如下:
H(D)为:分割前的纯度。
H(D|A)为:在给定条件A下的纯度,两者之差为信息增益度。如果信息增益度越大,则H(D|A)越小,则代表结果集的数据越纯。
计算纯度的度量方式:Gini、信息熵、错误率。
一般情况下,选择信息熵和Gini系数,这三者的值越大,表示越“不纯”。
Gini:
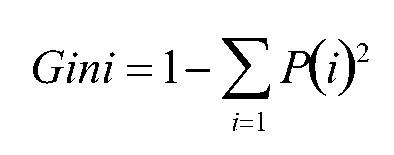
信息熵:
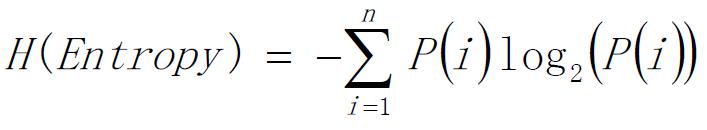
错误率:
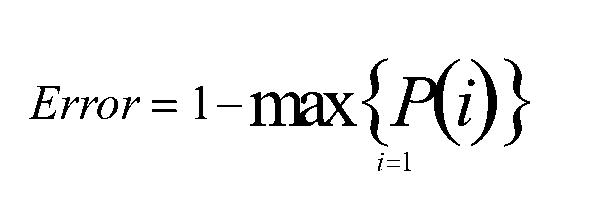
3. 什么时候停止分裂
一般情况有两种停止条件:
- 当每个子节点只有一种类型的时候停止构建。
- 当前节点中记录数小于某个阈值,同时迭代次数达到给定值时,停止构建过程。此时,使用 max(p(i))作为节点的对应类型。
方式一可能会使树的节点过多,导致过拟合(Overfiting)等问题。所以,比较常用的方式是使用方式二作为停止条件。
三、举例
数据集如下:
1. 对数据特征进行分割
- 拥有房产(是、否)
- 婚姻状态(单身、已婚、离婚)
- 年收入(80、97.5)
2. 通过信息增益找到分割特征
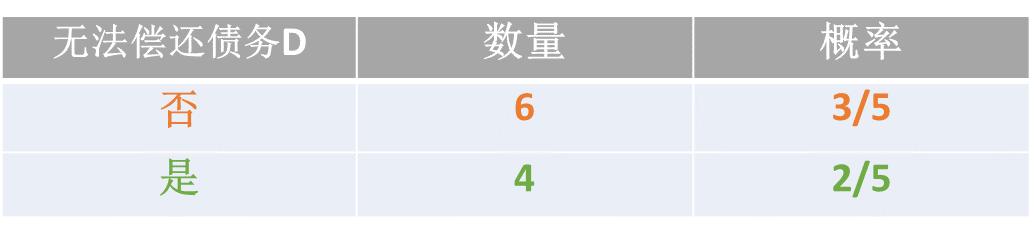
首先,计算按照拥有房产这个特征进行划分的信息增益,使用错误率进行纯度的计算:
计算原始数据的纯度:
计算按拥有房产划分后的结果集数据纯度H(D|A):
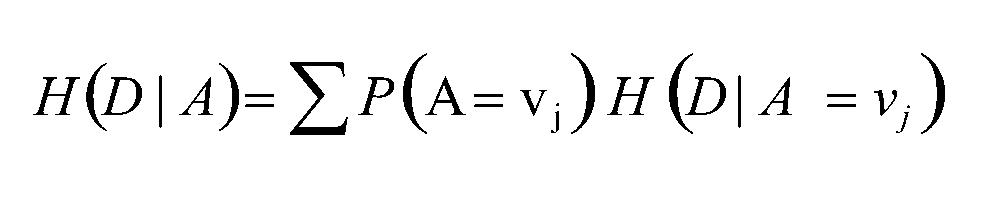
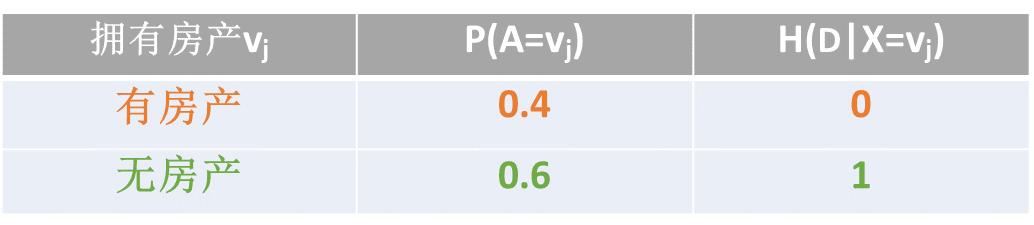
H(D| X=有房产) 的计算方式:
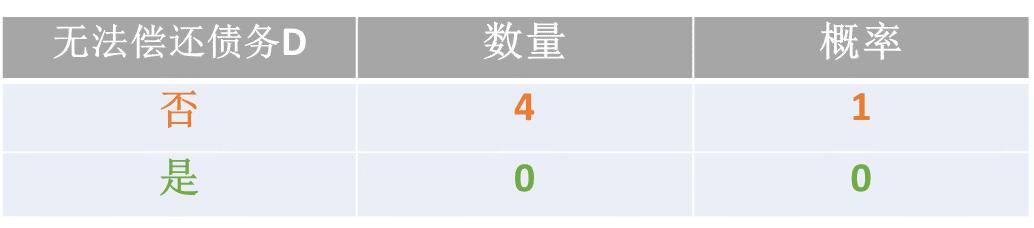
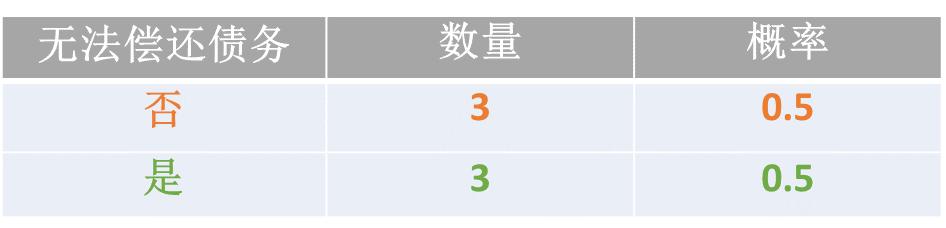
H(D| X=无房产) 的计算方式:
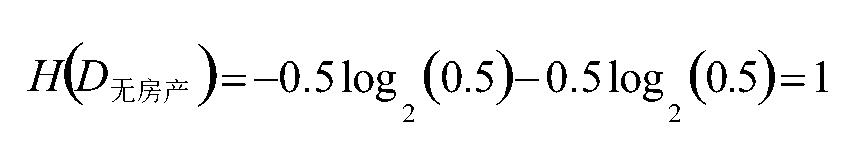
计算信息增益度Gain(房产):
同理,可以计算:婚姻状态 年收入=97.5
Gain(婚姻) = 0.205
Gain(婚姻) =0.395
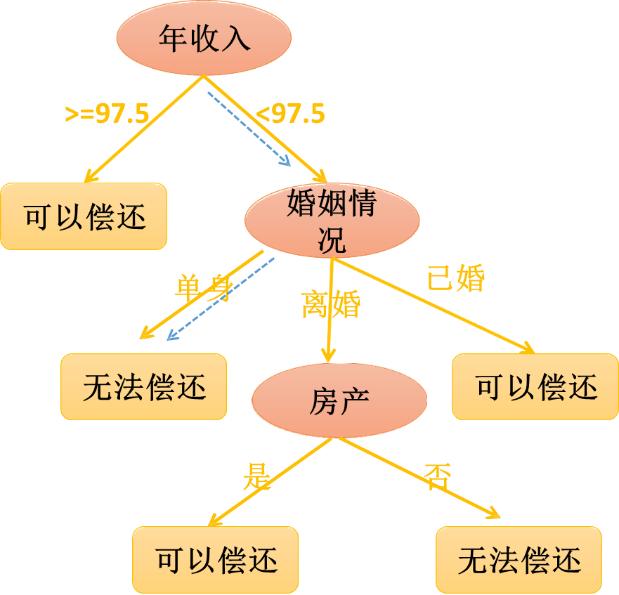
按照Gain越大,分割后的纯度越高,因此第一个分割属性为收入,并按照97.5进行划分。
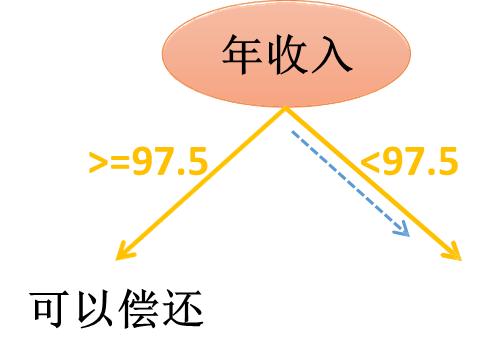
左子树的结果集够纯,因此不需要继续划分。
接下来,对右子树年收入大于97.5的数据,继续选择特征进行划分,且不再考虑收入这个特征,方法如上,可以得到如图:
四、常见算法
ID3:
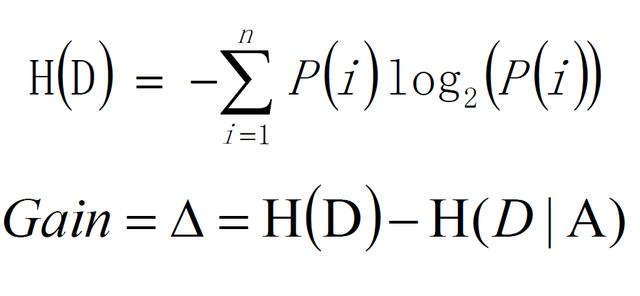
优点:决策树构建速度快;实现简单
缺点:
- 计算依赖于特征数目较多的特征,而属性值最多的属性并不一定最优 。
- ID3算法不是递增算法,ID3算法是单变量决策树,对于特征属性之间的关系不会考虑。
- 抗噪性差。
- 只适合小规模数据集,需要将数据放到内存中。
C4.5:
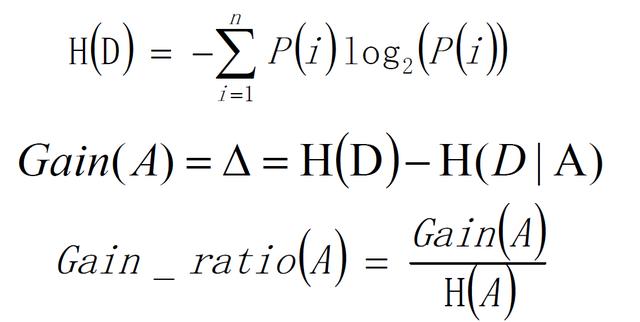
在ID3算法的基础上,进行算法优化提出的一种算法(C4.5),使用信息增益率来取代ID3中的信息增益。
CART(Classification And Regression Tree):
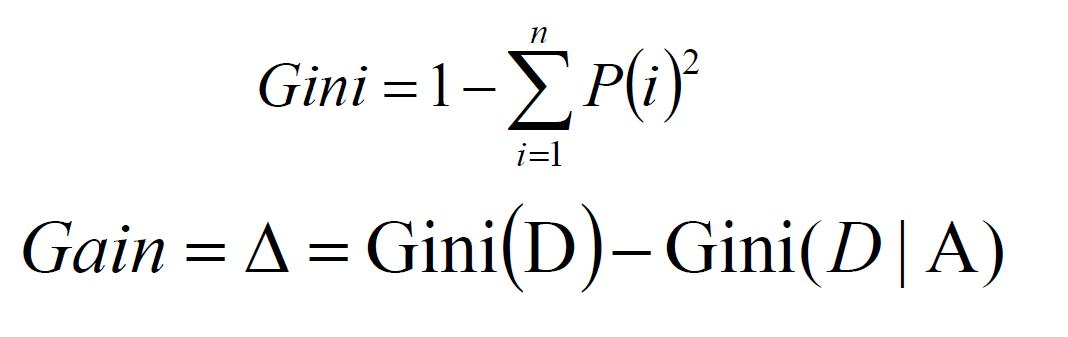
五、总结
- ID3和5算法均只适合在小规模数据集上使用。
- ID3和5算法都是单变量决策树当属性值取值比较多的时候,最好考虑C4.5算法,ID3得出的效果会比较差 决策树分类一般情况只适合小数据量的情况(数据可以放内存) CART算法是三种算法中最常用的一种决策树构建算法(sklearn中仅支持CART)。
- 三种算法的区别仅仅只是对于当前树的评价标准不同而已,ID3使用信息增益、 5使用信息增益率、CART使用基尼系数。
- CART算法构建的一定是二叉树,ID3和5构建的不一定是二叉树。
本文由 @SincerityY 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
最后
以上就是甜美烤鸡最近收集整理的关于sklearn 决策树例子_机器学习|决策树的生成过程是怎样?(一)的全部内容,更多相关sklearn内容请搜索靠谱客的其他文章。








发表评论 取消回复