本文是通过Storm将生产出来的数据进行实时的计算统计,整理出来之后将数据写到hbase和mysql数据中,并将结果展示在前端页面上,页面展示部分在下一篇说明
题目要求
一、机组运行数据清洗规则
1、运行数据日期不是当日数据
2、运行数据风速 为空||=-902||风速在 3~12之外
3、运行数据功率 为空||=-902||功率在 -0.5*1500~2*1500之外
二、清洗数据后存储HBase
1、正常数据 & 不合理数据 全部存入HBase中
2、划分两个表(Normal/Abnormal);Rowkey设计:年月日时分秒_机组编号;列:Value(把数据写入一个列中)
三、实时监控报警
对于正常数据监控异常指标,并输出到MySQL中记录,Web显示报警信息。
规则:每5S监控30S内发电机温度高于80度以上5次,报警(机组编号、报警时间、报警描述:过去30S内发电机温度高于80
度以上出现:6/10(次))
Storm实时计算部分
- 通过在终端启动了一个消费者查看使用kafka生产出来的数据被消费者消费的格式如下,是以逗号分割的一条数据流。
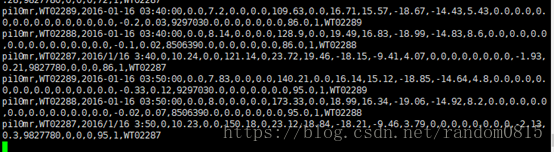
- 首先定义一个SplitdataBolt()用来将数据字段进行分割,并且将下面的步骤需要的字段发送到下一个bolt中
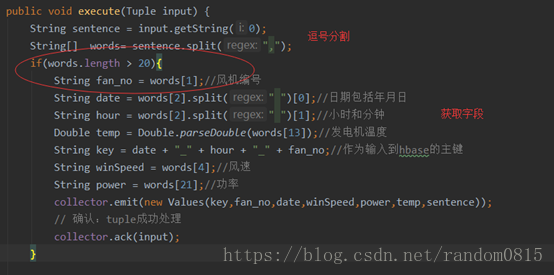

- 机组运行数据清洗规则
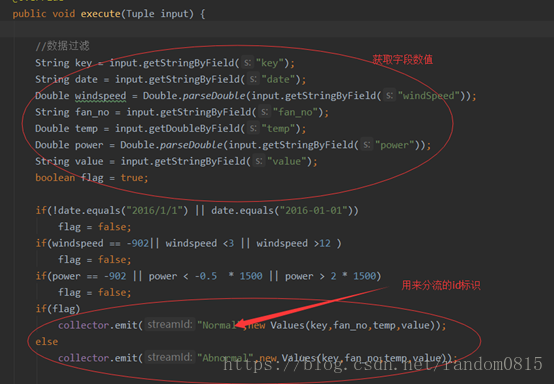
定义FliterBolt()用来进行数据的筛选。定义一个flag标识,当符合条件时,将flag标志为false,然后在发射数据的时候根据flag的值进行发射,同时标记了streamid,用于后面数据的分流。其中主要的不同还是streamid的不同,其他的字段都相同。
筛选条件
根据是否为当天日期,风速的值和功率值来进行筛选。当天日期只选取了2016/1/1的数据为当天数据。
为了验证数据的分流是否准确,使用了两个printbolt用来打印两个分流的数据。分流数据的使用在shuffleGrouping中加上分流数据的id,就可以将正常和不正常的进行分类分别使用两个bolt进行输出。

输出的数据如下
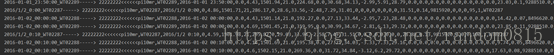
- 清洗数据后存储HBase
之前已经将数据的分流标记好id,只需要定义两个hbaseBolt分别进行配置和数据的接收,并将数据写入到hbase中
两个mapper和hbasebolt的设置
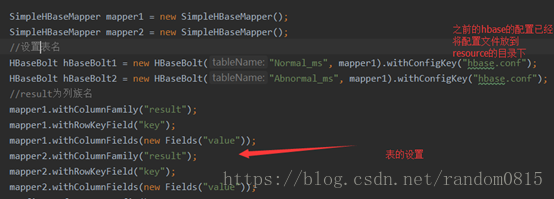
输入到hbase接收分流数据

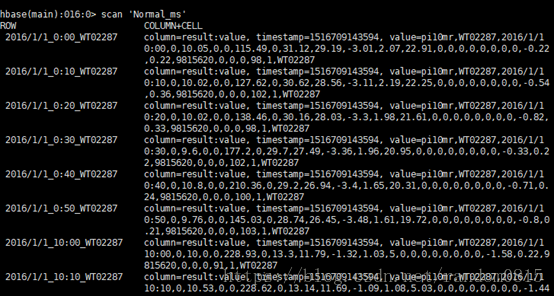
输入到hbase结果
可以看到rowkey和最后的结果和要求相同。
正常数据
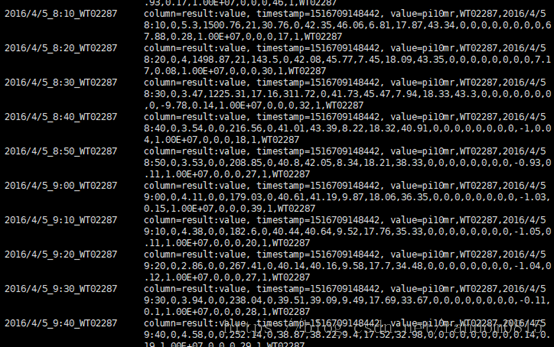
异常数据
- 实时监控报警(使用滑动窗口进行计算)
使用滑动窗口进行温度超过80度的数据的总和统计
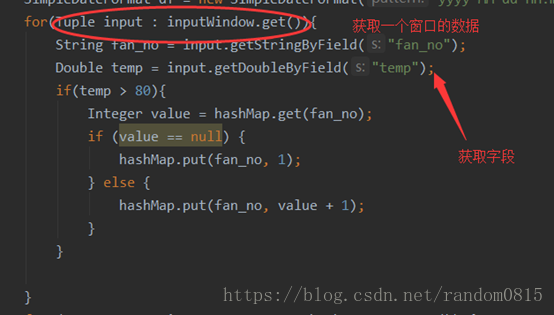
定义WindowMonitor继承BaseWindowedBolt类,通过execute方法将一个窗口内的数据进行统计。通过后面的if语句进行条件的判断,将温度大于80的风机编号进行计数,使用map来进行数据的存储
数据的发送:当一个窗口统计结束后,将map中key的value>5的map进行数据的发送

对接数据流
要定义窗口的长度和间隔,并且指定streamId
builder.setBolt("Filter", new FliterBolt(), 1)
.shuffleGrouping("data-spilter");
builder.setBolt("window",new WindowMonitor().withWindow(new BaseWindowedBolt.Duration(30, TimeUnit.SECONDS),new BaseWindowedBolt.Duration(5, TimeUnit.SECONDS)),1)
.shuffleGrouping("Filter","Normal");- 将统计数据输入到mysql数据库中
定义一个PersistentBolt类来进行jdbc的连接
Mysql数据库的配置
private static Map<String,Object> hikariConfigMap = new HashMap<String, Object>(){{
put("dataSourceClassName", "com.mysql.jdbc.jdbc2.optional.MysqlDataSource");
put("dataSource.url", "jdbc:mysql://172.17.11.183:3306/ExceptionMonitor");
put("dataSource.user","root");
put("dataSource.password", "root");
}};创建getJdbcInsertBolt方法,用来向数据库中插入数据
首先定义
List<> schemaColumns用来存放数据库中的表的字段名
创建如下两个对象使用withInsertQuery方法来进行数据库的插入
public static JdbcInsertBolt getJdbcInsertBolt(){
List<Column> schemaColumns = Lists.newArrayList(new Column("fan_no", Types.VARCHAR),
new Column("call_time", Types.VARCHAR), new Column("call_count", Types.INTEGER));
JdbcMapper simpleJdbcMapper = new SimpleJdbcMapper(schemaColumns);
JdbcInsertBolt jdbcInsertBolt = new JdbcInsertBolt(connectionProvider,simpleJdbcMapper)
.withInsertQuery("insert into exception_output(fan_no,call_time,call_count) values(?,?,?)")
.withQueryTimeoutSecs(50);
return jdbcInsertBolt;
//使用tablename进行插入数据,需要指定表中的所有字段
/*String tableName="ExceptionOutput";
JdbcMapper simpleJdbcMapper = new SimpleJdbcMapper(tableName, connectionProvider);
JdbcInsertBolt jdbcInsertBolt = new JdbcInsertBolt(connectionProvider, simpleJdbcMapper)
.withTableName("ExceptionOutput")
.withQueryTimeoutSecs(50);*/
//使用schemaColumns,可以指定字段要插入的字段
}MySQL数据库展示
Storm部分计算代码
写入到mysql中
主要还是要把Storm的上下游机制以及各种组件的原理搞清楚,代码就好写了
最后
以上就是优秀芹菜最近收集整理的关于Storm+HBASE+MySQL 实时读取Kafka信息计算存储的全部内容,更多相关Storm+HBASE+MySQL内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复