一、架构介绍
因为要采集的日志已经在线上,为了不侵入代码(主要也是其他产品不会因为我们搞这个日志监控而修改代码后重新上线),已经不能再规范日志化输出,也就是需要对老系统进行日志分析。对于不同的应用,不同的日志类型,比如nginx日志、tomcat日志、应用日志等都需要分别采集;调研了flume和Logstash,当然还有更轻量级的filebeta;最后选择了flume,有以下几个原因:1、flume是JAVA写的,对于项目组来说,入手成本稍低,虽然logstash也不错,但是要改源码,还得学习下ruby
2、flume和目前主流的系统或框架集成都比较容易,如hadoop、hbase、es,当采集日志后,数据落地比较方便
flume有3个非常重要的组件,分别是source、channel、sink 分别对应数据源,数据传输通道,数据落地。一般来说,当我们采集日志的时候,需要在app server上部署一个flume agent,然后将日志信息传输到指定的sink里面,但是这样做不是很好扩展,比如flume--->kafka这样的架构,假如
1、因为我们采集的日志跨项目组,也就是有不同的项目日志,如果直接flume-kafka,那么我的kafka配置信息需要对外完全暴露
2、假如现在我的kafka机器需要停机维护或者节点挂了,就会影响到flume端的日志采集服务
所以这里我们考虑让flume分层部署,不同的项目日志经过agent后再到一个数据缓存层,并且做好数据缓存层的failover,大概架构如下
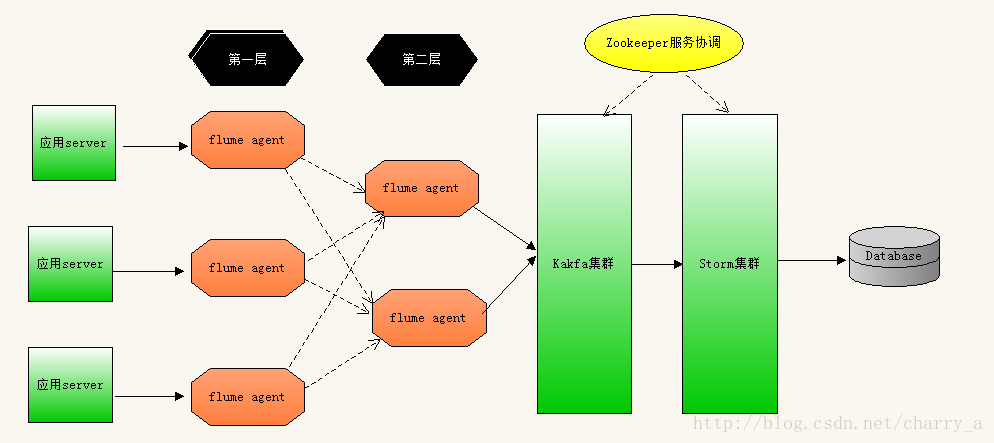
这里以一个项目的其中某个日志来举例,首先编写conf文件
a1.sources = s1
a1.sinks = k1 k2
a1.channels = c1
# Describe/configure the source
a1.sources.s1.type = exec
a1.sources.s1.channels = c1
a1.sources.s1.command = tail -F /home/esuser/flume/logs/flume.log
#config interceptor
a1.sources.s1.interceptors=i1 i2
a1.sources.s1.interceptors.i1.type=host
a1.sources.s1.interceptors.i1.useIP=true
a1.sources.s1.interceptors.i1.preserverExisting=false
a1.sources.s1.interceptors.i2.type=static
a1.sources.s1.interceptors.i2.key=projectname
a1.sources.s1.interceptors.i2.value=honeybee
a1.sources.s1.interceptors.i2.preserverExisting=false
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.80.132
a1.sinks.k1.port= 3333
a1.sinks.k1.channels = c1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = 192.168.80.132
a1.sinks.k2.port = 4444
a1.sinks.k2.channels = c1
# Use a channel that buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 10
a1.sinkgroups.g1.processor.priority.k2 = 5
a1.sinkgroups.g1.processor.maxpenalty = 1000接下来看一下第二层
先看3333接口
a1.sources = s1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.s1.type = avro
a1.sources.s1.channels = c1
a1.sources.s1.bind = 192.168.80.132
a1.sources.s1.port = 3333
a1.sources.s1.threads = 2
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = 192.168.80.132:9092
a1.sinks.k1.topic=test
a1.sinks.k..serializer.class=kafka.serializer.StringEncoder
# Use a channel that buffers events in memory
a1.channels.c1.type = file
a1.channels.c1.checkpointDir=/home/esuser/flume/checkpoint3333
a1.channels.c1.dataDirs=/home/esuser/flume/data3333
# Bind the source and sink to the channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
a1.sources = s1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.s1.type = avro
a1.sources.s1.channels = c1
a1.sources.s1.bind = 192.168.80.132
a1.sources.s1.port = 4444
a1.sources.s1.threads = 2
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.brokerList = 192.168.80.132
a1.sinks.k1.topic = test
a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder
# Use a channel that buffers events in memory
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/esuser/flume/checkpoint4444
a1.channels.c1.dataDirs=/home/esuser/flume/data4444
# Bind the source and sink to the channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1根据第一层配置,因为3333端口优先级高于4444端口,所以如果环境良好,第二层里面只会有3333端口收到消息,只有当3333端口所在进程宕掉后,4444端口就会接过3333端口所干的事情。
现在我们先来测试一下flume的配置是否是正确的,先写一个定时任务,每隔5s写入一条数据,日志文件就是第一层agent监听的文件
定时任务启动
日志文件

再启动agent,命令参考
./flume-ng agent -c ../conf -f ../myconf/flume-avro4444.conf -n a1 -Dflume.root.logger=INFO,console启动kafka消费者

已经消费了flume传输过来的数据,现在我手动kill 调3333端口,测试一下flume的故障转移
kill之后 第一层的agent就会报连不上
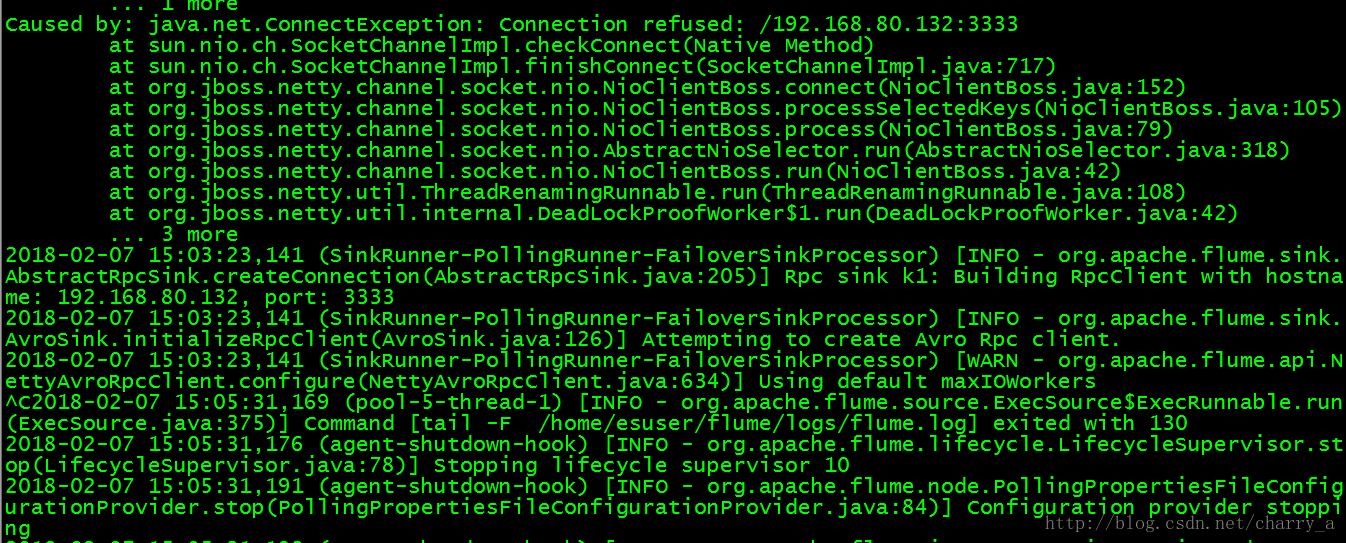
这个时间我们的日志依然在产生,再看一下消费者是否消费了

依然在消费数据。
现在我们编写storm消费kafka数据然后存入Mysql
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>flume</groupId>
<artifactId>storm</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>storm</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring.version>4.3.3.RELEASE</spring.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.0</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.clojure</groupId>
<artifactId>clojure</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.9.0.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>1.0.0</version>
</dependency>
<!-- storm运行jar报错新增 -->
<dependency>
<groupId>com.googlecode.json-simple</groupId>
<artifactId>json-simple</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.26</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-jdbc</artifactId>
<version>1.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<compilerVersion>1.8</compilerVersion>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
package com.log.storm;
import java.util.Arrays;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.kafka.BrokerHosts;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.StringScheme;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.spout.SchemeAsMultiScheme;
import org.apache.storm.topology.TopologyBuilder;
public class CounterTopology {
public static void main(String[] args) {
try {
String kafkaZookeeper = "192.168.80.132:2181";
BrokerHosts brokerHosts = new ZkHosts(kafkaZookeeper);
SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, "test", "/kafka2storm", "id");
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
spoutConfig.zkServers = Arrays.asList(new String[] { "192.168.80.132" });
spoutConfig.zkPort = 2181;
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", kafkaSpout, 1);
builder.setBolt("counter", new ParseBolt(), 2).shuffleGrouping("spout");
builder.setBolt("insertbolt", PersistentBolt.getJdbcInsertBolt(), 1).shuffleGrouping("counter");
Config config = new Config();
config.setDebug(false);
if (args != null && args.length > 0) {
config.setNumWorkers(1);
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} else {
config.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("special-topology", config, builder.createTopology());
Thread.sleep(50000);
cluster.killTopology("special-topology");
cluster.shutdown();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
package com.log.storm;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class ParseBolt extends BaseRichBolt{
private Logger logger = LoggerFactory.getLogger(ParseBolt.class);
private static final long serialVersionUID = -5508421065181891596L;
private OutputCollector collector;
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String message = tuple.getString(0);
logger.info("bolt receive message : " + message);
collector.emit(tuple, new Values(message));
collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("rule_value"));
}
}
PersistentBolt
package com.log.storm;
import java.sql.Types;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.storm.jdbc.bolt.JdbcInsertBolt;
import org.apache.storm.jdbc.common.Column;
import org.apache.storm.jdbc.common.ConnectionProvider;
import org.apache.storm.jdbc.common.HikariCPConnectionProvider;
import org.apache.storm.jdbc.mapper.JdbcMapper;
import org.apache.storm.jdbc.mapper.SimpleJdbcMapper;
import org.apache.storm.shade.com.google.common.collect.Lists;
@SuppressWarnings("serial")
public class PersistentBolt {
private static Map<String, Object> hikariConfigMap = new HashMap<String, Object>() {{
put("dataSourceClassName", "com.mysql.jdbc.jdbc2.optional.MysqlDataSource");
put("dataSource.url", "jdbc:mysql://192.168.80.132:3306/logmonitor");
put("dataSource.user", "root");
put("dataSource.password", "123456");
}};
public static ConnectionProvider connectionProvider = new HikariCPConnectionProvider(hikariConfigMap);
public static JdbcInsertBolt getJdbcInsertBolt() {
JdbcInsertBolt jdbcInsertBolt = null;
@SuppressWarnings("rawtypes")
List<Column> schemaColumns = Lists.newArrayList(new Column("rule_value", Types.VARCHAR));
if(null != schemaColumns && !schemaColumns.isEmpty()) {
JdbcMapper simpleJdbcMapper = new SimpleJdbcMapper(schemaColumns);
jdbcInsertBolt = new JdbcInsertBolt(connectionProvider, simpleJdbcMapper)
.withInsertQuery("insert into t_rule_config(rule_value) values(?)")
.withQueryTimeoutSecs(50);
}
return jdbcInsertBolt;
}
} 
查看storm日志,可以看到storm已经消费了数据
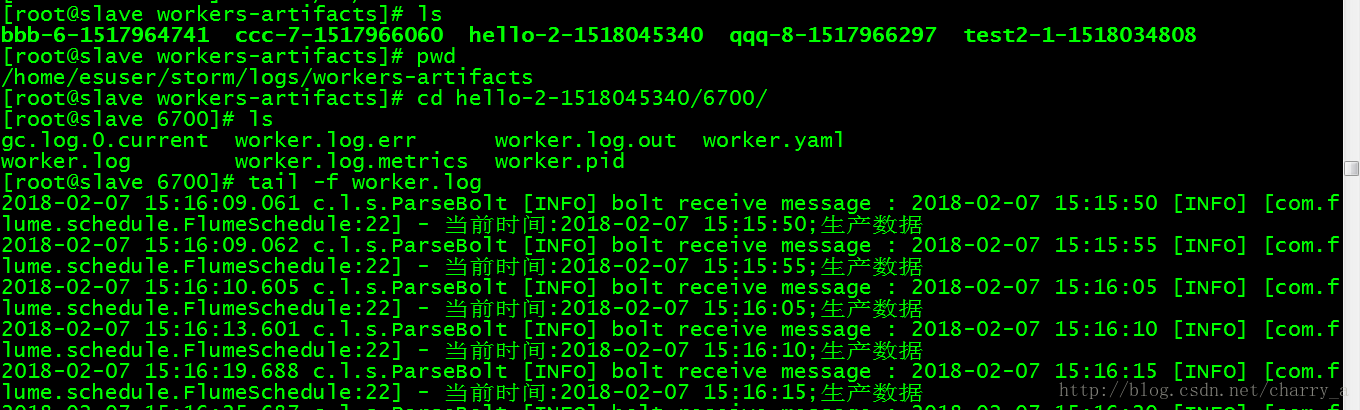
再看DB表,可以看到已经有了日志,这里没有对收到的message做任何处理,所以是最原始的日志文件,乱码问题是因为编码没设置,可忽略。
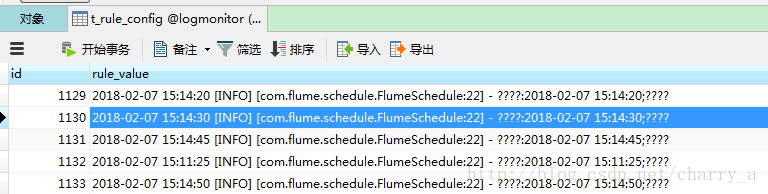
至此,从应用server--->flume-->kafka---->storm--->mysql整个链路已经通了。基本链路比较清晰,但是各个组件还有很多细节的东西,当然,这都是后话了。
最后
以上就是寒冷果汁最近收集整理的关于使用flume-ng+kafka+storm+mysql 搭建实时日志处理平台的全部内容,更多相关使用flume-ng+kafka+storm+mysql内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复