项目需求:
采集1-3台机器的nginx的access.log(/var/log/nginx/access.log)实时保存在HDFS中
使用spark对当天的日志进行汇总分析
在web界面中以图表的形式展示出来,需要体现如下2个表:
1:哪个URL访问数量最大,按访问量从多到少排序展示出来
2:哪些IP访问造成404错误最多,按从多到少排序展示出来
提高练习:
使用spark对所有的日志进行汇总分析,在web界面中展示出来
==》分析题目,绘制项目架构图
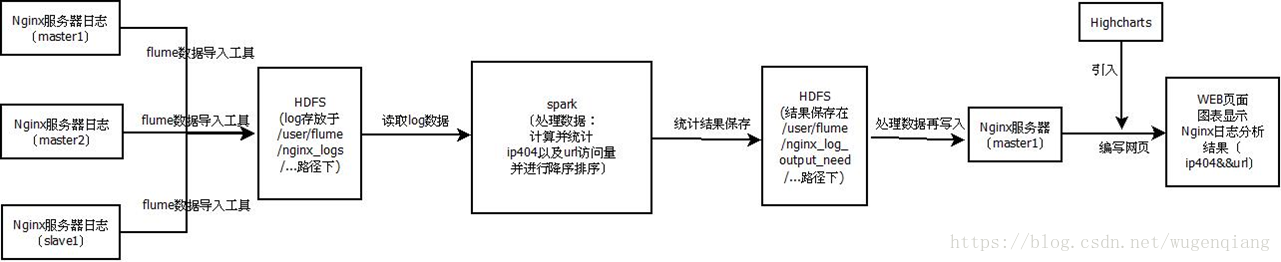
确定完成步骤及技术点
分三步执行:
第一步:
需求:
采集1-3台机器的nginx的access.log(/var/log/nginx/access.log)
实时保存在HDFS中
技术点:
- 搭建集群3台(master1、master2和slave1),
- 3台机器分别安装并配置好flume数据导入工具、Nginx服务器以及spark,
- 将日志数据实时读取,存入access.log(/var/log/nginx/access.log)日志文件中,保存在HDFS中
- Flume采集和存储:Flume工具实现日志数据导入,3台Nginx服务器的日志文件access.log统一导入到HDFS上的同一个目录下,即(/user/flume/)
- 日志不够多,可以采用bash脚本产生更多记录
实现:
1.搭建集群3台(master1、master2和slave1),配置hadop集群,yarn等
参考: https://blog.csdn.net/wugenqiang/article/details/81102294
2.3台机器分别安装并配置好flume数据导入工具、Nginx服务器以及spark,
2.1配置flume,安装Nginx服务器,使用flume收集nginx服务器的日志到hdfs中
2.1.1配置文件/etc/flume/conf/flume.conf
[root@master1 ~]# cd /etc/flume/conf
[root@master1 conf]# ls
flume.conf flume-env.sh.template
flume-conf.properties.template log4j.properties
flume-env.ps1
[root@master1 conf]# vim flume.conf 添加:
##配置Agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# # 配置Source
a1.sources.r1.type = exec
a1.sources.r1.channels = c1
a1.sources.r1.deserializer.outputCharset = UTF-8
# # 配置需要监控的日志输出目录
a1.sources.r1.command = tail -F /var/log/nginx/access.log
# # 配置Sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.path = hdfs://master1:8020/user/flume/nginx_logs/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.minBlockReplicas = 1
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 86400
a1.sinks.k1.hdfs.rollSize = 1000000
a1.sinks.k1.hdfs.rollCount = 10000
a1.sinks.k1.hdfs.idleTimeout = 0
# # 配置Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# # 将三者连接
a1.sources.r1.channel = c1
a1.sinks.k1.channel = c1
复制给其他服务器:
[root@master1 ~]# scp /etc/flume/conf/flume.conf root@master2:/etc/flume/conf/flume.conf
flume.conf 100% 2016 1.6MB/s 00:00
[root@master1 ~]# scp /etc/flume/conf/flume.conf root@slave1:/etc/flume/conf/flume.conf
flume.conf 100% 2016 134.1KB/s 00:00 2.1.2集群分别挂载光盘,并安装nginx服务
[root@master2 ~]# mount /dev/sr0 /mnt/cdrom
mount: 挂载点 /mnt/cdrom 不存在
[root@master2 ~]# cd /mnt/
[root@master2 mnt]# ls
[root@master2 mnt]# mkdir cdrom
[root@master2 mnt]# mount /dev/sr0 /mnt/cdrom
mount: /dev/sr0 写保护,将以只读方式挂载
[root@master2 mnt]# cd
[root@master2 ~]# yum install nginx
已加载插件:fastestmirror
hanwate_install | 3.7 kB 00:00
(1/2): hanwate_install/group_gz | 2.1 kB 00:00
(2/2): hanwate_install/primary_db | 917 kB 00:00 安装nginx服务的时候,若出现下面这个,
请参考: https://blog.csdn.net/wugenqiang/article/details/81075446
[root@master2 ~]# yum install nginx
已加载插件:fastestmirror
There are no enabled repos.
Run "yum repolist all" to see the repos you have.
To enable Red Hat Subscription Management repositories:
subscription-manager repos --enable <repo>
To enable custom repositories:
yum-config-manager --enable <repo>2.1.3 准备web服务器日志,集群分别开启nginx服务
[root@master2 ~]# systemctl start nginx2.1.4开启服务后,可通过/var/log/nginx/access.log
[root@master2 ~]# cd /var/log/nginx/
[root@master2 nginx]# ls
access.log error.log2.2 创建日志导入hdfs目录
[root@master1 ~]# su - hdfs
上一次登录:五 7月 20 13:07:04 CST 2018pts/0 上
-bash-4.2$ hadoop fs -mkdir /user/flume
-bash-4.2$ hadoop fs -chmod 777 /user/flume2.3 启动a1代理,集群都操作一遍
[root@master1 ~]# flume-ng agent --conf /etc/flume/conf/ --conf-file /etc/flume/conf/flume.conf --name a12.4 日志在hdfs上存储的结果
-bash-4.2$ hadoop fs -ls -R /user/flume/nginx_logs
drwxr-xr-x - root supergroup 0 2018-07-30 16:30 /user/flume/nginx_logs/20180730
-rw-r--r-- 4 root supergroup 2068 2018-07-30 16:30 /user/flume/nginx_logs/20180730/2018-07-30-16.1532939308683.log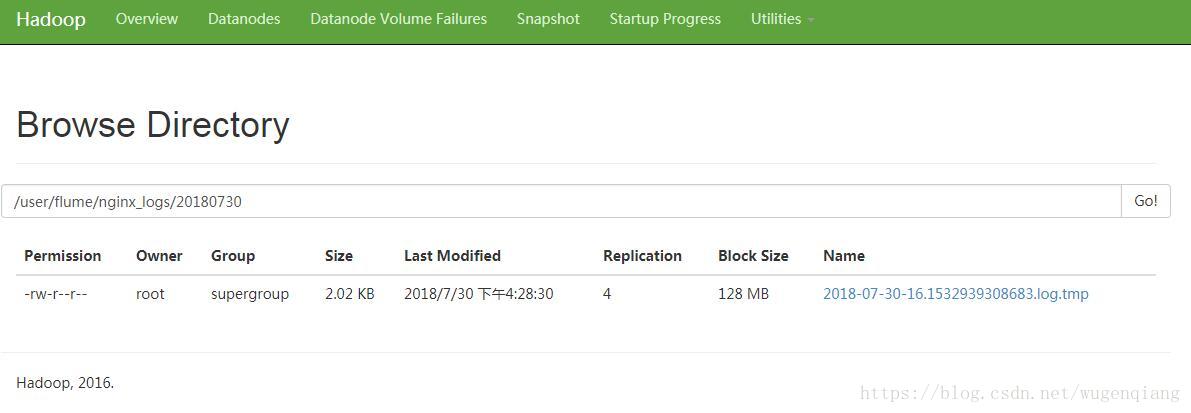
2.5 spark自带即可用,启动pyspark
[root@master1 ~]# pyspark
Python 2.7.5 (default, Aug 4 2017, 00:39:18)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-16)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/07/30 16:35:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/07/30 16:36:04 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/__ / .__/_,_/_/ /_/_ version 2.2.0.2.6.3.0-235
/_/
Using Python version 2.7.5 (default, Aug 4 2017 00:39:18)
SparkSession available as 'spark'.
>>> 3 日志不够多,可以采用bash脚本产生更多记录
编写自动运行脚本,来执行登录网页,来生成日志信息
#!/bin/bash
step=1 #间隔的秒数,不能大于60
host_list=("localhost" "192.168.75.137" "master1" "wugenqiang.master")
while [ 1 ]
do
num=$(((RANDOM%7)+1))
seq=$(((RANDOM%4)))
url="http://"${host_list[$seq]}"/"$num".html";
echo " `date +%Y-%m-%d %H:%M:%S` get $url"
#curl http://192.168.75.137/1.html #调用链接
curl -s $url > /dev/null
sleep $step
done结果:
[root@master1 conf]# vim test_log_records_add.sh
[root@master1 conf]# ./test_log_records_add.sh
2018-07-31 20:40:33 get http://master1/7.html
2018-07-31 20:40:34 get http://wugenqiang.master/6.html
2018-07-31 20:40:35 get http://localhost/6.html
2018-07-31 20:40:36 get http://master1/6.html
2018-07-31 20:40:37 get http://wugenqiang.master/3.html
2018-07-31 20:40:38 get http://192.168.75.137/2.html
2018-07-31 20:40:39 get http://192.168.75.137/1.html
2018-07-31 20:40:40 get http://wugenqiang.master/1.html
2018-07-31 20:40:41 get http://192.168.75.137/3.html
2018-07-31 20:40:42 get http://wugenqiang.master/1.html
2018-07-31 20:40:43 get http://localhost/4.html
2018-07-31 20:40:44 get http://192.168.75.137/7.html
2018-07-31 20:40:45 get http://192.168.75.137/7.html
2018-07-31 20:40:46 get http://master1/7.html
2018-07-31 20:40:47 get http://master1/6.html
2018-07-31 20:40:48 get http://wugenqiang.master/1.html
2018-07-31 20:40:50 get http://192.168.75.137/2.html
2018-07-31 20:40:51 get http://wugenqiang.master/6.html
2018-07-31 20:40:52 get http://localhost/3.html第二步:
需求:
使用spark对当天的日志进行汇总分析
技术点:
1.使用Spark提取相关的日志数据项(url、ip-404)并进行计算,
难点:如何实施?
- 安装配置
- Spark读入路径,使用/user/flume/
- 测试:pyspark
- 排序
- 分割提取数据,取对应列
- 按时间来划分日志
- 汇总访问的URL,
- 最终文件保存在linux中
- Nginx_log.py脚本
- 计划任务运行,每5分钟执行一次
实现:
1.使用Spark提取相关的日志数据项(url、ip-404)并进行计算
1.1 安装配置:见第一步2.5
1.2 Spark读入路径,使用/user/flume/nginx_logs/%Y%m%d
>>> rdd = sc.textFile("hdfs://master1:8020/user/flume/nginx_logs/20180730/*")1.3 测试pyspark
>>> rdd.count()
[Stage 0:> (
[Stage 0:=======================================> (
31 1.4 汇总访问的URL,按访问量从多到少排序展示出来
>>> rdd=sc.textFile("hdfs://master1:9000/user/flume/nginx_logs/20180731
>>> url=rdd.map(lambda line:line.split(" ")).map(lambda w:w[6])
>>> url_add=url.map(lambda w:(str(w),1))
>>> url_add_reduce=url_add.reduceByKey(lambda x,y:x+y)
>>> url_add_reduce.collect()
[('/5.html;', 27), ('/7.html;', 23), ('/1.html', 87), ('/7.html', 40), ('/1.html;', 25), ('/5.html', 60), ('/3.html', 54), ('/4.html;', 30), ('/6.html;', 30), ('/8.html', 11), ('/2.html;', 21), ('/nginx_log_need/ip404/20180731/part-00000', 2), ('/analysisOfData/url_AmountOfAccess.html', 2), ('/3.html;', 27), ('/favicon.ico', 3), ('/analysisOfData/ip404_AmountOfAccess.html', 2), ('/4.html', 45), ('/2.html', 37), ('/6.html', 64)]
>>> url_add_reduce_sort=url_add_reduce.sortBy(lambda x:-x[1])
>>> url_add_reduce_sort.collect()
[Stage 35:> (0 [('/1.html', 87), ('/6.html', 64), ('/5.html', 60), ('/3.html', 54), ('/4.html', 45), ('/7.html', 40), ('/2.html', 37), ('/4.html;', 30), ('/6.html;', 30), ('/5.html;', 27), ('/3.html;', 27), ('/1.html;', 25), ('/7.html;', 23), ('/2.html;', 21), ('/8.html', 11), ('/favicon.ico', 3), ('/nginx_log_need/ip404/20180731/part-00000', 2), ('/analysisOfData/url_AmountOfAccess.html', 2), ('/analysisOfData/ip404_AmountOfAccess.html', 2)]
>>>url_add_reduce_sort.repartition(1).saveAsTextFile("file:///usr/share/nginx/html/nginx_log_need/url/20180731")
结果:
[root@master1 nginx_log_need]# ls
ip404 url
[root@master1 nginx_log_need]# cd url/
[root@master1 url]# ls
20180731
[root@master1 url]# cd 20180731/
[root@master1 20180731]# ls
part-00000 _SUCCESS
[root@master1 20180731]# cat part-00000
('/1.html', 87)
('/6.html', 64)
('/5.html', 60)
('/3.html', 54)
('/4.html', 45)
('/7.html', 40)
('/2.html', 37)
('/4.html;', 30)
('/6.html;', 30)
('/5.html;', 27)
('/3.html;', 27)
('/1.html;', 25)
('/7.html;', 23)
('/2.html;', 21)
('/8.html', 11)
('/favicon.ico', 3)
('/nginx_log_need/ip404/20180731/part-00000', 2)
('/analysisOfData/url_AmountOfAccess.html', 2)
('/analysisOfData/ip404_AmountOfAccess.html', 2)1.5 汇总访问的ip404,IP访问造成404错误最多,按从多到少排序展示出来
>>> rdd=sc.textFile("hdfs://master1:9000/user/flume/nginx_logs/20180731/*")
>>> line_contain_404=rdd.filter(lambda line:"404" in line)
>>> line_404_ips=line_contain_404.map(lambda line:line.split(" ")).map(lambda w:w[0])
>>> line_404_ips_add=line_404_ips.map(lambda w:(str(w),1))
>>> line_404_ips_add_redu=line_404_ips_add.reduceByKey(lambda x,y:x+y)
>>> line_404_ips_add_redu.count()
[Stage 2:> (0 + 1)[Stage 2:=========> (1 + 1)[Stage 2:=============================> (3 + 1)[Stage 2:=================================================> (5 + 1)[Stage 3:=============================> (3 + 1) 5
>>> line_404_ips_add_redu.collect()
[('::1', 64), ('192.168.75.1', 11), ('192.168.75.139', 4), ('192.168.75.138', 9), ('192.168.75.137', 217)]
>>> line_404_ips_add_redu.sort=line_404_ips_add_redu.sortBy(lambda x:x[1])
>>> line_404_ips_add_redu.sort.collect()
[('192.168.75.139', 4), ('192.168.75.138', 9), ('192.168.75.1', 11), ('::1', 64), ('192.168.75.137', 217)]
>>> line_404_ips_add_redu.sort=line_404_ips_add_redu.sortBy(lambda x:-x[1])
>>> line_404_ips_add_redu.sort.collect()
[('192.168.75.137', 217), ('::1', 64), ('192.168.75.1', 11), ('192.168.75.138', 9), ('192.168.75.139', 4)]
>>>line_404_ips_add_redu.sort.repartition(1).saveAsTextFile("file:///usr/share/nginx/html/nginx_log_need/ip404/20180731")降序排列演示:
>>> line_404_ips_add_redu.sort=line_404_ips_add_redu.sortBy(lambda x:-x[1])
>>> line_404_ips_add_redu.sort.collect()
[('192.168.75.137', 217), ('::1', 64), ('192.168.75.1', 11), ('192.168.75.138', 9), ('192.168.75.139', 4)]结果:
[root@master1 ~]# cd /usr/share/nginx/html/nginx_log_need/ip404/20180731/
[root@master1 20180731]# ls
part-00000 _SUCCESS
[root@master1 20180731]# cat part-00000
('192.168.75.137', 217)
('::1', 64)
('192.168.75.1', 11)
('192.168.75.138', 9)
('192.168.75.139', 4)最终文件保存在linux中
2 编写nginx_log.py脚本
处理log数据的脚本,将spark处理的数据上传hdfs,为脚本计划运行做准备
[root@master nginx]# cat nginx_log.py
#!/usr/bin/python
#coding=utf-8
from pyspark import SparkContext
import os
os.environ['PYTHONPATH']='python2'
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
sc=SparkContext("yarn")
#将url访问量降序排序,存入hdfs对应路径中:
rdd_url = sc.textFile("hdfs://master:9000/user/flume/nginx_logs/20180803/*").map(lambda s:s.split(" ")).map(lambda w:[str(w[6])]).flatMap(lambda w:w).map(lambda w:[w,1]).reduceByKey(lambda x,y:x+y).sortBy(lambda x:-x[1]).map(lambda x:list(x)).coalesce(1).saveAsTextFile("/user/flume/nginx_log_output_need/url/20180803")
#ip_404错误降序排序,存入hdfs对应路径中:
rdd_ip404 = sc.textFile("hdfs://master:9000/user/flume/nginx_logs/20180803/*").filter(lambda line:"404" in line).map(lambda s:s.split(" ")).map(lambda w:[str(w[0])]).flatMap(lambda w:w).map(lambda w:[w,1]).reduceByKey(lambda x,y:x+y).sortBy(lambda x:-x[1]).map(lambda x:list(x)).coalesce(1).saveAsTextFile("/user/flume/nginx_log_output_need/ip404/20180803")3 计划任务运行,每5分钟执行一次
输入crontab -e命令
*/5 * * * * /usr/share/nginx/spark_run_nginx_log.sh 2>&1 >> /usr/share/nginx/crontab_spark_run_nginx.log第三步:
需求:
在web界面中以图表的形式展示出来,需要体现如下2个表:
1:哪个URL访问数量最大,按访问量从多到少排序展示出来
2:哪些IP访问造成404错误最多,按从多到少排序展示出来
3:使用spark对所有的日志进行汇总分析,在web界面中展示出来
技术点:
- 数据读取写入nginx服务器,
-- 如何写入?
- 以文本文件的形式写入Nginx服务器下的目录中
2.控件使用highcharts
3.Ajax获取nginx服务器数据
4.Web页面读取nginx代理服务器上的日志分析结果,
- 计划任务,设置隔一段时间更新一次
- 实现数据的实时统计与展示
5.如何以图表形式显示,柱状图或饼状图
===========================================
实际实施:
1.优化之前两步,改写自动脚本运行
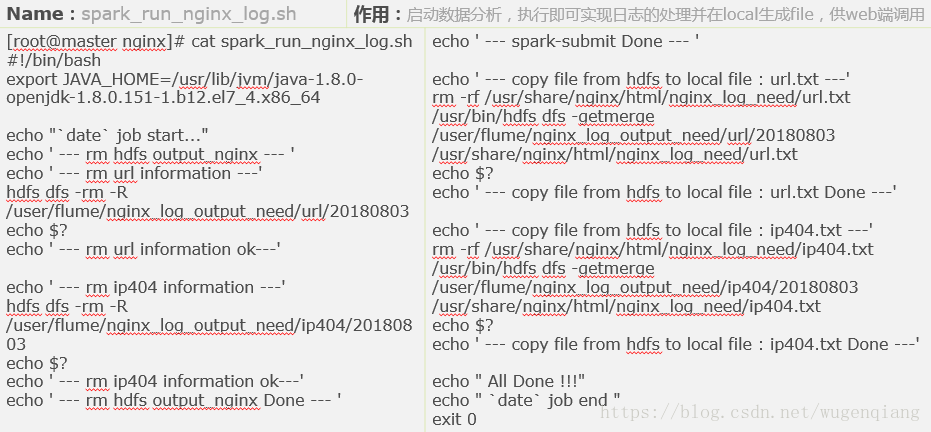
2.ajax获取spark处理后的数据,拼接成需要的json格式
(1)url_Access.html,ajax算法部分
$.ajax({//获取url
type: "get",
async: false,
url: "/nginx_log_need/url.txt",
success: function(data) {
//数据源通过]符号进行分割,命名为data_source
var data_source = data.split(']');
console.log("数据源:"+data_source);
var url_value = "";//url值
for(i = 0; i < data_source.length - 1; i++) {
if(i == 0) {
url_value = url_value + (data_source[i].split(',')[0]).substr(1) + ",";
} else {
url_value = url_value + (data_source[i].split(',')[0]).substr(2);
if(i < data_source.length - 2) {
url_value = url_value + ",";
}
}
}
console.log("url:"+url_value);
rst = eval('[' + url_value + ']');
console.log(rst);
} });
$.ajax({//获取url访问量
type: "get",
async: false,
url: "/nginx_log_need/url.txt",
success: function(data) {
//数据源
var data_source = data.split(']');
var data_handle = "";//数据处理
console.log(data_source);
for(i = 0; i < data_source.length - 1; i++) {
data_handle = data_handle.concat(data_source[i].split(',')[1]);
if(i < data_source.length - 2) {
data_handle = data_handle + ",";
}
}
console.log("处理:"+data_handle);
rst = eval('[' + data_handle + ']');
}
});
(2)ip404_Access.html,ajax算法部分
$.ajax({
type: "get",
async: false,
url: "/nginx_log_need/ip404.txt",
success: function(data) {
//从本地文件中读取数据,以换行符分割
var data_source=data.split("n");//数据源
var data_handle="";//数据处理
var sum=0;//求和变量,为算比例做准备
//控制台打印调试
console.log("数据源:"+data_source)//控制台查看数据源
for(i=0;i<data_source.length-2;i++){//数据源中数据处理后放入data_handle
data_handle=data_handle+data_source[i].substr(0,data_source[i].length)+",";} data_handle=data_handle+data_source[i].substr(0,data_source[i].length);
console.log("数据源处理结果:"+data_handle);//控制台打印处理好的数据
rst=eval('['+data_handle+']');//eval处理表达式
for(i=0;i<rst.length;i++){
sum=sum+rst[i][1];//value值求和
}
for(i=0;i<rst.length;i++){
rst[i][1]=(parseFloat(rst[i][1])/parseFloat(sum));
//可用toFixed(2)控制小数精度
}}});
(3)优化算法,改写算法,图表显示
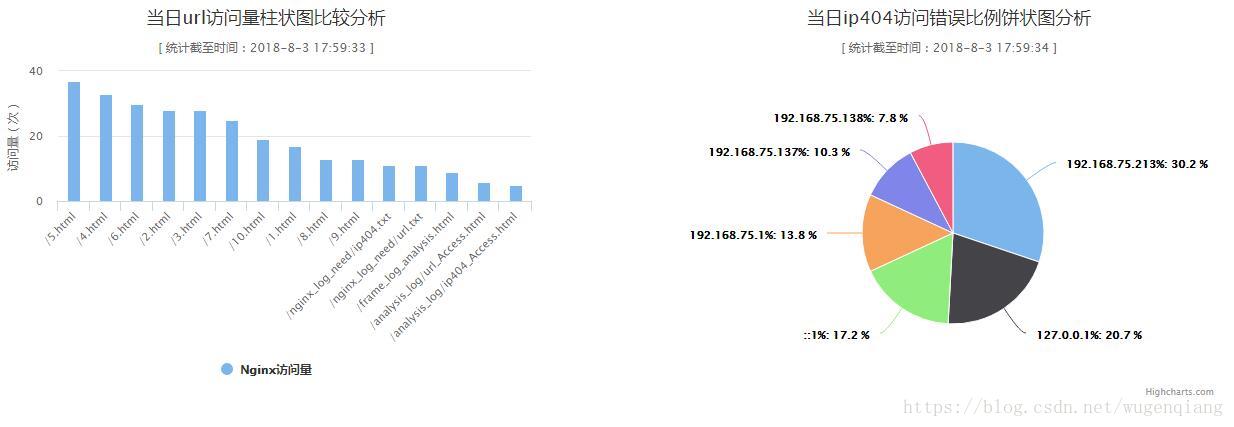
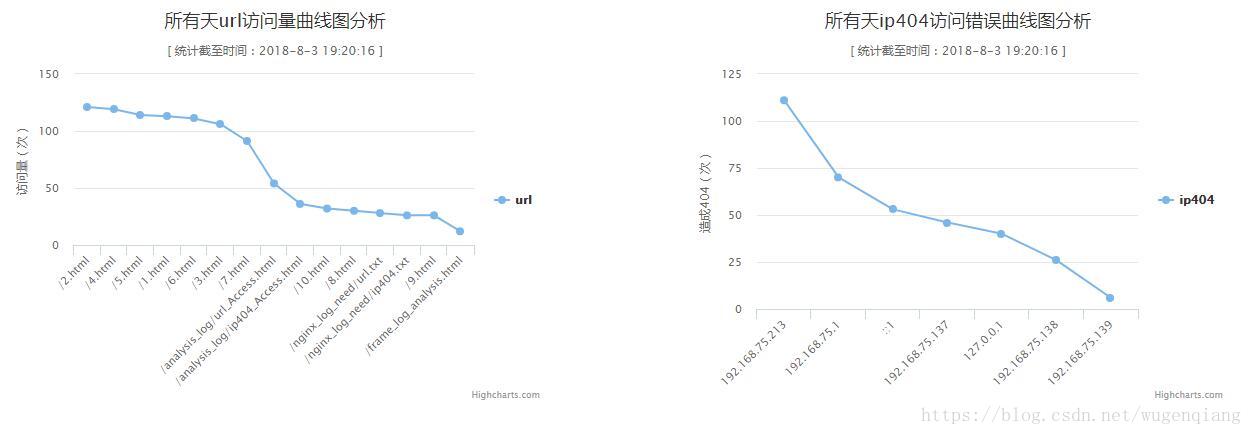
最后
以上就是甜蜜学姐最近收集整理的关于大数据可视化之Nginx日志分析及web图表展示(HDFS+Flume+Spark+Nginx+Highcharts)的全部内容,更多相关大数据可视化之Nginx日志分析及web图表展示(HDFS+Flume+Spark+Nginx+Highcharts)内容请搜索靠谱客的其他文章。








发表评论 取消回复