摘要
主要是分析和讲解Flum的原理源码分析
Flume概述
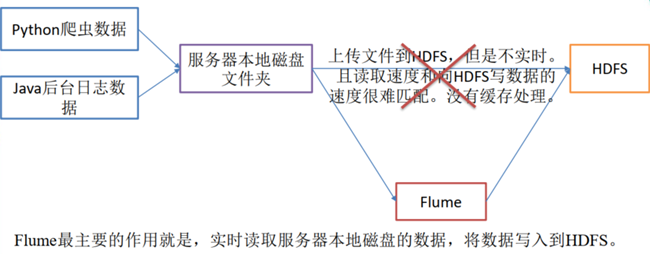
Flume是的一个分布式、高可用、高可靠的海量日志采集、聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时提供了对数据进行简单处理并写到各种数据接收方的能力。
Flume的设计原理是基于数据流的,能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。Flume能够做到近似实时的推送,并且可以满足数据量是持续且量级很大的情况。比如它可以收集社交网站日志,并将这些数量庞大的日志数据从网站服务器上汇集起来,存储到HDFS或HBase分布式数据库中。
Flume的应用场景:比如一个电商网站,想从网站访问者中访问一些特定的节点区域来分析消费者的购物意图和行为。为了实现这一点,需要收集到消费者访问的页面以及点击的产品等日志信息,并移交到大数据Hadoop平台上去分析,可以利用Flume做到这一点。现在流行的内容推送,比如广告定点投放以及新闻私人定制也是基于这个道理。
Flume的架构
Flume简介:
Flume 就是实时的读取文件夹的内容,并将数据存储在HDFS中。读取文件,和端口数据。Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。Flume构建在日志流之上一个简单灵活的架构。它具有可靠的可靠性机制和许多故障转移和恢复机制,具有强大的容错性。使用Flume这套架构实现对日志流数据的实时在线分析。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume的原理
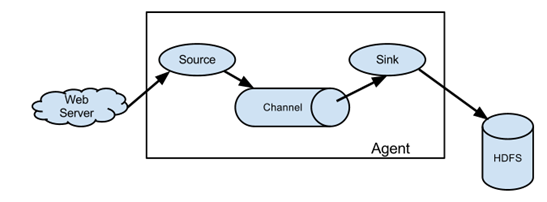
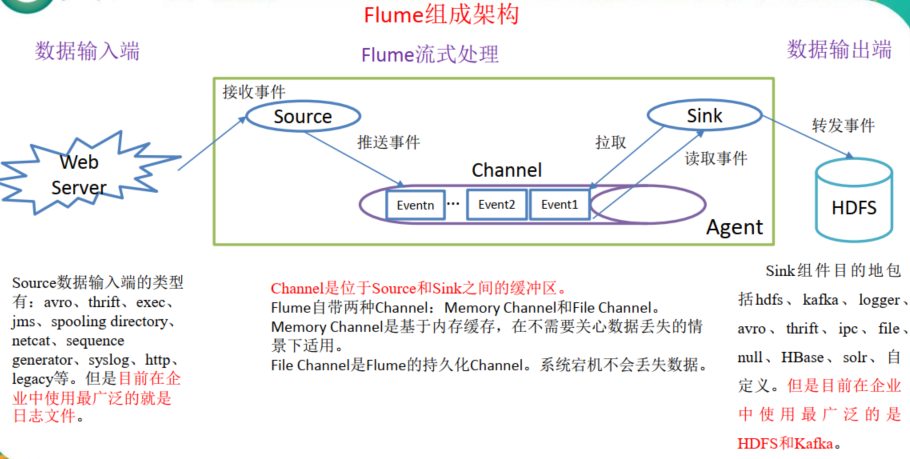
flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。这了保证数据传输过程的成功率,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume才会删除缓存的数据。在整个数据传输的过程中,流动的是event,即事务保证是在event级别,event是flume传输数据的基本单元,如果是文本文件,通常是一条记录,event也是事务的基本单位。event从source, 流向channel,再到sink,其本身是一个字节数组,并可携带头信息(headers)。event代表着一个数据的最小完整单元,从外部数据源来,向外部目的地去。
Flume常用的组件:
Source(采集外围数据)
Avro Source :使用AVRO协议远程收集数据。
Thrift Source:使用Thrift协议远程收集数据。
Exec Source:可以讲控制台输出数据采集到Agent。
Spooling Directory Source:采集指定目录下的静态数据。
Taildir Source:动态采集文本日志文件中新产生的行数据。
Kafka Source:采集来自Kafka消息队列中的数据。
Sink(写出数据):
Avro Sink:使用AVRO协议将数据写出给Avro Source|Avro服务器。
Thrift Sink:使用Thrift协议将数据写出给Thrift Source|Thrift 服务器。
HDFS Sink:将采集的数据直接写入HDFS中。
File Roll Sink:将采集的数据直接写入本地文件中。
Kafka Sink:将采集的数据直接写入Kafka中。
Channel(缓冲数据):
Memory Channel:使用内存缓存Event
JDBC Channel:使用Derby嵌入式数据库文件缓存Event
Kafka Channel:使用Kafka缓存Event
File Channel:使用本地文件系统缓存Event
flume的核心就是一个agent,这个agent对外有两个进行交互的地方,一个是接收数据的输入(Source),一个是数据的输出(sink),Sink负责将数据发送到外部指定的目的地。其运行机制如下:source接收到数据后,将数据发送给channel, channel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方。(注:只有在sink将channel中的数据成功发出去以后,channel才会将临时数据进行删除,这种机制保证了数据传输的可靠性与安全性。)
Flume事务处理
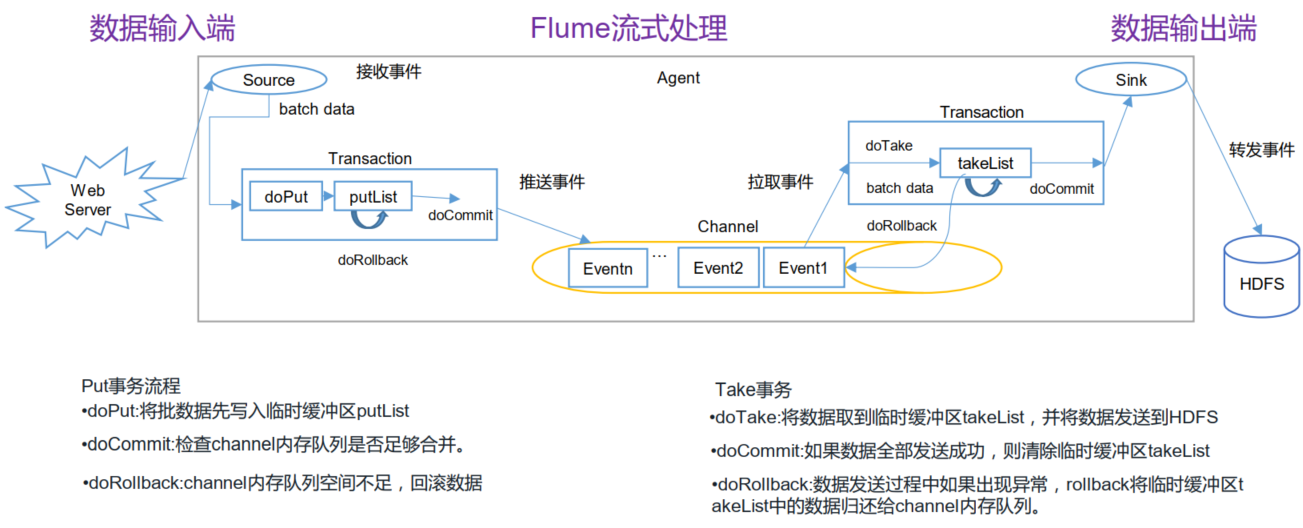
Flume Agent原理
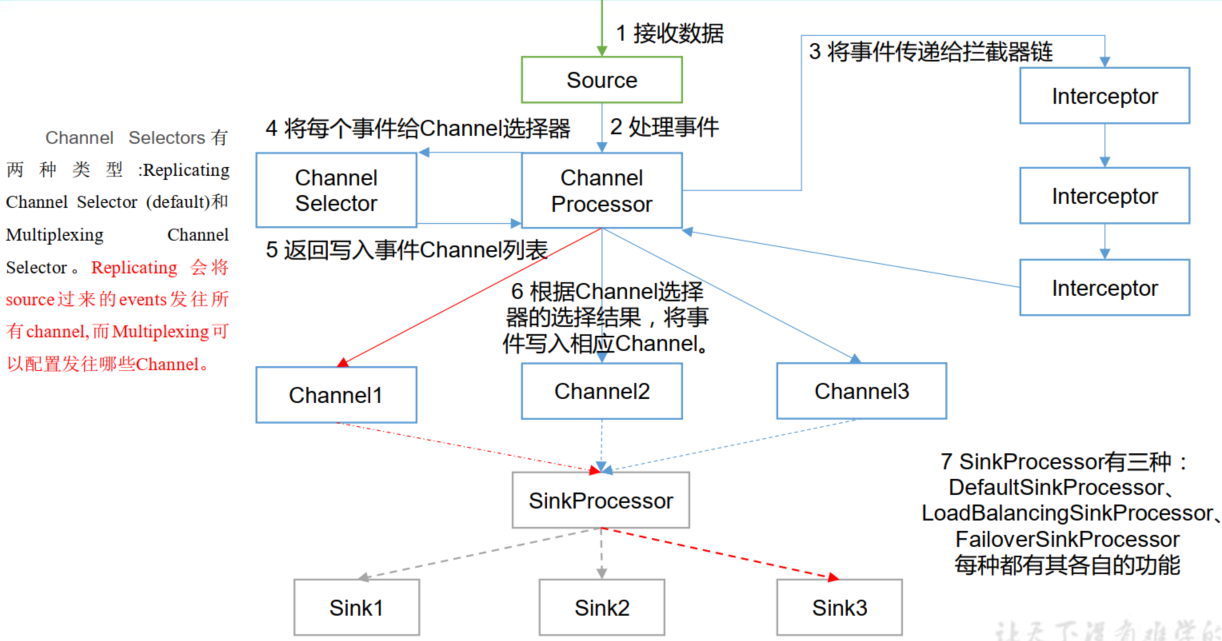
重要组件:
1) ChannelSelector
ChannelSelector 的作用就是选出 Event 将要被发往哪个 Channel。其共有两种类型,分别是 Replicating(复制)和 Multiplexing(多路复用)。
ReplicatingSelector 会将同一个 Event 发往所有的 Channel, Multiplexing 会根据相应的原则,将不同的 Event 发往不同的 Channel。
2) SinkProcessor
SinkProcessor 共 有 三 种 类 型 , 分 别 是 DefaultSinkProcessor 、LoadBalancingSinkProcessor 和 FailoverSinkProcessor、DefaultSinkProcessor 对 应 的 是 单 个 的 Sink , LoadBalancingSinkProcessor 和FailoverSinkProcessor 对应的是 Sink Group, LoadBalancingSinkProcessor 可以实现负载均衡的功能, FailoverSinkProcessor 可以实现故障转移的功能。
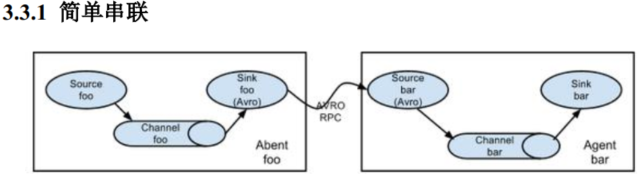
Flume 拓扑结构
Flume存在的单点故障,所以只能用的备份的一种机制。多个Flume读取一个文件。
如果是跨机器的采集,采用的是多个Flume的聚合。
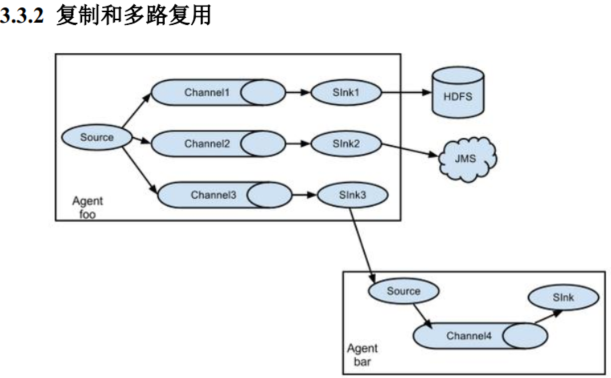
Flume 支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个,channel 中,或者将不同数据分发到不同的 channel 中, sink 可以选择传送到不同的目的地
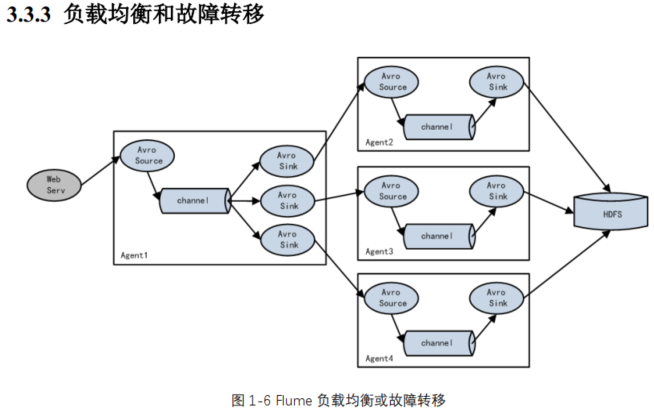
Flume支持使用将多个sink逻辑上分到一个sink组, sink组配合不同的SinkProcessor
可以实现负载均衡和错误恢复的功能。
这种模式是我们最常见的,也非常实用,日常 web 应用通常分布在上百个服务器,大者,甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用 flume 的这种组合方式能很好的解决这一问题, 每台服务器部署一个 flume 采集日志,传送到一个集中收集日志的flume,再由此 flume 上传到 hdfs、 hive、 hbase 等,进行日志分析。
Flume 自定义的拦截器
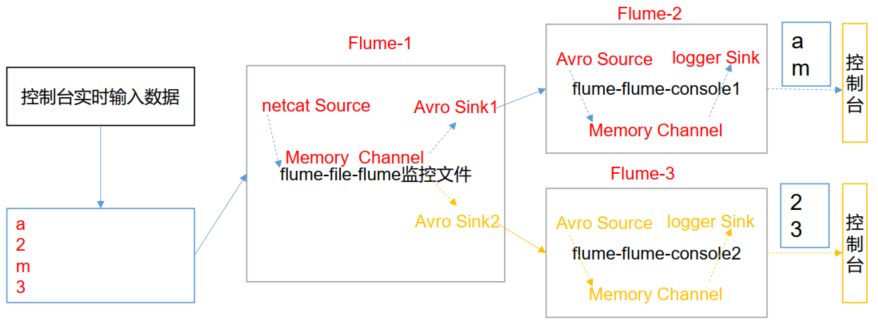
在实际的开发中,一台服务器产生的日志类型可能有很多种,不同类型的日志可能需要发送到不同的分析系统。此时会用到 Flume 拓扑结构中的 Multiplexing 结构, Multiplexing的原理是,根据 event 中 Header 的某个 key 的值,将不同的 event 发送到不同的 Channel
中,所以我们需要自定义一个 Interceptor,为不同类型的 event 的 Header 中的 key 赋予不同的值。在该案例中,我们以端口数据模拟日志,以数字(单个)和字母(单个)模拟不同类型的日志,我们需要自定义 interceptor 区分数字和字母,将其分别发往不同的分析系统(Channel)。
Flume自定义Source
Source 是负责接收数据到 Flume Agent 的组件。 Source 组件可以处理各种类型、各种
格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence、generator、syslog、http、legacy。官方提供的source 类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些 source。
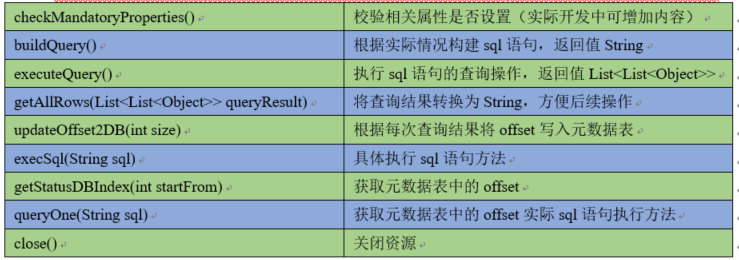
实现相应方法:
getBackOffSleepIncrement()//暂不用
getMaxBackOffSleepInterval()//暂不用
configure(Context context)//初始化 context(读取配置文件内容)
process()//获取数据封装成 event 并写入 channel,这个方法将被循环调用。
使用场景:读取 MySQL 数据或者其他文件系统。
Fume自定义 Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一
个事务。批量事件一旦成功写出到存储系统或下一个 Flume Agent, Sink 就利用 Channel 提交事务。事务一旦被提交,该 Channel 从自己的内部缓冲区删除事件。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。官方提供的 Sink 类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些 Sink。官方也提供了自定义 sink 的接口:https://flume.apache.org/FlumeDeveloperGuide.html#sink 根据官方说明自定义MySink 需要继承 AbstractSink 类并实现 Configurable 接口。
实现相应方法:
configure(Context context)//初始化 context(读取配置文件内容)
process()//从 Channel 读取获取数据(event),这个方法将被循环调用。
使用场景:读取 Channel 数据写入 MySQL 或者其他文件系统。
Flume 数据流监控
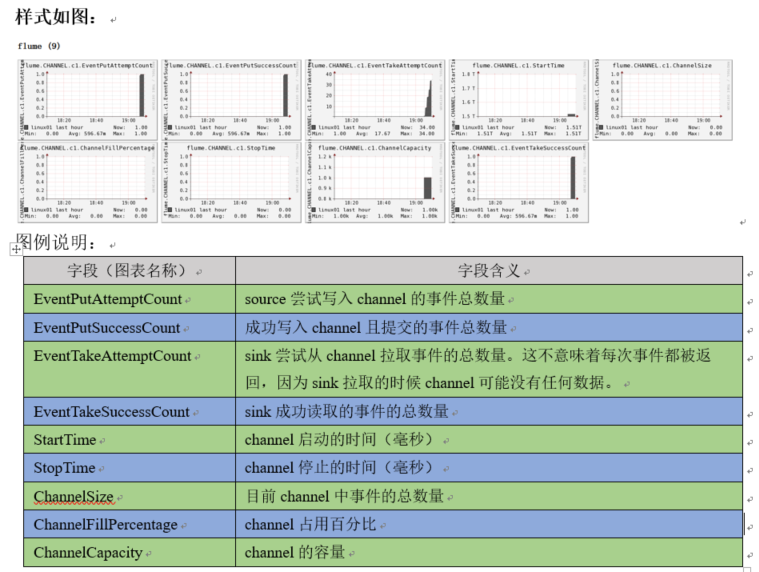
Ganglia 由 gmond、 gmetad 和 gweb 三部分组成。
gmond(Ganglia Monitoring Daemon)是一种轻量级服务,安装在每台需要收集指标数据的节点主机上。使用 gmond,你可以很容易收集很多系统指标数据,如 CPU、内存、磁盘、网络和活跃进程的数据等。
gmetad(Ganglia Meta Daemon)整合所有信息,并将其以 RRD 格式存储至磁盘的服务。
gweb(Ganglia Web) Ganglia 可视化工具, gweb 是一种利用浏览器显示 gmetad 所存储数据的 PHP 前端。在 Web 界面中以图表方式展现集群的运行状态下收集的多种不同指标数据
Flume的自定义的Mysql:
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。官方提供的source类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些Source。如:实时监控MySQL,从MySQL中获取数据传输到HDFS或者其他存储框架,所以此时需要我们自己实现MySQLSource。官方也提供了自定义source的接口:
官网说明:Flume 1.10.0 Developer Guide — Apache Flume
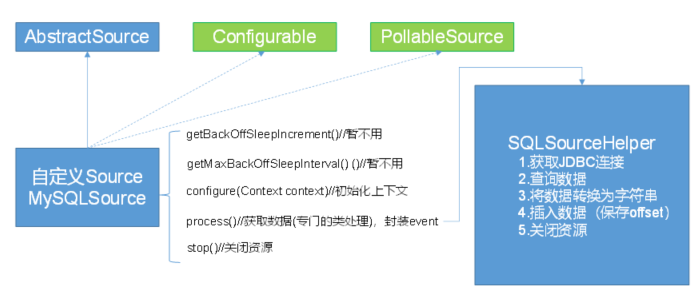
自定义MySQLSource步骤
根据官方说明自定义MySqlSource需要继承AbstractSource类并实现Configurable和PollableSource接口。
实现相应方法:
getBackOffSleepIncrement()//暂不用
getMaxBackOffSleepInterval()//暂不用
configure(Context context)//初始化context
process()//获取数据(从MySql获取数据,业务处理比较复杂,所以我们定义一个专门的类——SQLSourceHelper来处理跟MySql的交互),封装成Event并写入Channel,这个方法被循环调用
stop()//关闭相关的资源
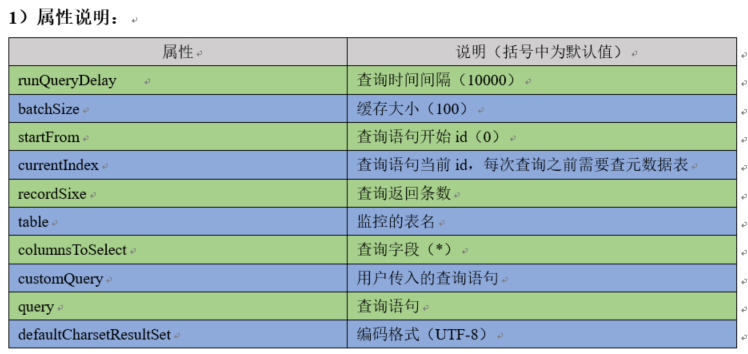

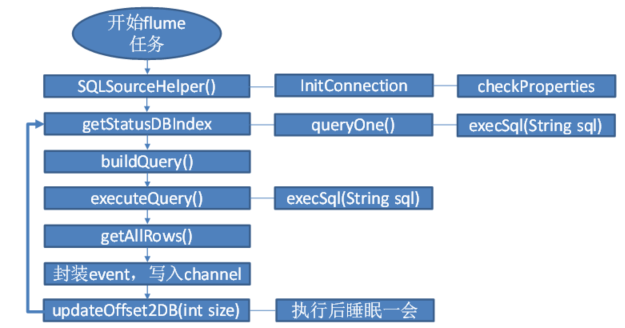
SQLSourceHelper源代码
public class SQLSourceHelper {
private static final Logger LOG = LoggerFactory.getLogger(SQLSourceHelper.class);
private int runQueryDelay, //两次查询的时间间隔
startFrom, //开始id
currentIndex, //当前id
recordSixe = 0, //每次查询返回结果的条数
maxRow; //每次查询的最大条数
private String table, //要操作的表
columnsToSelect, //用户传入的查询的列
customQuery, //用户传入的查询语句
query, //构建的查询语句
defaultCharsetResultSet;//编码集
//上下文,用来获取配置文件
private Context context;
//为定义的变量赋值(默认值),可在flume任务的配置文件中修改
private static final int DEFAULT_QUERY_DELAY = 10000;
private static final int DEFAULT_START_VALUE = 0;
private static final int DEFAULT_MAX_ROWS = 2000;
private static final String DEFAULT_COLUMNS_SELECT = "*";
private static final String DEFAULT_CHARSET_RESULTSET = "UTF-8";
private static Connection conn = null;
private static PreparedStatement ps = null;
private static String connectionURL, connectionUserName, connectionPassword;
//加载静态资源
static {
Properties p = new Properties();
try {
p.load(SQLSourceHelper.class.getClassLoader().getResourceAsStream("jdbc.properties"));
connectionURL = p.getProperty("dbUrl");
connectionUserName = p.getProperty("dbUser");
connectionPassword = p.getProperty("dbPassword");
Class.forName(p.getProperty("dbDriver"));
} catch (IOException | ClassNotFoundException e) {
LOG.error(e.toString());
}
}
//获取JDBC连接
private static Connection InitConnection(String url, String user, String pw) {
try {
Connection conn = DriverManager.getConnection(url, user, pw);
if (conn == null)
throw new SQLException();
return conn;
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
//构造方法
SQLSourceHelper(Context context) throws ParseException {
//初始化上下文
this.context = context;
//有默认值参数:获取flume任务配置文件中的参数,读不到的采用默认值
this.columnsToSelect = context.getString("columns.to.select", DEFAULT_COLUMNS_SELECT);
this.runQueryDelay = context.getInteger("run.query.delay", DEFAULT_QUERY_DELAY);
this.startFrom = context.getInteger("start.from", DEFAULT_START_VALUE);
this.defaultCharsetResultSet = context.getString("default.charset.resultset", DEFAULT_CHARSET_RESULTSET);
//无默认值参数:获取flume任务配置文件中的参数
this.table = context.getString("table");
this.customQuery = context.getString("custom.query");
connectionURL = context.getString("connection.url");
connectionUserName = context.getString("connection.user");
connectionPassword = context.getString("connection.password");
conn = InitConnection(connectionURL, connectionUserName, connectionPassword);
//校验相应的配置信息,如果没有默认值的参数也没赋值,抛出异常
checkMandatoryProperties();
//获取当前的id
currentIndex = getStatusDBIndex(startFrom);
//构建查询语句
query = buildQuery();
}
//校验相应的配置信息(表,查询语句以及数据库连接的参数)
private void checkMandatoryProperties() {
if (table == null) {
throw new ConfigurationException("property table not set");
}
if (connectionURL == null) {
throw new ConfigurationException("connection.url property not set");
}
if (connectionUserName == null) {
throw new ConfigurationException("connection.user property not set");
}
if (connectionPassword == null) {
throw new ConfigurationException("connection.password property not set");
}
}
//构建sql语句
private String buildQuery() {
String sql = "";
//获取当前id
currentIndex = getStatusDBIndex(startFrom);
LOG.info(currentIndex + "");
if (customQuery == null) {
sql = "SELECT " + columnsToSelect + " FROM " + table;
} else {
sql = customQuery;
}
StringBuilder execSql = new StringBuilder(sql);
//以id作为offset
if (!sql.contains("where")) {
execSql.append(" where ");
execSql.append("id").append(">").append(currentIndex);
return execSql.toString();
} else {
int length = execSql.toString().length();
return execSql.toString().substring(0, length - String.valueOf(currentIndex).length()) + currentIndex;
}
}
//执行查询
List<List<Object>> executeQuery() {
try {
//每次执行查询时都要重新生成sql,因为id不同
customQuery = buildQuery();
//存放结果的集合
List<List<Object>> results = new ArrayList<>();
if (ps == null) {
//
ps = conn.prepareStatement(customQuery);
}
ResultSet result = ps.executeQuery(customQuery);
while (result.next()) {
//存放一条数据的集合(多个列)
List<Object> row = new ArrayList<>();
//将返回结果放入集合
for (int i = 1; i <= result.getMetaData().getColumnCount(); i++) {
row.add(result.getObject(i));
}
results.add(row);
}
LOG.info("execSql:" + customQuery + "nresultSize:" + results.size());
return results;
} catch (SQLException e) {
LOG.error(e.toString());
// 重新连接
conn = InitConnection(connectionURL, connectionUserName, connectionPassword);
}
return null;
}
//将结果集转化为字符串,每一条数据是一个list集合,将每一个小的list集合转化为字符串
List<String> getAllRows(List<List<Object>> queryResult) {
List<String> allRows = new ArrayList<>();
if (queryResult == null || queryResult.isEmpty())
return allRows;
StringBuilder row = new StringBuilder();
for (List<Object> rawRow : queryResult) {
Object value = null;
for (Object aRawRow : rawRow) {
value = aRawRow;
if (value == null) {
row.append(",");
} else {
row.append(aRawRow.toString()).append(",");
}
}
allRows.add(row.toString());
row = new StringBuilder();
}
return allRows;
}
//更新offset元数据状态,每次返回结果集后调用。必须记录每次查询的offset值,为程序中断续跑数据时使用,以id为offset
void updateOffset2DB(int size) {
//以source_tab做为KEY,如果不存在则插入,存在则更新(每个源表对应一条记录)
String sql = "insert into flume_meta(source_tab,currentIndex) VALUES('"
+ this.table
+ "','" + (recordSixe += size)
+ "') on DUPLICATE key update source_tab=values(source_tab),currentIndex=values(currentIndex)";
LOG.info("updateStatus Sql:" + sql);
execSql(sql);
}
//执行sql语句
private void execSql(String sql) {
try {
ps = conn.prepareStatement(sql);
LOG.info("exec::" + sql);
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}
}
//获取当前id的offset
private Integer getStatusDBIndex(int startFrom) {
//从flume_meta表中查询出当前的id是多少
String dbIndex = queryOne("select currentIndex from flume_meta where source_tab='" + table + "'");
if (dbIndex != null) {
return Integer.parseInt(dbIndex);
}
//如果没有数据,则说明是第一次查询或者数据表中还没有存入数据,返回最初传入的值
return startFrom;
}
//查询一条数据的执行语句(当前id)
private String queryOne(String sql) {
ResultSet result = null;
try {
ps = conn.prepareStatement(sql);
result = ps.executeQuery();
while (result.next()) {
return result.getString(1);
}
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
//关闭相关资源
void close() {
try {
ps.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
int getCurrentIndex() {
return currentIndex;
}
void setCurrentIndex(int newValue) {
currentIndex = newValue;
}
int getRunQueryDelay() {
return runQueryDelay;
}
String getQuery() {
return query;
}
String getConnectionURL() {
return connectionURL;
}
private boolean isCustomQuerySet() {
return (customQuery != null);
}
Context getContext() {
return context;
}
public String getConnectionUserName() {
return connectionUserName;
}
public String getConnectionPassword() {
return connectionPassword;
}
String getDefaultCharsetResultSet() {
return defaultCharsetResultSet;
}
}
Mysqsources源代码
public class SQLSource extends AbstractSource implements Configurable, PollableSource {
//打印日志
private static final Logger LOG = LoggerFactory.getLogger(SQLSource.class);
//定义sqlHelper
private SQLSourceHelper sqlSourceHelper;
@Override
public long getBackOffSleepIncrement() {
return 0;
}
@Override
public long getMaxBackOffSleepInterval() {
return 0;
}
@Override
public void configure(Context context) {
try {
//初始化
sqlSourceHelper = new SQLSourceHelper(context);
} catch (ParseException e) {
e.printStackTrace();
}
}
@Override
public Status process() throws EventDeliveryException {
try {
//查询数据表
List<List<Object>> result = sqlSourceHelper.executeQuery();
//存放event的集合
List<Event> events = new ArrayList<>();
//存放event头集合
HashMap<String, String> header = new HashMap<>();
//如果有返回数据,则将数据封装为event
if (!result.isEmpty()) {
List<String> allRows = sqlSourceHelper.getAllRows(result);
Event event = null;
for (String row : allRows) {
event = new SimpleEvent();
event.setBody(row.getBytes());
event.setHeaders(header);
events.add(event);
}
//将event写入channel
this.getChannelProcessor().processEventBatch(events);
//更新数据表中的offset信息
sqlSourceHelper.updateOffset2DB(result.size());
}
//等待时长
Thread.sleep(sqlSourceHelper.getRunQueryDelay());
return Status.READY;
} catch (InterruptedException e) {
LOG.error("Error procesing row", e);
return Status.BACKOFF;
}
}
@Override
public synchronized void stop() {
LOG.info("Stopping sql source {} ...", getName());
try {
//关闭资源
sqlSourceHelper.close();
} finally {
super.stop();
}
}
}
Flume的面试题目:
Flume 的 Source, Sink, Channel 的作用?你们 Source 是什么类型?
1、Source 组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括 avro、 thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、 legacy
2、Channel 组件对采集到的数据进行缓存,可以存放在 Memory 或 File 中。
3、Sink 组件是用于把数据发送到目的地的组件,目的地包括 HDFS、 Logger、 avro、thrift、 ipc、file、Hbase、solr自定义。
2、我公司采用的 Source 类型为:
(1)监控后台日志: exec
(2)监控后台产生日志的端口: netcat Exec spooldir
Flume 的 Channel Selectors
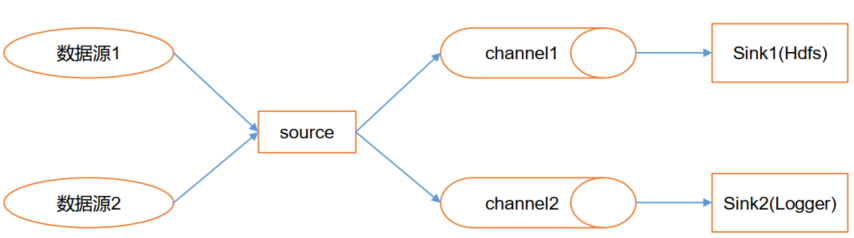
Channel Selectors, 可以让不同的项目日志通过不同的Channel到不同的Sink中去。
官方文档上Channel Selectors 有两种类型:Replicating Channel Selector (default)和
Multiplexing Channel Selector
这两种Selector的区别是:Replicating 会将source过来的events发往所有channel,而
Multiplexing可以选择该发往哪些Channel。
Flume 参数调优
1. Source
增加 Source个(使用TairDir Source 时可增加 FileGroups个数)可以增大 Source 的读
取数据的能力。例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件
目录,同时配置好多个 Source 以保证 Source 有足够的能力获取到新产生的数据。batchSize 参数决定 Source 一次批量运输到 Channel 的 event 条数,适当调大这个参数可以提高 Source 搬运 Event 到 Channel 时的性能。
2. Channel
type 选择 memory 时 Channel 的性能最好,但是如果 Flume 进程意外挂掉可能会丢失数据。type 选择 file 时 Channel 的容错性更好,但是性能上会比 memory channel 差。使用 file Channel 时 dataDirs 配置多个不同盘下的目录可以提高性能。Capacity 参数决定 Channel 可容纳最大的 event 条数。 transactionCapacity 参数决定每次 Source 往 channel 里面写的最大 event 条数和每次 Sink 从 channel 里面读的最大 event条数。 transactionCapacity 需要大于 Source 和 Sink 的 batchSize 参数。
3. Sink
增加 Sink 的个数可以增加 Sink 消费 event 的能力。 Sink 也不是越多越好够用就行,过
多的 Sink 会占用系统资源,造成系统资源不必要的浪费。
batchSize 参数决定 Sink 一次批量从 Channel 读取的 event 条数,适当调大这个参数可
以提高 Sink 从 Channel 搬出 event 的性能。
Flume 的事务机制
Flume的事务机制(类似数据库的事务机制):Flume 使用两个独立的事务分别负责从Soucrce 到 Channel,以及从 Channel 到 Sink 的事件传递。比如 spooling directory source
为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到 Channel 且提交成功,那
么 Soucrce 就将该文件标记为完成。同理,事务以类似的方式处理从 Channel 到 Sink 的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持
到 Channel 中,等待重新传递。
Flume 采集数据会丢失吗?
根据 Flume 的架构原理,Flume 是不可能丢失数据的,其内部有完善的事务机制,Source 到 Channel 是事务性的, Channel 到 Sink 是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是 Channel 采用 memoryChannel, agent 宕机导致数据丢失,或者 Channel 存储数据已满,导致 Source 不再写入,未写入的数据丢失。Flume 不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由 Sink 发出,但是没有接收到响应, Sink 会再次发送数据,此时可能会导致数据的重复。
flume的memeryChannel中transactionCapacity和sink的batchsize需要注意事项
近在做flume的实时日志收集,用flume默认的配置后,发现不是完全实时的,于是看了一下,原来是memeryChannel的transactionCapacity在作怪,因为他默认是100,也就是说收集端的sink会在收集到了100条以后再去提交事务(即发送到下一个目的地),于是我修改了transactionCapacity到10,想看看是不是会更加实时一点,结果发现收集日志的agent启动的时候报错了。于是很纳闷,为什么默认值100可以,而设置10就会说小了呢,于是查阅资料,发现原来是sink的batchsize参数在作怪,下面,我就来理一理这个来龙去脉,这个sink的batchsize是什么意思呢,就是sink会一次从channel中取多少个event去发送,而这个发送是要最终以事务的形式去发送的,因此这个batchsize的event会传送到一个事务的缓存队列中(takeList),这是一个双向队列,这个队列可以在事务失败时进行回滚(也就是把取出来的数据吐memeryChannel的queue中),它的初始大小就是transactionCapacity定义的大小,
takeList = new LinkedBlockingDeque<Event>(transCapacity);
if(takeList.remainingCapacity() == 0) {
throw new ChannelException("Take list for MemoryTransaction, capacity " +
takeList.size() + " full, consider committing more frequently, " +
"increasing capacity, or increasing thread count");
}在上面的情况中,sink一次取100个events,塞到takelist中,在塞了10个后,就会引发上述异常,因此,这个错误的解决办法就是:在sink中,channel的transactionCapacity参数不能小于sink的batchsize。有点不明白,这么明显的一个坑,apache为什么不去补一下呢?
最后
以上就是尊敬黑裤最近收集整理的关于大数据技术——Flume原理分析摘要Flume概述的全部内容,更多相关大数据技术——Flume原理分析摘要Flume概述内容请搜索靠谱客的其他文章。








发表评论 取消回复