个性推荐系列目录:
个性推荐②—基于用户协同过滤算法原及优化方案
个性推荐③—基于物品的协同过滤算法及优化方案
本文是整理于个性推荐经典之作《推荐系统实战》,将会以十个大家最想问的问题,揭开个性化推荐系统的神秘面纱(文末有免费下载方式)
一、你觉得个性推荐系统是什么?
分类查询,搜索引擎查询,再到个性推荐,都是解决信息过载的问题
前两者是在用户有明确需求时,可以非常方便地找到自己感兴趣的信息,而个性推荐是要解决当用户没有明确需求,或者无法用文字进行描述时,根据用户的历史行为,推荐给他感兴趣的信息
个性推荐的作用就是连接用户和信息:一是帮助用户发现自己感兴趣的信息,二是让信息尽可能展现给对它感兴趣的用户面前,实现用户和信息的双赢
在电商行业,个性推荐还可以根据用户的个性化需求,将用户感兴趣的长尾物品推荐给用户。零售货架成本高昂,因此20% 的主流商品可以实现80%的销售额,但是电商,由于货架非常便宜,
可以卖出更多平时难以见到的商品,这些商品小众但是数量多,总销售额也未必比主流商品低。
二、个性推荐系统一般有哪些方法?
1、社交推荐——问朋友,问社群
2、基于内容推荐——看过的电影导演,演员等,物品上的标签等
3、基于协同过滤算法——基于用户相似,或物品相似
三、个性推荐系统如何实现?
通过分析大量的用户行为日志,给用户提供不同的个性化页面展示,进而提高页面的点击率和转化率
主要应用领域:电商,影视,阅读,音乐,社交
主要由三部分组成:前端展示 + 后端的日志系统 + 推荐算法
四、个性推荐做得好的有哪些?
1、电商
亚马逊,贡献了20%的销售额,包括2类:
个性化推荐
① 基于物品的协同过滤——给用户推荐他们之前喜欢过的物品相似的物品
② 基于社交推荐——给用户推荐他们好友感兴趣的物品
相关推荐——打包销售,给予一定折扣
③ 基于购买——购买过这个商品的用户也会购买的其它商品
④ 基于浏览——浏览过这个商品的用户经常购买的其它商品
2、影视
网飞(Netflix)——60%用户通过个性推荐找到感兴趣的电影——基于物品的协同过滤
Youtube——基于物品协同过滤——与热门排行榜点击率相比,个性化推荐是2倍
3、音乐电台
Pandora(潘多拉电台)——基于内容推荐,音乐专家听了成千上万首不同歌手的歌曲,对特征(旋律,节奏,歌词,风格,编曲)等进行了标注,也就是音乐的基因,
根据基因计算不同歌曲的相似度,给用户推荐相似度高的歌曲
Last.fm——基于用户的协同过滤,基于用户历史的听歌记录和反馈,计算不同用户在歌曲上的喜好相似度,给用户推荐其它与用户有相似爱好的用户喜欢的歌曲
4、个性化邮件
谷歌邮箱——基于用户对邮件的历史行为,找到用户感兴趣的邮件,展示在一个专门的收件夹里,用户可以优先浏览——节约了6%的时间
五、使用个性推荐系统的前提是什么?
1、存在信息过载,如果没有信息过载,就不需要个性化推荐,比如直播行业,主播并不多,推来推去就那几个
2、用户在大多数时候并没有明确的需求
六、好的推荐系统有哪些标准?
1、是否能满足用户需求,推荐给他们真正感兴趣的物品
2、是否可以尽可能让所有的物品都能展示给对他感兴趣的用户,而不是仅仅热门或主流的物品
3、推荐系统是否可以跟用户进行互动,得到高质量的反馈,进而进行自我优化
七、推荐系统有哪些评价指标?
1、用户满意度
① 用户问卷调查——从不同侧面询问用户的感受
② 在线行为统计——电商(推荐购买率),反馈按钮,一般是点击率,用户停留时长和转化率等度量用户的满意度
2、预测准确度——可以离线实现计算,方便研究
① 评分预测
通过用户的历史评分,习得用户的兴趣模型,并预测该用户将来看到一个没有评分的物品,会给多少分
用均方根误差和平均绝对误差计算,前者加大了对预测不准的用户物品评分项的惩罚,因而对系统的评测更加严苛
②TOPN推荐
给用户提供一个个性化的推荐列表
准确率和召回率计算,一般会选取不同长度的推荐列表N,计算出一组准确率和召回率,然后画出曲线
3、覆盖率
定义1:推荐系统推荐出来的物品占总物品集合的比例,热门排行榜的覆盖率是很低的
定义2:研究物品在推荐系统中出现次数的分布,如果推荐系统能推荐出所有的物品,且推荐的物品出现次数都差不多,就说明可以发掘长尾的能力。
用信息熵和基尼系数计算(流行度作为概率),基尼系数是用面积计算。SA/(SA+SB),从最不热门到最热门的累计流行度占比面积图
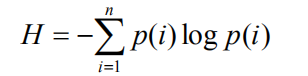
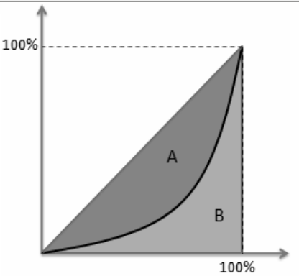
4、多样性
推荐列表要满足用户多种多样的兴趣,而不是只推荐他最感兴趣的
多样性是描述推荐列表中物品两两的不相似性,多样性和相似性是对应的
5、新颖性
推荐给用户他们之前没有听说过的物品,把用户之前有过行为的物品从推荐列表中去掉,但这不能去除他们在其余平台上看过的
最简单方法就是看推荐物品的平均热门程度,如果较低,则新颖性越高
6、惊喜度
找到与用户历史上喜欢的物品不相似,但是却能用户觉得满意
如果获得用户观看电影历史,根据内容找到用户可能感兴趣的电影集合,然后再推荐一个不属于此集合的电影,而用户看了还特别满意
7、信任度
① 给予推荐解释,并增加用户与推荐系统的交互
② 利用社交网络信息,用好友信息给用户做推荐
8、实时性
新闻,微博等具有很强实效性,要在物品还具有实效性时就推荐给用户才行。
① 实时更新推荐列表来满足用户新的需求(买了瑜伽垫,推荐其它一些健身产品)
② 将新加入的物品推荐给用户(用户推荐列表中有多大比例是当天新加的物品)
9、鲁棒性,健壮性
健壮性就是衡量一个推荐系统抗击作弊的能力,利用算法规则增加推荐的次数和排名(购买过A的商品也经常购买B,注册大量账号,同时购买A,B,A是非常热门的商品,而B是想要作弊的商品)
评测采用模拟攻击,用常用的攻击方法给数据集注入噪声数据,再次给用户生成推荐列表,比较前后推荐列表的相似度,如果没啥变化就较好
防止措施:
① 涉及推荐系统尽量使用代价较高的用户行为,比如点击和购买,肯定优先用购买
② 使用数据建模前,先进行攻击检测,清理掉那些明显是刷出来的数据
对于离线优化目标:在限定覆盖率,多样性,新颖性等条件下,优化预测准确度

八、推荐系统有哪些评测维度?
除了评测指标,还要考虑评测维度,比如有的推荐算法,虽然整体性能不佳,但是在某些情况下很好。找到看上去弱的算法的优化,以及强的算法的缺点,融合不同算法找到最好的整体性能
① 用户维度: 人口统计学信息,活跃度及是否是新用户
② 物品维度:物品属性,流行度,平均分是不是新加入的物品
③ 时间维度:季节,工作日或周末,白天还是晚上等
九、推荐系统上线从开发到上线需要经历哪些过程?
1、离线算法——仅需要数据集,不需要用户参与,可以方便快速地计算多个算法,缺点是无法获得很多商业上关注的指标,比如点击率,转化率等
① 通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集
② 将数据集分成训练集和测试集
③ 在训练集上训练用户兴趣模型,在测试集上进行预测
④通过事先定义的离线评测指标对算法在测试集上的预测结果进行评测
2、用户调研——需要真实用户,可以获得离线时无法知晓的用户主管感受,缺点成本高昂,不能进行大规模的测试,样本过少得到的结论又很难具有统计学意义
① 找到一批与真实用户分布类似的用户群体
② 让他们在测试的推荐系统上完成一些任务,观察他们的行为,并回答一些问题
③ 分析他们的行为和答案来了解推荐系统的性能
3、A/B TEST——获得不同算法在实际在线时的性能指标,包括商业感兴趣的指标,缺点是测试周期比较长。
① 设定流量分配规则,将用户分成不同的组
② 对不同的组采用不同的算法,统计不同组用户的各项评测指标来比较不同的算法(点击率)
概括如下:
通过离线实验证明它在很多离线指标上优于现有算法
通过用户调查证明它的用户满意度不低于现有算法
通过A/B test 证明它在我们关系的指标上优于现有算法
十、个性化系统中常说的长尾分布到底是什么?
幂次分布,也叫做长尾分布,最早是在研究英文单词的词频时发现,将单词出现的频率从高到低排序,发现单词出现的词频与热门排行榜排名的常数次幂成反比,说明经常使用的单词其实很少
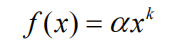
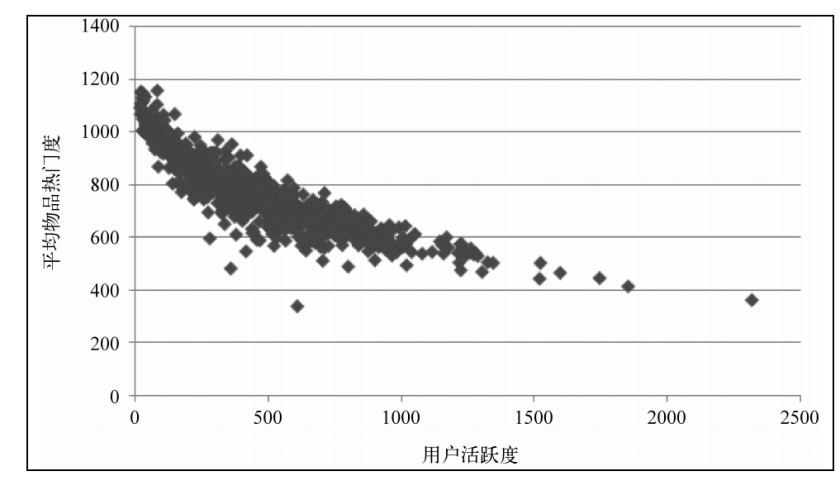
用户行为数据也包含这种分布,比如用户活跃度和物品流行度(前者是用用户产生过行为的商品数,后者是给物品产生过行为的用户数),以用户活跃度为横坐标,此活跃度下的用户数为纵坐标,取双对数就是一条直线
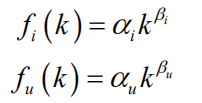
用户活跃度和物品流行度的关系,横坐标是用户活跃度,纵坐标是此活跃度下用户产生过行为的物品的平均流行度。用户越活跃,越倾向于浏览冷门的商品
下一篇将会总结最经典的个性推荐算法-基于用户协同过滤算法,感兴趣的小伙伴可以关注下我喔
本人互联网数据分析师,目前已出Excel,SQL,Pandas,Matplotlib,Seaborn,机器学习,统计学,个性推荐,关联算法,工作总结系列。
微信搜索并关注 " 数据小斑马" 公众号
1、回复“推荐”就可以领取文中书籍一本
2、回复“数据分析”可以免费获取下方15本数据分析师必备学习书籍一套

最后
以上就是神勇红牛最近收集整理的关于个性推荐①——系统总结个性化推荐系统的全部内容,更多相关个性推荐①——系统总结个性化推荐系统内容请搜索靠谱客的其他文章。








发表评论 取消回复