本文是在‘学堂在线’app学习大数据系统基础的笔记,鉴于时间原因我仅做概述,如果大家想更深入的了解可以去接去学堂在线搜索“大数据系统基础”学习相关课程。
本人在大数据学习也是小学生,理解不当之处可以指出进行修改。
分布式文件系统:
- 回顾本地系统的相关知识
- 处理数据的方法
- 分布式文件系统的概述
- Google文件系统原理(注意扩展性和可靠性方面的考虑)
文件系统概述
为什么需要文件系统?
文件处理放在内存中的,计算是用处理器中的。需要长期使用的就存在文件系统中供上层使用。
文件系统的名字空间
文件系统就是目录树(c:…D:…),从根目录一级一级的往下访问
文件系统名字空间的操作
就是对目录树结构的操作
文件系统的文件读写操作
通过函数操作:open打开文件,read读文件,write写文件,close关闭文件(将内核数据从内核中删除)
有open就一定有close否则就会有内存溢出的情况,使得系统无法操作。
namespace(的操作)
文件系统的设计
文件系统的下层接口
- 磁盘的读写接口,磁盘的地址(抽象概念)由磁盘驱动程序去做的。
文件系统的上层接口
- 目录树的组织
- 文件数据的读写
文件系统在系统中的位置
- 文件系统最本质的功能:将文件名字翻译定位到一个具体的磁盘位置,进而可以完成文件的读写。
文件系统接口标准化
- 虚拟文件系统(VFS)是由Sun microsystems公司在定义网络文件系统(NFS)时创造的。它是一种用于网络环境的分布式文件系统,是允许和操作系统使用不同的文件系统实现的接口。虚拟文件系统(VFS)是物理文件系统与服务之间的一个接口层,它对Linux的每个文件系统的所有细节进行抽象,使得不同的文件系统在Linux核心以及系统中运行的其他进程看来,都是相同的。严格说来,VFS并不是一种实际的文件系统。它只存在于内存中,不存在于任何外存空间。VFS在系统启动时建立,在系统关闭时消亡。
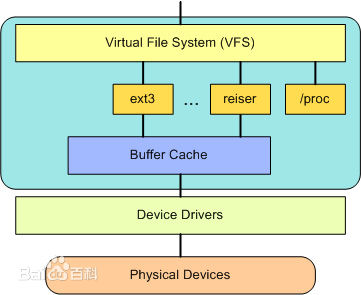
应用程序通过VFS接口可以不用关心底层文件模块直接调用文件资源。
文件系统的讨论
关于磁盘块大小的讨论
文件块设计太小,文件块随机存放会降低磁盘性能,文件块设计太大,增加磁盘管理大小,也会对磁盘性能有一定影响,而对于文件块的大小设计需要根据具体程序要设计。
文件系统的缓存
- 缓存能够加速的必要条件 ,时间局部性与空间局部性。(被访问的数据,最近也被访问到;而空间局部性就是被访问的文件附近的数据也会被访问到)
磁盘系统的优化策略
-
磁盘的顺序读写与随机读写
-
如何进行磁盘优化
(先确定有几个磁片,一般有三个,然后确定磁盘的上面还是下面,确定磁盘之后再确定磁道,确定磁道以后就可以对文件进行读写。)
(在同一磁道读写,与在不同磁道读写的性能是不一样的。在顺序读写有100~200MB的读写带宽,而随机读写有1MB的带宽就已经很不错了)
分布式文件系统与本地文件系统
分布式文件系统
-
系统目录树
-
文件的读写
(以上是文件系统的基本要求)
分布式文件系统是多个机器的集群。
分布式文件系统建立的基础 -
直接面对磁盘?
-
分布式文件系统中的地址是什么?
建立在每个机器上面有一个操作系统管理机器上的磁盘,操作的就直接面对操作系统而不是面对磁盘。
分布式文件系统1,定位到那台机器。2,会在机器本地的一个local FS定位到磁盘上。
总结:分布式文件系统的本质功能:将一个以目录树表达的文件翻译为一个具体的节点,而到磁盘的定位则可以交给本地文件系统去完成。
扩展SANFS:网格分布式存储系统,可以直接跟磁盘打交道。
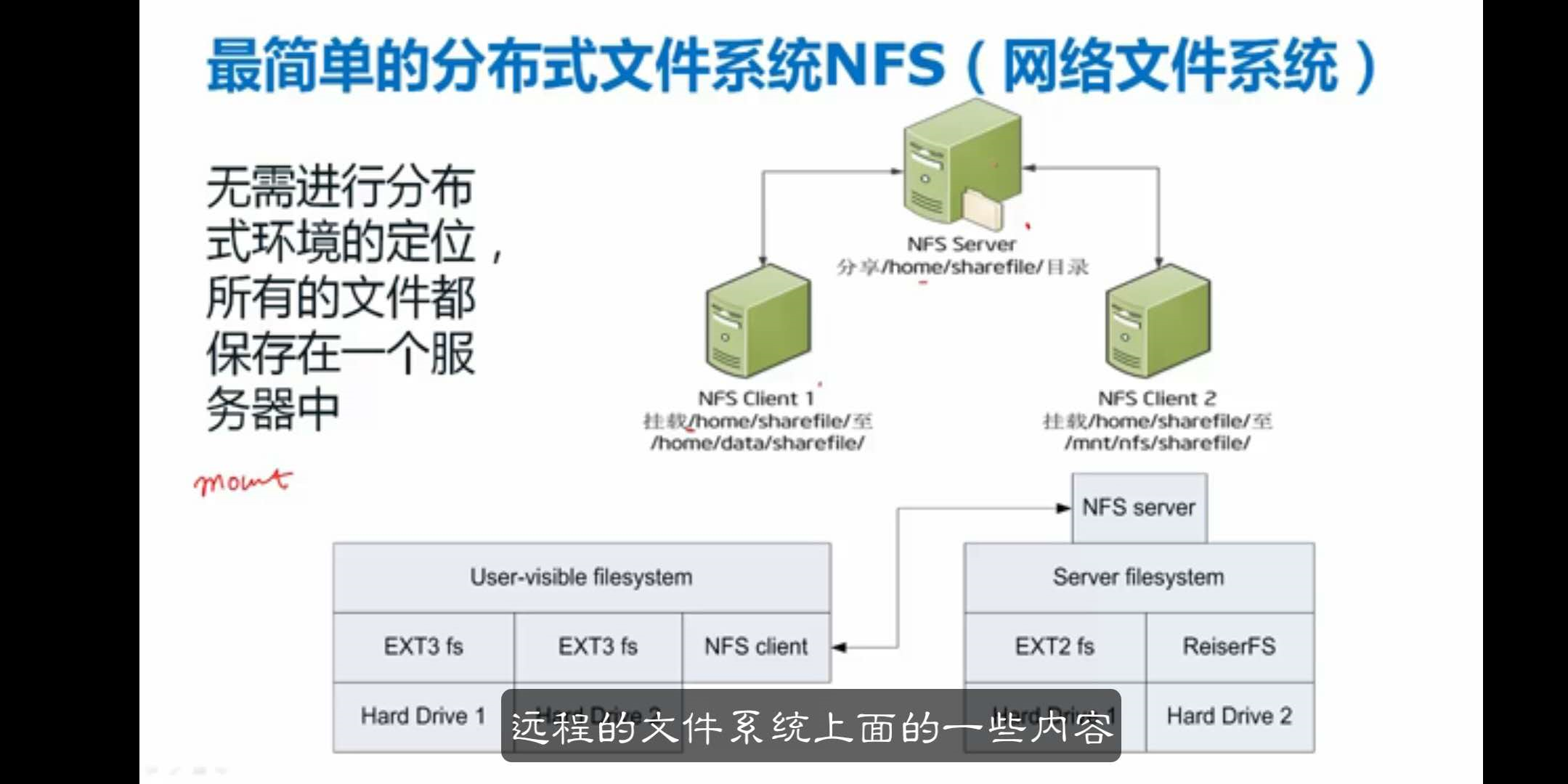
最简单的分布式文件系统NFS(网络文件系统)
一台服务器与客户端服务器
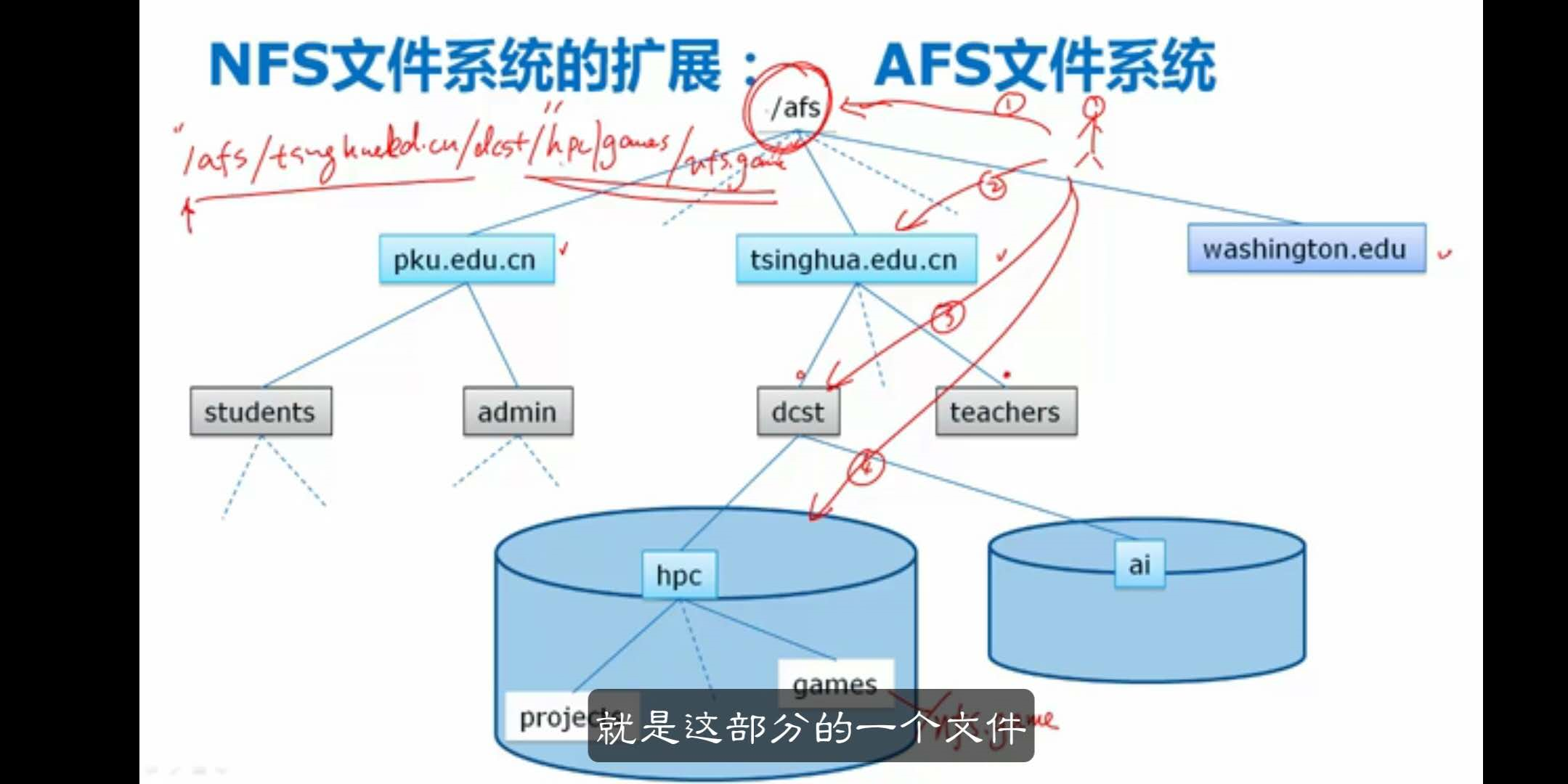
NFS文件系统的扩展:AFS文件系统
首先根据根服务器—下一级目录的定位信息—下一级维护下一级目录----最后引导到最后一级的服务器。
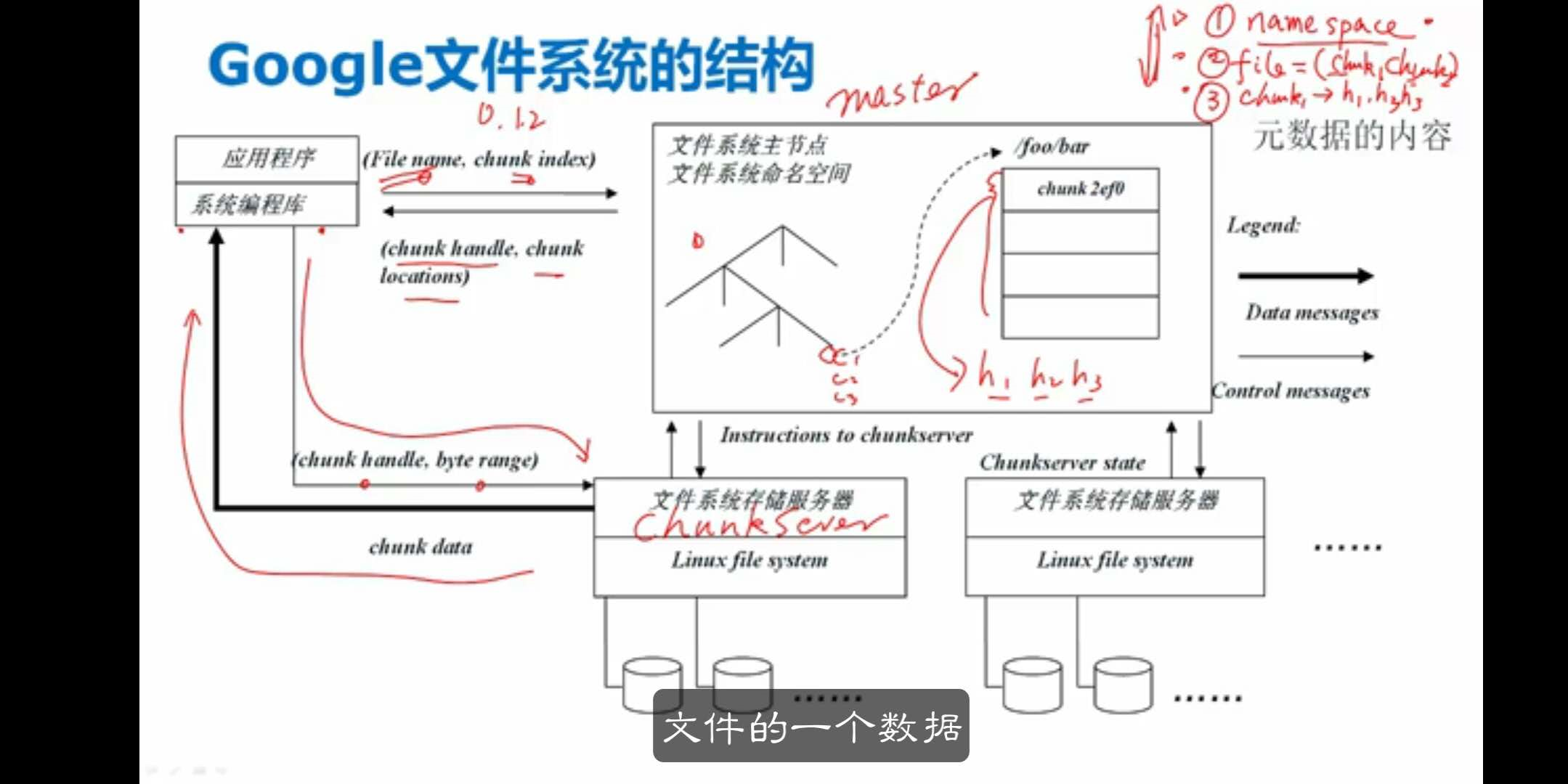
Google文件系统原理
为什么需要一个不同分布式文件系统
-
为了简历搜索引擎,需要存储互联网容量数据,支持数据块快速写入到分布式文件系统中
-
为了支持查询,需要对大量数据进行处理,需要简历倒排所以,需要对网页数据进行排序
-
都是应用驱动的,需要建立一个新的风不是文件系统。
倒排索引:已经提前将搜索数据搜索出来了,然后再将数据结果给使用者。
建立跨数千个节点的文件系统
几个目标:
我们需要做一个文件系统(目录树,文本读写)支持读写非常大的文件 -
充分利用资源(负载均衡,扩展性)
-
容错(不能因为少数的节点出错就停止工作)
-
系统简洁(复杂的系统在涉及到数千个节点的时候无法理解与控制)

Goole文件系统的结构
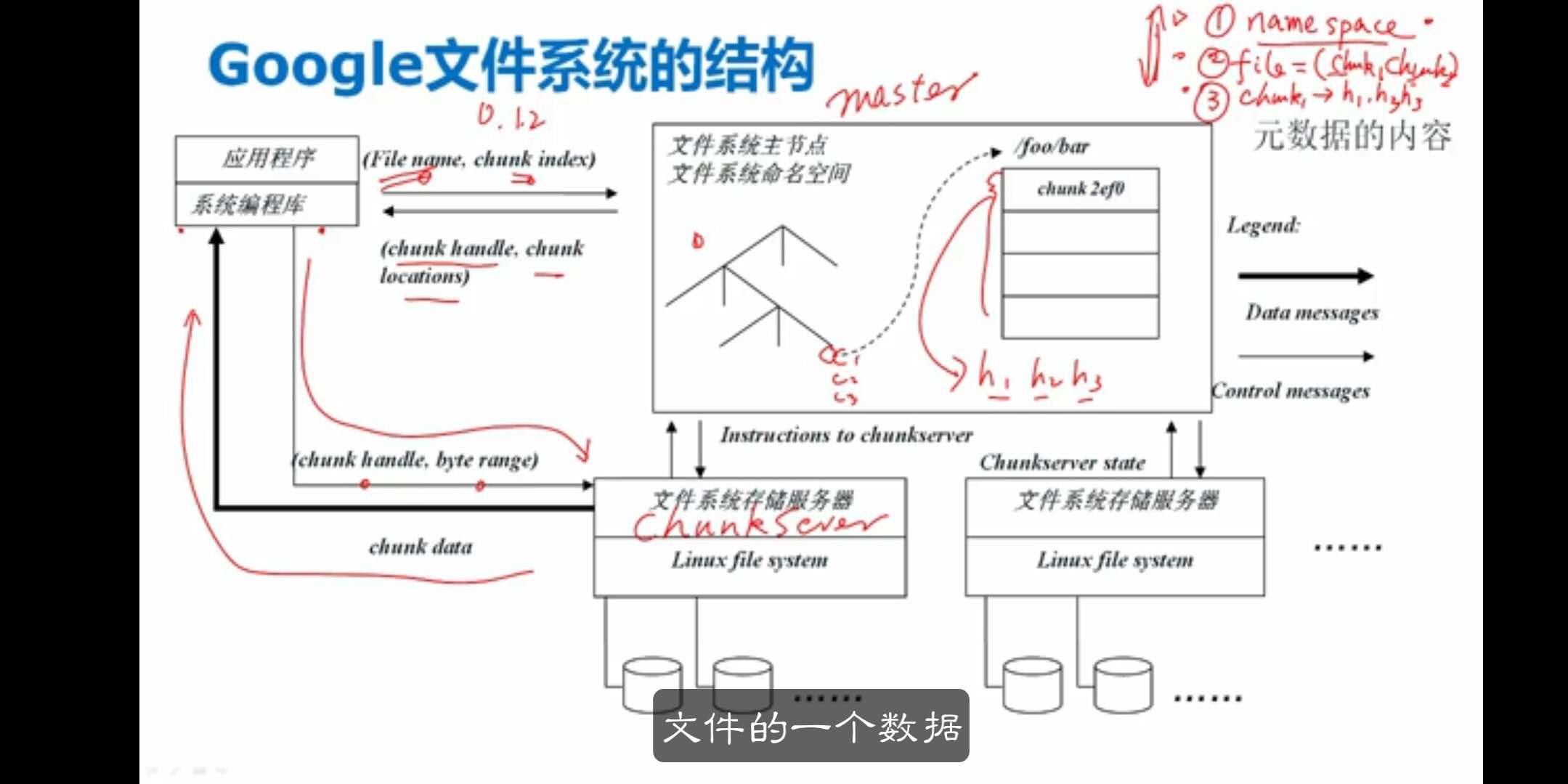

GFS性能问题
块服务器的负载均衡问题 -
不能让一部分块服务器出现性能瓶颈
-
负载必须进行动态调整
快服务器的扩展性问题
- 加入一个服务器怎么办
64MB对应元数据是64b
主服务器的性能负载问题
- 元数据的计算过程
10PB数据对应元数据10G。
GFS的可靠性问题
块服务器的可靠性问题
- 块服务器器出现错误怎么办
- 一个块服务器出现错误的时候,副本数目恢复所需要的时间(并行需要两小时,串行只需要1秒)
主服务器的可靠性问题
- 内存数据的可恢复性(日志操作,快速恢复)
- 单个节点主服务器的可恢复性(日志文件的存在)
- 影子节点仍然会出现错误
Google一致性要求
传统文件系统的一致性体现(一份数据的隐含地址操作)
三副本一致性的基本要求
更改数据的操作(读操作不会影响一致性)
数据的写入write操作接口
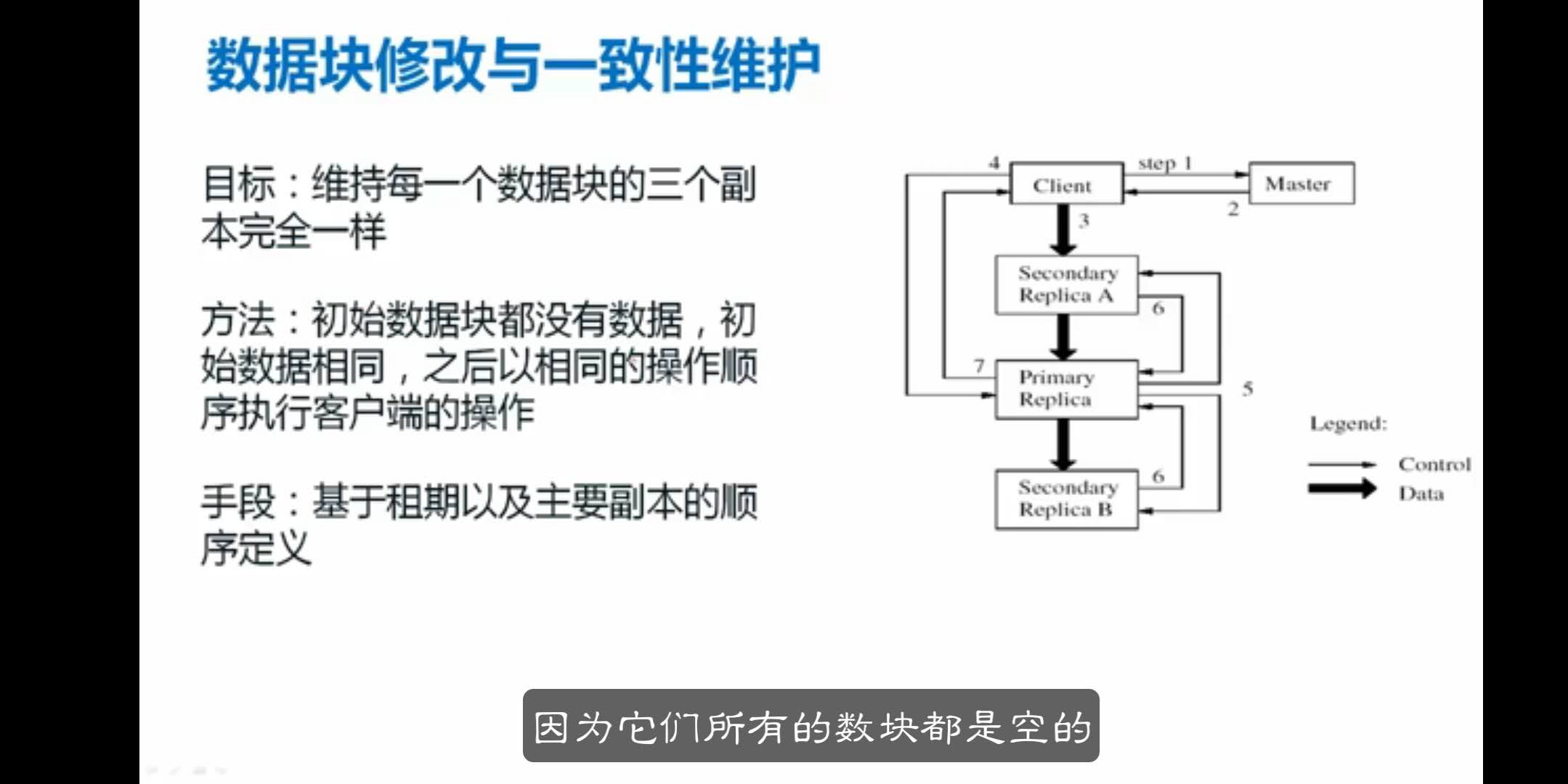
GFS中的放松的一致性

GFS的POSIX兼容性



最后
以上就是舒适小虾米最近收集整理的关于大数据系统基础--文件存储【学习笔记】的全部内容,更多相关大数据系统基础--文件存储【学习笔记】内容请搜索靠谱客的其他文章。








发表评论 取消回复