絮叨两句:
博主是一名数据分析实习生,利用博客记录自己所学的知识,也希望能帮助到正在学习的同学们
人的一生中会遇到各种各样的困难和折磨,逃避是解决不了问题的,唯有以乐观的精神去迎接生活的挑战
少年易老学难成,一寸光阴不可轻。
最喜欢的一句话:今日事,今日毕
企业级360°全方位用户画像:标签开发(前期准备工作)
PSM模型引入
???? 点击下面链接了解大数据杀熟
人人憎恨的大数据杀熟你了解吗? 大数据杀熟”是否真的存在?
PSM模型在网游中的运用
PSM(Price Sensitivity Measurement)模型是在70年代由Van Westendrop所创建,其目的在于衡量目标用户对不同价格的满意及接受程度,了解其认为合适的产品价格,从而得到产品价格的可接受范围。
PSM的定价是从消费者接受程度的角度来进行的,既考虑了消费者的主观意愿,又兼顾了企业追求最大利益的需求。
此外,其价格测试过程完全基于所取购买对象的自然反应,没有涉及到任何竞争对手的信息。
虽然缺少竞品信息是PSM的缺陷所在,由于每个网络游戏均自成一个虚拟的社会体系,一般来说,其中每个道具或服务的销售均没有竞品(除非开发组自己开发了类似的道具或服务,产生了内部竞争),从这个角度来说,PSM模型比较适合用于网游中的道具或服务的定价。
此外,该模型简洁明了,操作简单,使用非常方便。
PSM模型实施具体步骤
第一步:通过定性研究,设计出能够涵盖产品可能的价格区间的价格梯度表。
该步骤通常对某一产品或服务追问被访者4个问题,并据此获得价格梯度表。
梯度表的价格范围要涵盖所有可能的价格点,最低和最高价格一般要求低于或高出可能的市场价格的三倍以上
- 便宜的价格:对您而言什么价格该道具/服务是很划算,肯定会购买的?
- 太便宜的价格:低到什么价格,您觉得该道具/服务会因为大家都可以随便用,而对自己失去吸引力(或对游戏造成一些不良影响)?
- 贵的价格:您觉得“有点高,但自己能接受”的价格是多少?
- 太贵的价格:价格高到什么程度,您肯定会放弃购买?
第二步:取一定数量有代表性的样本,被访者在价格梯度表上做出四项选择:
- 有点低但可以接受的价格
- 太低而不会接受的价格
- 有点高但可以接受的价格
- 太高而不会接受的价格。
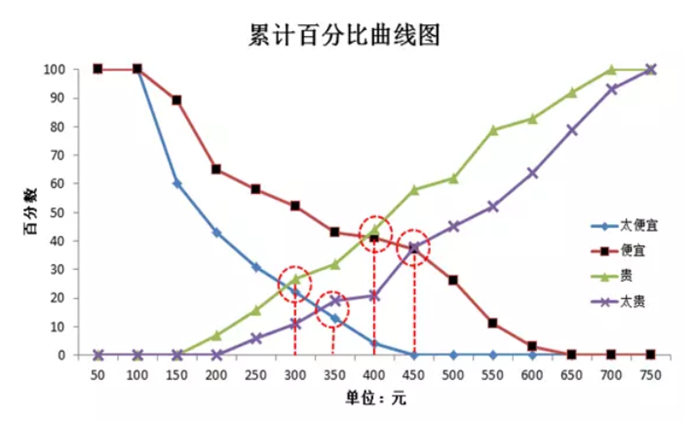
第三步 :对所获得的样本数据绘制累计百分比曲线图,四条曲线的交点得出产品的合适价格区间以及最优定价点和次优定价点。
如下图:
对“便宜”和“太便宜”向下累计百分数(因为价格越低消费者越觉得便宜,即认为某价格便宜的消费者也会认为低于此价格的价格便宜)
“贵”和“太贵”向上累计百分数(因为价格越高消费者越觉得贵,即认为某价格贵的消费者也会认为高于此价格的价格贵)能够得到四条累计百分比曲线
“太便宜”和“贵”的交点意味着此价格能够让最多的人觉得“不会便宜到影响购买意愿,即使可能有点贵也是能够接受的”
“便宜”和“太贵”的交点意味着此价格能够让最多的人觉得“不会贵到不能接受,还是挺划算的”
因此这两个交点分别为价格区间的下限和上限。低于前者,消费者会因为担心“过于大众不能体现优越感,或会给游戏带来不好影响如游戏平衡性”而不愿购买;高于后者,消费者会认为价钱太高而不能接受
一般来说,“太便宜”和“太贵”的交点作为最优价格点,因为在此处觉得“不过于便宜也不过于昂贵”的消费者最多
但是也有人认为“便宜”和“贵”的交点是最优价格,因为该交点取得了“划算,肯定会买”及“贵,但能接受”的平衡点,是能让最多消费者满意的价格

PSM模型的缺陷
- 只考虑到了消费者的接受率,忽视了消费者的购买能力,即只追求最大的目标人群数。但事实上,即使消费者觉得价格合理,受限于购买力等因素,也无法购买。
- 研究中消费者可能出于各种因素(比如让价格更低能让自己收益,出于面子问题而抬高自己能接受的价格等)有意或无意地抬高或压低其接受的价格。由于消费者知道虚拟世界中的产品(道具或服务)没有成本,其压低价格的可能性较高。
- 没有考虑价格变化导致的购买意愿(销量)变化。
解决
- 为了避免购买力的影响, 问卷或访谈研究中要强调“定这个价格,以自己目前的情况是否会购买”,而非仅仅去客观判断该产品值多少钱。
- 为了解决玩家抬高或压低价格的问题,可以增大样本量,预期随机误差可以相互抵消。
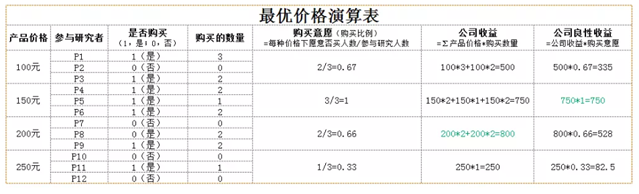
- 仅仅从曲线获得最优价格,受到玩家压低或抬高价格的影响较大。由于该误差可能是系统误差,对此,可以用所获得的价格区间设计不同的价格方案,然后设计组间实验设计,每个参与研究的消费者只接触其中一种或几种价格方案,并对该价格方案下是否购买及购买数量做出决策,通过计算那种价格方案下玩家消费金钱量最高来分析出最佳价格方案。如下表。
- 通过前一条中提到的组间实验设计,可以计算出不同价格下玩家购买意愿的变化,从而得知价格调整会对整体收益带来的影响。此外,价格接受比例还可以作为消费者对某价格满意度的指标,用于计算某价格下企业该产品的良性收益。
注意,我们的上述对策部分基于统计学和实验心理学理论,部分基于我们工作中的实践,欢迎大家讨论和优化。
真实案例:用KANO模型和PSM价格敏感度确定产品功能和定价
今天和大家分享的是关于产品功能上线和合理定价的问题。
记得一个产品姐姐在分享的时候说过一句话受益匪浅“一个产品从出生到长大,要先保证能用,再保证好用。”是的,在产品功能选择上,什么功能是保证用户能用的,什么功能是为了让用户好用的,每类功能会带给用户什么样的体验。这个问题一直也是我们在做产品过程中不断整理和思考的,用户说什么就做什么,功能丰富且齐全,但最终还是做死了的例子不胜枚举。那么一个新的功能到底上不上,这个功能/服务如果收费,价格应该是怎样的。今天就来给大家分享一下关于我之前项目遇到的这些问题和我们的解决办法。
功能到底要不要上——KANO模型
KANO模型_:东京理工大学教授狩野纪昭(Noriaki Kano)发明的对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。
根据不同类型的质量特性与顾客满意度之间的关系,狩野教授将产品服务的质量特性分为五类:
基本(必备)型质量——Must-be Quality/ Basic Quality
期望(意愿)型质量——One-dimensional Quality/ Performance Quality
兴奋(魅力)型质量—Attractive Quality/ Excitement Quality
无差异型质量——Indifferent Quality/Neutral Quality
反向(逆向)型质量——Reverse Quality,亦可以将 ‘Quality’ 翻译成“质量”或“品质”。
前三种需求根据绩效指标分类就是基本因素、绩效因素和激励因素。
简单说就是N个功能摆在这里,我们如何判定该功能符合基本型需求、期望型需求还是兴奋型需求?
KANO模型就可以帮助我们解决这个问题,但是这里有必要说一下,评定一个需求的优先级绝对不是仅仅根据这个就直接判定的
直接分享我之前的项目:
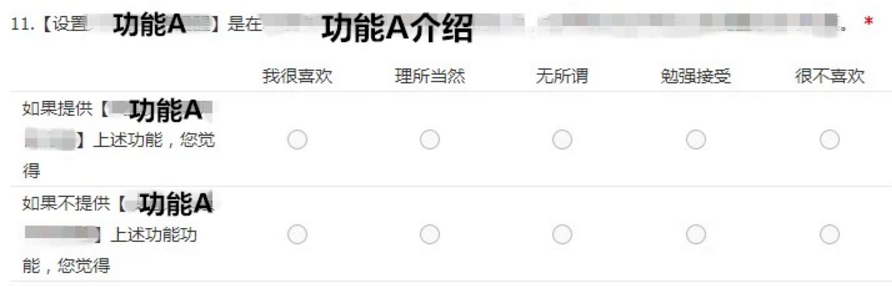
项目背景:因为临近一个关键节日,我司产品希望能增加功能A、功能B、功能C、功能D、功能E,那么如何判定哪一些功能是可以排在前面,哪些可以稍微排后?我们设置了调研问卷来让用户对这5个功能进行评价。具体问卷形式如下图。
(为保护我司隐私,对具体内容进行隐藏。啊哈哈,我价值观很正的!)
这样一份问卷收到之后呢,你将会得到这样一个格式的数据。数据已经过处理。
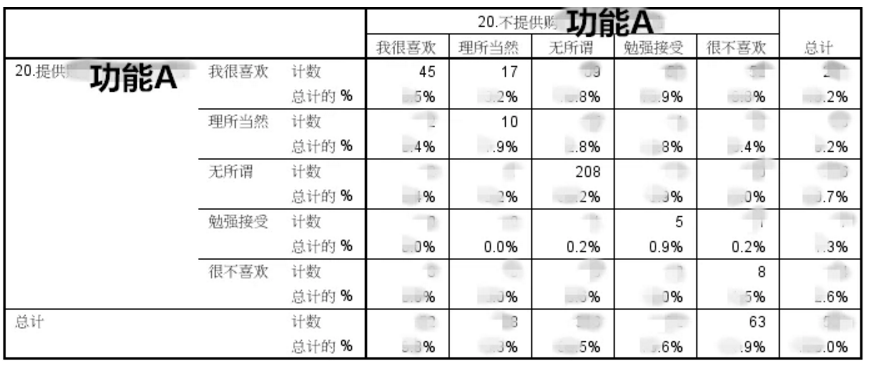
这是一份“如果提供功能A五选项的选择人数如果不提供功能A五选项的选择人数的交叉表。分别是交叉选择人数和人数在该选项总人数的占比。
这个图表怎么用嘞。这下我就必须要找一个解释图上来了。请见下图:
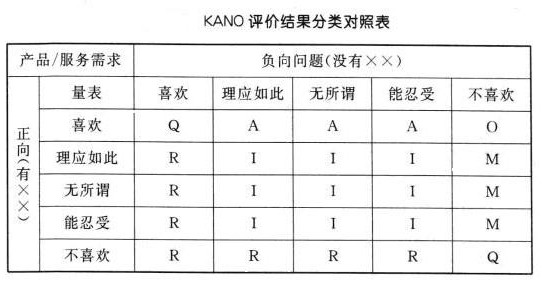
大家看到了这里面AQIRMO之类的标记了,后续的所有指数都是这些类别的求和。
比如:
- 所有分布在Q的格子里的值相加,就是Q的总体系数。
- 所有R的格子里的值相加,就是R的总体系数。
- 和我上面一张数据图一一对应。解释的够清楚了昂~
下面解释一下这些神奇AQIRMO都是什么意思:
A–魅力属性
O–期望属性(一维属性)
M–必备属性
I –无差异属性(次要属性)
R –反向属性
Q–可疑结果
得分最高的属性就是这个功能的最后属性归属。
最后,增加了这个功能或者没有这个功能又会对用户满意度造成什么影响呢?
这就是better-worse系数
增加后的满意系数(better):(魅力属性+期望属性)/(魅力属性+期望属性+必备属性+无差异因素)
• 消除后的不满意系数(worse):(期望属性+必备属性)/(魅力属性+期望属性+必备属性+无差异因素×(-1)
• 注:系数越接近于1或-1,说明对提供后产生满意或不提供后产生不满的影响越大
• 就酱紫,我们得到了这样的一些系数。就可以画一个逼格比较高的象限图啦。横坐标worse系数,纵坐标better系数。把四类属性分布于各个象限中。这个是用SPSS做的散点图。
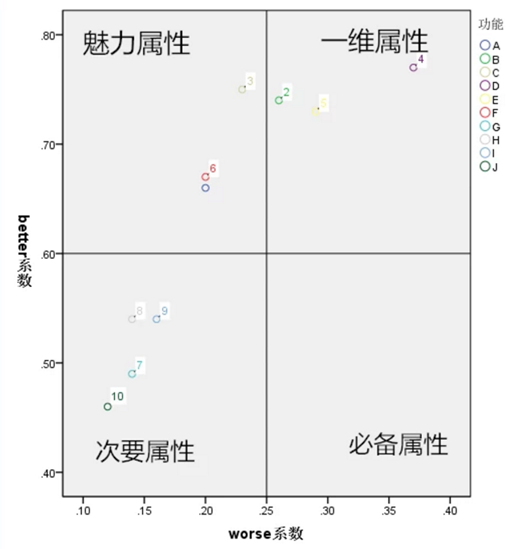
• 综上所述,我们就确认了功能ABCDE的各个属性归类和优先级啦~昂。功能的优先级确定就酱紫结束了。
确定了功能/服务,该如何为其定价
不是每个功能的出现都是为了实现用户更好的操作而存在的,比如购物车、收藏夹之类的功能。还有一些功能的存在是为了能够赚钱的!是不是很直接!是不是说到了很多人的心里去!比如说卖东西寄快递,卖家愿意给你送货上门,为你提供这个功能虽然是为了用户体验更好,说到底还是起码不赚钱但不亏本的。那么快递费定价多少合适?(我就是举个例子,不要告诉我快递费多少钱是快递公司说的算)就我司这次项目中,有一些功能是需要付一些费用的,那么要付多少钱能够保本,多少钱可以盈利,多少钱用户就觉得你有病了呢?比起拍脑袋猜,或者设置不同价格用市场来验证,我更建议在最开始的时候能确定一个价格范围值。那么用户接受的价格到底在哪个区间呢?
这里就给大家隆重介绍——PSM价格敏感度测试
简单说PSM就是帮助你能够获取到一个功能或者服务的用户可接受价格区间,并确定最佳价格。为了保护我司的数据。我来举个朋友卖水果的定价案例。一盒现切的水果拼盘,定价在多少最合适呢?市场容忍度是多少呢?首先,我们做了用户调研。问卷结构见下图。
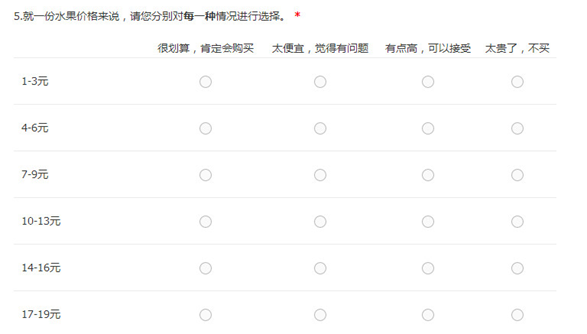
这里就是问卷的结构啦。用户对每一档价格进行4个选项的评价,价格从最低到最高,最好极值设置的高一点点避免天花板和地板效应。区间取得尽量细一点,这样后面得到的结果会比较精准。
回收到问卷之后,我们将会得到这样一份数据,再来一波图。

我们得到了各类价格区间的“
比较便宜、太便宜、有点贵可以忍、太贵了放弃”的频率值。
然后每个选项都计算累计总和,比如:比较便宜右边,是从下往上的累计总和。为什么是从下至上求和呢?
因为,如果觉得8-10块都是比较便宜的话,5-1块钱当然都会觉得便宜啊。
同理,如果觉得1-2块钱都贵的话,3-10块肯定都是觉得贵啊。
这里就是需要注意的点啦!很便宜和太便宜都是从下往上求和的,而有点贵和太贵了都是从上往下求和的。
求好了和值。计算当前这一行的和值的累计百分比(本行累计和值/累计总和)就阔以啦。举例:比较便宜列,累计和值=6,百分比=6/20;累计和值=13,百分比=13/20.以此类推。酱紫是不是就有4列百分比了?然后肿么做呢?——画图!
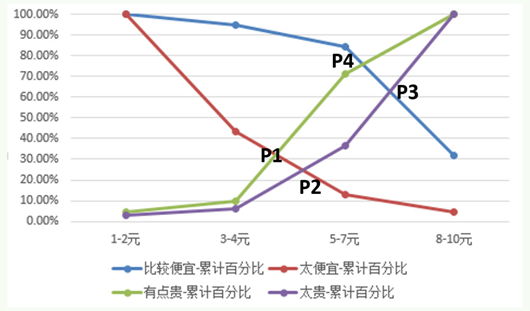
数据是我为了演示随便填的,图画的有点丑。好好统计出来的数据应该画的比较好看。
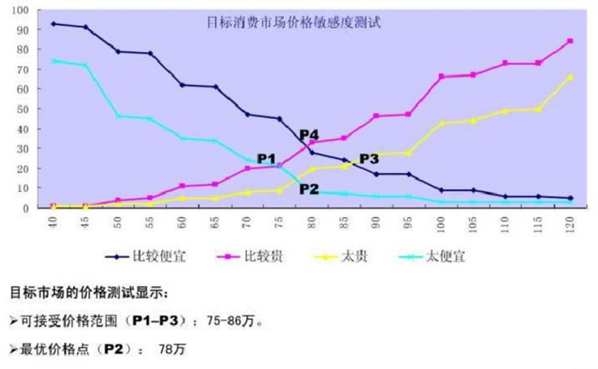
P1–比较贵太便宜曲线交叉点
P2–太贵太便宜曲线交叉点
P3–比较便宜太贵交叉点
P4–比较便宜比较贵交叉点
可接受价格范围:
P1–P3两点之间的价格都是用户可接受价格
低于P1——用户会认为太便宜而怀疑质量问题,高于P3——用户会觉得太贵而放弃
可接受价格点:P4——在此点,用户觉得价位太高的比例和价位太低的比例相等
最优价格点:P2——在此点,用户觉得价格既不会太贵也不会太便宜
就是这样的计算之后,我们将会得到最优价格。并且在这样一个合理的价格范围里去不断调试。这相对于直接拍脑袋来说,真的是靠谱多了呢~
参考资料:
- 东京理工大学教授狩野纪昭(Noriaki Kano)和Fumio Takahashi《质量的保健因素和激励因素》(Motivator and Hygiene Factor in Quality)
- 周达,梁英瑜,贺成功.基于KANO模型的顾客需求分析——以校园咖啡吧商品及服务项目筛选为例
- PSM价格敏感度测试——2006.7.20 (百度文库)
添加标签
价格敏感度模型Price Sensitivity Meter
有时在实际业务中,会把用户分为3-5类,
比如分为极度敏感、较敏感、一般敏感、较不敏感、极度不敏感。
然后将每类的聚类中心值与实际业务所需的其他指标结合,最终确定人群类别,判断在不同需求下是否触达或怎样触达。

价格敏感度规则:inType=HBase##zkHosts=192.168.10.20##zkPort=2181##hbaseTable=tbl_orders##family=detail##selectFields=memberId,orderSn,orderAmount,couponCodeValue
业务代码
价格敏感度模型
psm=
优惠订单占比 + 平均优惠金额占比 + 优惠总金额占比
优惠订单占比=优惠的总次数/订单总次数
平均优惠金额占比=优惠金额平均数/平均每单应收金额
------ 优惠金额平均数= 优惠总金额/优惠的总次数
------平均每单应收金额= 订单应收总金额/订单总次数
优惠总金额占比=优惠总金额/订单应收总金额
由上面可以得出:
------优惠的总次数
------优惠总金额
------订单总次数
------订单应收总金额
package cn.itcast.userprofile.up24.newexcavate
import cn.itcast.userprofile.up24.public.PublicStaticCode
import org.apache.spark.ml.clustering.KMeans
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.immutable
/**
* Author 真情流露哦呦
* Desc 价格敏感度模型Price Sensitivity Meter
* 有时在实际业务中,会把用户分为3-5类,
* 比如分为极度敏感、较敏感、一般敏感、较不敏感、极度不敏感。
* 然后将每类的聚类中心值与实际业务所需的其他指标结合,最终确定人群类别,判断在不同需求下是否触达或怎样触达。
* 比如电商要通过满减优惠推广一新品牌的麦片,
* 此时可优先选择优惠敏感且对麦片有消费偏好的用户进行精准推送,
* 至于优惠敏感但日常对麦片无偏好的用户可暂时不进行推送或减小推送力度,
* 优惠不敏感且对麦片无偏好的用户可选择不进行推送。
* 可见,在实际操作中,技术指标评价外,还应结合业务需要,才能使模型达到理想效果。
* //价格敏感度模型
* psm=优惠订单占比+平均优惠金额占比+优惠总金额占比
* 优惠订单占比 ---> (优惠的次数/购买次数)
*
* 平均优惠金额占比 ---> (优惠金额平均数/平均每单应收金额)
* 优惠金额平均数= 优惠总金额/优惠的次数
* 平均每单应收金额= 订单应收总金额/购买次数
* 优惠总金额占比 ---> ( 优惠总金额/订单的应收总金额)
*目的:
* 优惠的次数
* 购买次数
*优惠总金额
*订单的应收金额
*/
object PSM extends PublicStaticCode{
override def SetAppName: String = "PSM"
override def Four_Name: String = "价格敏感度"
/**
* 开始计算
*inType=HBase##zkHosts=192.168.10.20##zkPort=2181##
* hbaseTable=tbl_orders##family=detail##selectFields=memberId,orderSn,orderAmount,couponCodeValue
* @param five MySQL中的5级规则 id,rule
* @param tblUser 根据selectFields查询出来的HBase中的数据
* @return userid,tagIds
*/
override def compilerAdapterFactory(spark: SparkSession, five: DataFrame, tblUser: DataFrame): DataFrame = {
import spark.implicits._
import scala.collection.JavaConversions._
import org.apache.spark.sql.functions._
// five.show()
/**
* +------+----+
* |tagsId|rule|
* +------+----+
* | 51| 1|
* | 52| 2|
* | 53| 3|
* | 54| 4|
* | 55| 5|
* +------+----+
*/
// tblUser.show()
/**
* orderSn 订单号
* orderAmount 订单总金额,等于商品总金额+运费
* couponCodeValue 优惠码优惠金额
* +---------+-------------------+-----------+---------------+
* | memberId| orderSn|orderAmount|couponCodeValue|
* +---------+-------------------+-----------+---------------+
* | 13823431| ts_792756751164275| 2479.45| 0.00|
* | 4035167| D14090106121770839| 2449.00| 0.00|
* | 4035291| D14090112394810659| 1099.42| 0.00|
* | 4035041| fx_787749561729045| 1999.00| 0.00|
* | 13823285| D14092120154435903| 2488.00| 0.00|
* | 4034219| D14092120155620305| 3449.00| 0.00|
* |138230939|top_810791455519102| 1649.00| 0.00|
* | 4035083| D14092120161884409| 7.00| 0.00|
*/
//0.定义常量
val psmScoreStr: String = "psmScore"
val featureStr: String = "feature"
val predictStr: String = "predict"
//1.先将用户每个订单是否优惠了进行处理
/**
* state 优惠订单为1, 非优惠订单为0
* 在订单没有优惠的时候,金额为0.00
*/
var state=when(col("couponCodeValue").cast("Int")===0.00,0)
.when(col("couponCodeValue").cast("Int")=!=0.00,1) as "state"
/**
* practicalAmount:订单应收总金额
*
*/
var practicalAmount='orderAmount+'couponCodeValue as "pa"
val order_State: DataFrame = tblUser.select('memberId, practicalAmount, 'orderAmount,'couponCodeValue, state)
// order_State.show()
/**
* memberId 用户Id
* pa 订单应收总金额
* orderAmount 订单总金额
* couponCodeValue 优惠码优惠金额
* state 订单是否优惠
* +---------+-------+-----------+---------------+-----+
* | memberId| pa|orderAmount|couponCodeValue|state|
* +---------+-------+-----------+---------------+-----+
* | 13823431|2479.45| 2479.45| 0.00| 0|
* | 4035167| 2449.0| 2449.00| 0.00| 0|
* | 4035291|1099.42| 1099.42| 0.00| 0|
* | 4035041| 1999.0| 1999.00| 0.00| 0|
* | 13823285| 2488.0| 2488.00| 0.00| 0|
* | 4034219| 3449.0| 3449.00| 0.00| 0|
* |138230939| 1649.0| 1649.00| 0.00| 0|
*/
/**
*优惠的次数
*购买次数
*优惠总金额
*订单的应收金额
* Discount:优惠次数
* PurchaseCount:购买次数
* TotalAmount:优惠总金额
* TotalReceivable订单的应收总金额
*/
var disCount=sum('state) as "disCount"
var purchaseCount=count('state) as "purchaseCount"
var totalAmount=sum('couponCodeValue) as "totalAmount"
var totalReceivable=sum('pa) as "totalReceivable"
val psm_Score = order_State.groupBy('memberId).agg(disCount, purchaseCount, totalAmount, totalReceivable)
// psm_Score.show()
/**
* disCount:优惠次数
* purchaseCount:购买次数
* totalAmount:优惠总金额
* totalReceivable:订单的应收总金额
* +---------+--------+-------------+-----------+------------------+
* | memberId|disCount|purchaseCount|totalAmount| totalReceivable|
* +---------+--------+-------------+-----------+------------------+
* | 4033473| 3| 142| 500.0| 252430.92|
* | 13822725| 4| 116| 800.0| 180098.34|
* | 13823681| 1| 108| 200.0| 169946.1|
* |138230919| 3| 125| 600.0|240661.56999999998|
* | 13823083| 3| 132| 600.0| 234124.17|
*/
/**
* psm=优惠订单占比+平均优惠金额占比+优惠总金额占比
* 优惠订单占比 ---> (优惠的次数/购买次数)
*
* 平均优惠金额占比 ---> (优惠金额平均数/平均每单应收金额)
* 优惠金额平均数= 优惠总金额/优惠的次数
* 平均每单应收金额= 订单应收总金额/购买次数
* 优惠总金额占比 ---> ( 优惠总金额/订单的应收总金额)
*/
//优惠订单占比
var DiscountProportion='disCount / 'purchaseCount
//平均优惠金额占比
var DiscountAverageProportion=('totalAmount/'disCount)/('totalReceivable/'purchaseCount)
//优惠总金额占比
var TotalDiscountProportion='totalAmount/'totalReceivable
//psm=优惠订单占比+平均优惠金额占比+优惠总金额占比
var psm=DiscountProportion+DiscountAverageProportion+TotalDiscountProportion as "psmScore"
/**
* +--------+--------+-------------+-----------+---------------+
* |memberId|disCount|purchaseCount|totalAmount|totalReceivable|
* +--------+--------+-------------+-----------+---------------+
* |13822841| 0| 113| 0.0| 205931.91|
* +--------+--------+-------------+-----------+---------------+
* 优惠订单占比 ---> (优惠的次数/购买次数)
* disCount:优惠次数
* purchaseCount:购买次数
* purchaseCount/ disCount
* 113 / 0 (除数不能为0)
* 所以要进行判断 where('psmScore.isNotNull)
*/
val psm_Result = psm_Score.select('memberId, psm).where('psmScore.isNotNull)
// psm_Result.show()
/**
* +---------+-------------------+
* | memberId| psmScore|
* +---------+-------------------+
* | 4033473|0.11686252330855691|
* | 13822725|0.16774328728519597|
* | 13823681|0.13753522440350205|
* |138230919| 0.1303734438365045|
* | 13823083| 0.1380506927739941|
* | 13823431|0.15321482374431458|
* | 4034923|0.13927276336831218|
* | 4033575|0.11392752155030905|
*/
//3.聚类
//为方便后续模型进行特征输入,需要部分列的数据转换为特征向量,并统一命名,VectorAssembler类就可以完成这一任务。
//VectorAssembler是一个transformer,将多列数据转化为单列的向量列
val vectorDF = new VectorAssembler()
.setInputCols(Array("psmScore"))
.setOutputCol(featureStr)
.transform(psm_Result)
// vectorDF.show()
/**
* +---------+-------------------+--------------------+
* | memberId| psmScore| feature|
* +---------+-------------------+--------------------+
* | 4033473|0.11686252330855691|[0.11686252330855...|
* | 13822725|0.16774328728519597|[0.16774328728519...|
* | 13823681|0.13753522440350205|[0.13753522440350...|
* |138230919| 0.1303734438365045|[0.1303734438365045]|
* | 13823083| 0.1380506927739941|[0.1380506927739941]|
* | 13823431|0.15321482374431458|[0.15321482374431...|
* | 4034923|0.13927276336831218|[0.13927276336831...|
* | 4033575|0.11392752155030905|[0.11392752155030...|
*/
val ks: List[Int] = List(2,3,4,5,6,7,8)
//集合内误差平方和:Within Set Sum of Squared Error, WSSSE
//对于那些无法预先知道K值的情况,可以通过WSSSE的计算构建出 K-WSSSE 间的相关关系,从而确定K的值,
//一般来说,最优的K值即是 K-WSSSE 曲线拐点Elbow的位置
//当然,对于某些情况来说,我们还需要考虑K值的语义可解释性,而不仅仅是教条地参考WSSSE曲线
/*val WSSSEMap: mutable.Map[Int, Double] = mutable.Map[Int,Double]()
for(k<- ks){
val kMeans: KMeans = new KMeans()
.setK(k)
.setMaxIter(20)//最大迭代次数
.setFeaturesCol(featureStr) //特征列
.setPredictionCol(predictStr)//预测结果列
val model: KMeansModel = kMeans.fit(vectorDF)
val WSSSE: Double = model.computeCost(vectorDF)
WSSSEMap.put(k,WSSSE)
}
println("训练出来的K对应的WSSSE如下:")
println(WSSSEMap)
//训练出来的K对应的WSSSE如下:
//Map(8 -> 0.1514833272915443, 2 -> 1.2676013396202386, 5 -> 0.3205627518783058, 4 -> 0.4336353113133625, 7 -> 0.16381158476261476, 3 -> 0.8254005284535515, 6 -> 0.20131609978279763)
val mined: (Int, Double) = WSSSEMap.minBy(_._2)
val minK: Int = mined._1
println("训练出来的WSSSE值最小的K是:"+minK)
//一般来说,同样的迭代次数和算法跑的次数,这个值越小代表聚类的效果越好。
//但是在实际情况下,我们还要考虑到聚类结果的可解释性,不能一味的选择使 computeCost 结果值最小的那个 K
*/
//4.训练模型
val model = new KMeans()
.setK(5)
.setSeed(10)
.setMaxIter(30)
.setFeaturesCol(featureStr)
.setPredictionCol(predictStr)
.fit(vectorDF)
//5.预测
val result: DataFrame = model.transform(vectorDF)
// result.show()
/**
* +---------+-------------------+--------------------+-------+
* | memberId| psmScore| feature|predict|
* +---------+-------------------+--------------------+-------+
* | 4033473|0.11686252330855691|[0.11686252330855...| 0|
* | 13822725|0.16774328728519597|[0.16774328728519...| 0|
* | 13823681|0.13753522440350205|[0.13753522440350...| 0|
* |138230919| 0.1303734438365045|[0.1303734438365045]| 0|
* | 13823083| 0.1380506927739941|[0.1380506927739941]| 0|
* | 13823431|0.15321482374431458|[0.15321482374431...| 0|
* | 4034923|0.13927276336831218|[0.13927276336831...| 0|
* | 4033575|0.11392752155030905|[0.11392752155030...| 0|
* | 13823153|0.15547466292943982|[0.15547466292943...| 0|
* | 4034191|0.11026694172505715|[0.11026694172505...| 0|
* | 4033483|0.15976480445774954|[0.15976480445774...| 0|
* | 4033348|0.13600092999496663|[0.13600092999496...| 0|
* | 4034761|0.13114429909634118|[0.13114429909634...| 0|
* | 4035131|0.39147259141650464|[0.39147259141650...| 2|
* | 13823077|0.12969603277907024|[0.12969603277907...| 0|
* |138230937|0.15212864394723766|[0.15212864394723...| 0|
* | 4034641|0.14954686999636585|[0.14954686999636...| 0|
* | 7|0.13128367494800738|[0.13128367494800...| 0|
* |138230911|0.11824736419948352|[0.11824736419948...| 0|
* | 4035219|0.08062873693483025|[0.08062873693483...| 3|
* +---------+-------------------+--------------------+-------+
*/
//问题: 每一个簇的ID是无序的,但是我们将分类簇和rule进行对应的时候,需要有序
//6.按质心排序,质心大,该类用户价值大
//[(质心id, 质心值)]
val center = for (i <- model.clusterCenters.indices) yield (i, model.clusterCenters(i).toArray.sum)
val centerSortBy: immutable.IndexedSeq[(Int, Double)] = center.sortBy(_._2).reverse
// centerSortBy.foreach(println)
/**
* (1,0.5563226557645843)
* (2,0.31754213552513205)
* (4,0.21281283437093323)
* (0,0.1320103555777084)
* (3,0.08401071578741981)
*/
//[(质心id, rule值)]
val centerAndRule = for (i <- centerSortBy.indices) yield (centerSortBy(i)._1, i + 1)
val centerDF = centerAndRule.toDF(predictStr, "rule")
// centerDF.show()
/**
* +-------+----+
* |predict|rule|
* +-------+----+
* | 1| 1|
* | 2| 2|
* | 4| 3|
* | 0| 4|
* | 3| 5|
* +-------+----+
*/
//7.将rule和5级规则进行匹配
val ruleTagDf = centerDF.join(five, "rule").select(predictStr, "tagsId")
// ruleTagDf.show()
/**
* +---------+-------------------+--------------------+-------+
* | memberId| psmScore| feature|predict|
* +---------+-------------------+--------------------+-------+
* | 4033473|0.11686252330855691|[0.11686252330855...| 0|
* | 13822725|0.16774328728519597|[0.16774328728519...| 0|
* | 13823681|0.13753522440350205|[0.13753522440350...| 0|
*/
/**
* +-------+------+
* |predict|tagsId|
* +-------+------+
* | 1| 51|
* | 2| 52|
*/
// val new_Tag = ruleTagDf.join(result, ruleTagDf.col("predict")===result.col("predict"))
// new_Tag.show()
val ruleMap = ruleTagDf.map(t => {
val predict = t.getAs("predict").toString
val tagsId = t.getAs("tagsId").toString
(predict, tagsId)
}).collect().toMap
println(ruleMap)
var rule_UDF=udf((pre:String)=>{
val tag = ruleMap(pre)
tag
})
val new_Tag = result.select('memberId as "userId", rule_UDF('predict).as("tagsId"))
/**
* +---------+------------+
* | memberId|UDF(predict)|
* +---------+------------+
* | 4033473| 54|
* | 13822725| 54|
* | 13823681| 54|
* |138230919| 54|
* | 13823083| 54|
* | 13823431| 54|
* | 4034923| 54|
* | 4033575| 54|
* | 13823153| 54|
* | 4034191| 54|
* | 4033483| 54|
* | 4033348| 54|
* | 4034761| 54|
* | 4035131| 52|
* | 13823077| 54|
* |138230937| 54|
* | 4034641| 54|
* | 7| 54|
* |138230911| 54|
* | 4035219| 55|
* +---------+------------+
*/
new_Tag
}
def main(args: Array[String]): Unit = {
startMain()
}
}
使用K-Means算法进行挖掘的标签:
企业级用户画像: 用户活跃度模型-RFE
企业级用户画像:开发RFM模型实例
以上就是价格敏感度模型-PSM
若有错误及时私信我,立马修改
如能帮助到你或对大数据有兴趣的可以关注一下,希望能点个赞支持一下谢谢!

最后
以上就是成就大象最近收集整理的关于企业级用户画像: 价格敏感度模型-PSMPSM模型引入PSM模型在网游中的运用PSM模型实施具体步骤PSM模型的缺陷真实案例:用KANO模型和PSM价格敏感度确定产品功能和定价确定了功能/服务,该如何为其定价参考资料:添加标签业务代码的全部内容,更多相关企业级用户画像:内容请搜索靠谱客的其他文章。








发表评论 取消回复