先谈谈超前进位加法器设计的初衷。
我们从数电书学到的最基本的加法器的结构是下图这样的:
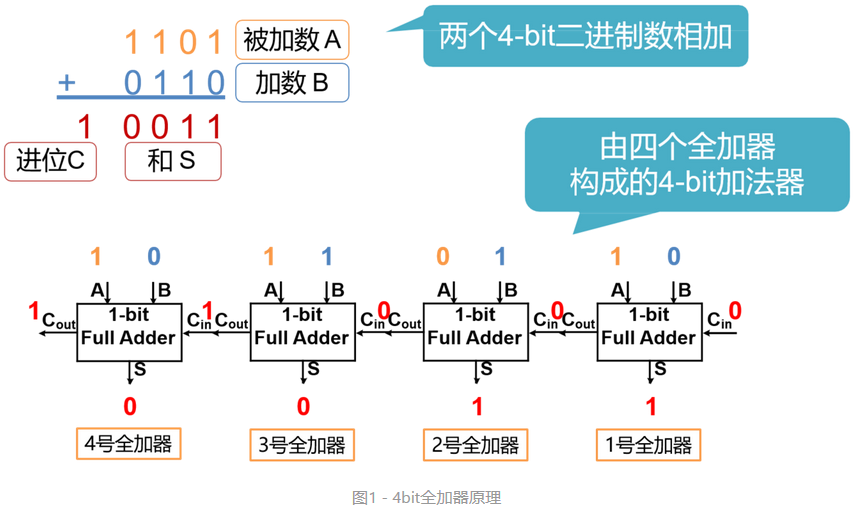 从图中很好理解加法器的组成。
从图中很好理解加法器的组成。
一位的加法器直接卡诺图既可以画出来。
但是这样的结构有什么缺点?最直接的就是第4号全加器要输出计算结果至少要等到第3号全加器把进位信息传过来。那如果级数很高会出现组合逻辑延时过长的情况。
下面这篇文章很详细的分析了门级延时的情况。
https://www.jianshu.com
其实问题的关键在于如何解决这个等待进位信息的问题。我们可以想可不可以不等后级把进位算完再传过来,我们直接通过输入的数据把这个进位直接算出来发给每一级不就好了。
我们看看怎么实现这样的想法.
简单的1级加法器的进位信号计算的方式如下所示:
 那4级的加法器进位信息可以这样表示:
那4级的加法器进位信息可以这样表示:
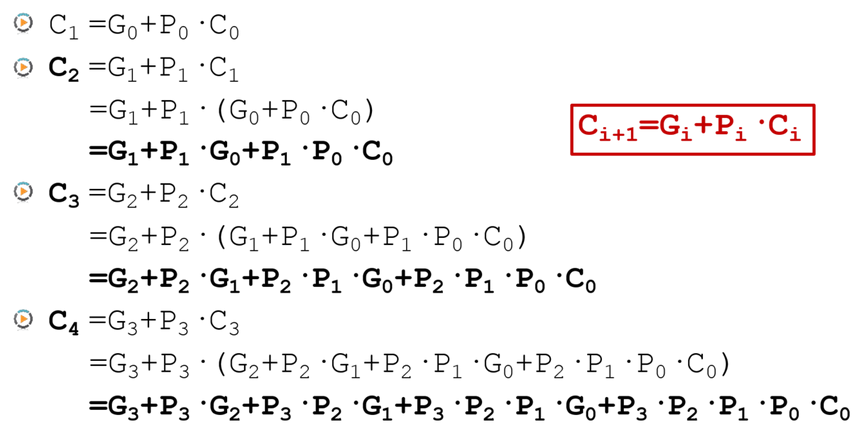
//一位加法器
module Add1
(
input a,
input b,
input C_in,
output f,
output g,
output p
);
assign f=a^b^C_in;
assign g=a&b;
assign p=a|b;
endmodule
//4位CLA部件
module CLA_4(
input [3:0]P,
input [3:0]G,
input C_in,
output [4:1]Ci,
output Gm,
output Pm
);
assign Ci[1]=G[0]|P[0]&C_in;
assign Ci[2]=G[1]|P[1]&G[0]|P[1]&P[0]&C_in;
assign Ci[3]=G[2]|P[2]&G[1]|P[2]&P[1]&G[0]|P[2]&P[1]&P[0]&C_in;
assign Ci[4]=G[3]|P[3]&G[2]|P[3]&P[2]&G[1]|P[3]&P[2]&P[1]&G[0]|P[3]&P[2]&P[1]&P[0]&C_in;
assign Gm=G[3]|P[3]&G[2]|P[3]&P[2]&G[1]|P[3]&P[2]&P[1]&G[0];
assign Pm=P[3]&P[2]&P[1]&P[0];
endmodule
上面是根据公式写出来的1位加法器和进位计算模块。
但是貌似与传统的加法器不太一样,这里的P和G就是传播信号和生成信号。

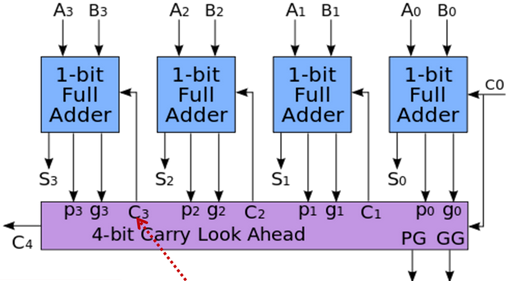
总体的的4位超前进位加法器如下图所示:
//四位超前进位加法器
module Add4_head
(
input [3:0]A,
input [3:0]B,
input C_in,
output [3:0]F,
output Gm,
output Pm,
output C_out
);
wire [3:0] G;
wire [3:0] P;
wire [4:1] C;
Add1 u1
( .a(A[0]),
.b(B[0]),
.C_in(C_in),
.f(F[0]),
.g(G[0]),
.p(P[0])
);
Add1 u2
( .a(A[1]),
.b(B[1]),
.C_in(C[1]),
.f(F[1]),
.g(G[1]),
.p(P[1])
);
Add1 u3
( .a(A[2]),
.b(B[2]),
.C_in(C[2]),
.f(F[2]),
.g(G[2]),
.p(P[2])
);
Add1 u4
( .a(A[3]),
.b(B[3]),
.C_in(C[3]),
.f(F[3]),
.g(G[3]),
.p(P[3])
);
CLA_4 uut
(
.P(P),
.G(G),
.C_in(C_in),
.Ci(C),
.Gm(Gm),
.Pm(Pm)
);
assign C_out=C[4];
endmodule
新的问题来了,4位的好解决,但是16位的,这样直接算进位太复杂了。有没有什么好的办法。
注意到我们这里的4位的加法器把Pm,Gm也引出来了。我们可不可以仿照类似4位的加法器,把1个4位的加法器当成之前的1位加法器,同样是将Pm,Gm这两个用CLA计算进位信息即可。

//16位
module Add16_head
(
input [15:0]A,
input [15:0]B,
input C_in,
output [15:0] F,
output Gm,
output Pm,
output C_out
);
wire [3:0]G;
wire [3:0]P;
wire [4:1]C;
Add4_head A0
(
.A(A[3:0]),
.B(B[3:0]),
.C_in(C_in),
.F(F[3:0]),
.Gm(G[0]),
.Pm(P[0])
);
Add4_head A1
(
.A(A[7:4]),
.B(B[7:4]),
.C_in(C[1]),
.F(F[7:4]),
.Gm(G[1]),
.Pm(P[1])
);
Add4_head A3
(
.A(A[11:8]),
.B(B[11:8]),
.C_in(C[2]),
.F(F[11:8]),
.Gm(G[2]),
.Pm(P[2])
);
Add4_head A4
(
.A(A[15:12]),
.B(B[15:12]),
.C_in(C[3]),
.F(F[15:12]),
.Gm(G[3]),
.Pm(P[3])
);
CLA_4 AAt
(
.P(P),
.G(G),
.C_in(C_in),
.Ci(C),
.Gm(Gm),
.Pm(Pm)
);
assign C_out=C[4];
endmodule
 所以还是原来的套路。
所以还是原来的套路。
对于一些比较奇葩的位数,我们可以通过级联4位和16位的加法器组合起来用,
比如24位的可以这样做:
//24位加法
module Add24_head
(
input [23:0]A,
input [23:0]B,
input C_in,
output [23:0]Result,
output C_out
);
wire [3:0]G;wire [3:0]P;
wire [2:1]C;
Add16_head add16_11
(
.A(A[15:0]),
.B(B[15:0]),
.C_in(C_in),
.F(Result[15:0]),
.C_out(C[1])
);
Add4_head add4_11
(
.A(A[19:16]),
.B(B[19:16]),
.C_in(C[1]),
.F(Result[19:16]),
.C_out(C[2])
);
Add4_head add4_12
(
.A(A[23:20]),
.B(B[23:20]),
.C_in(C[2]),
.F(Result[23:20]),
.C_out(C_out)
);
endmodule
对于32位的除了级联两个16位的,更优化的是可以参照计算两位加法器的进位运算
//32位加法
module Add32_head
(
input [31:0]A,
input [31:0]B,
input C_in,
output [31:0]Result,
output C_out
);
wire [3:0]G;wire [3:0]P;
assign G[3:2]=2'b00;
assign P[3:2]=2'b00;
Add16_head add16_1
(
.A(A[15:0]),
.B(B[15:0]),
.C_in(C_in),
.F(Result[15:0]),
.Gm(G[0]),
.Pm(P[0])
);
wire C_16;
Add16_head add16_2
(
.A(A[31:16]),
.B(B[31:16]),
.C_in(C_16),
.F(Result[31:16]),
.Gm(G[1]),
.Pm(P[1])
);
assign C_16=G[0]|P[0]&C_in;
assign C_out=G[1]|P[1]&G[0]|P[1]&P[0]&C_in;
endmodule
实际上依然运用的思想还是通过预算出进位信息来达到减少延时的功能。
最后
以上就是懦弱墨镜最近收集整理的关于超前进位加法器(较为详细讲解)的全部内容,更多相关超前进位加法器(较为详细讲解)内容请搜索靠谱客的其他文章。








发表评论 取消回复