 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
总帖:CDH 6系列(CDH 6.0、CHD6.1等)安装和使用
- Impala 操作/读写 Kudu,使用druid连接池
- Kudu 原理、API使用、代码
- Kudu Java API 条件查询
- spark读取kudu表导出数据为parquet文件(spark kudu parquet)
- kudu 导入/导出 数据
- Kudu 分页查询的两种方式
- Kudu 创建主键
=============Flume================
=============Kafka================

1.kafka的分区数的默认配置:

2.问题:假如消费不出topic中的数据时。
日志报错:kafka.server.KafkaApis: [KafkaApi-48] Number of alive brokers ‘命令中指定的备份数’
does not meet the required replication factor ‘CDH中kafka配置的备份数’ for the offsets topic
方法:查看命令中指定的备份数 是否小于 CDH中kafka配置的备份数
解决:要么修改 命令中指定的备份数 ,和CDH中kafka配置的备份数 一致 或大于 CDH中kafka配置的备份数
=============Kudu================
KUDU 中存在两个角色
Mater Server:负责集群管理、元数据管理等功能
Tablet Server:负责数据存储,并提供数据读写服务
为了实现分区容错性,跟其他大数据产品一样,对于每个角色,在 KUDU 中都可以设置特定数量(一般是 3 或 5)的副本。
各副本间通过 Raft 协议来保证数据一致性。Raft 协议与 ZAB 类似,都是 Paxos 协议的工程简化版本,具体细节有兴趣的同学可以搜索相关资料学习。
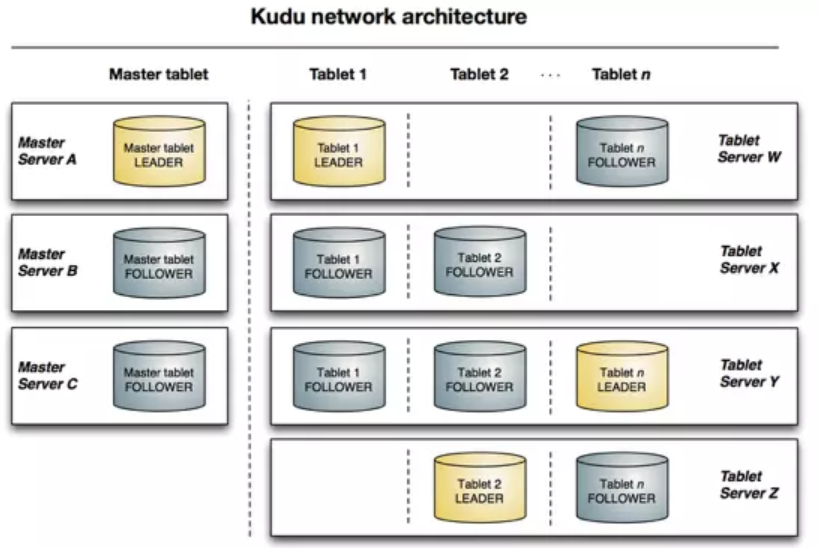
KUDU Client 在与服务端交互时,先从 Master Server 获取元数据信息,然后去 Tablet Server 读写数据,如下图: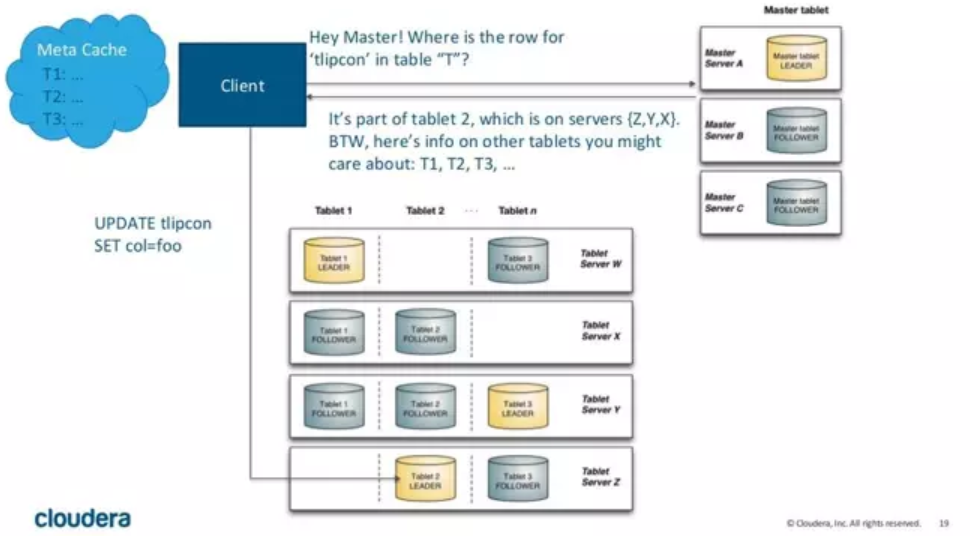
kUDU 架构
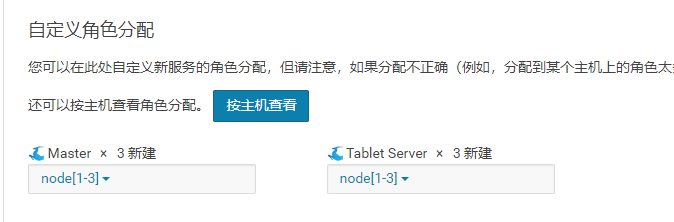
可以每个节点都执行
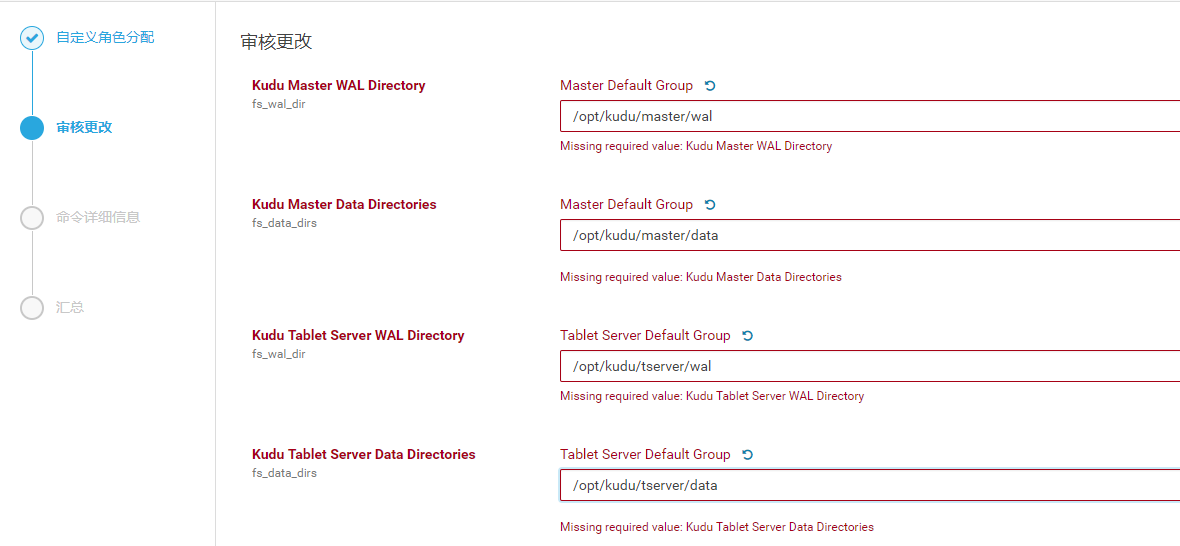
mkdir -p /opt/kudu/master/wal
mkdir -p /opt/kudu/master/data
mkdir -p /opt/kudu/master/logs
mkdir -p /opt/kudu/tserver/wal
mkdir -p /opt/kudu/tserver/data
mkdir -p /opt/kudu/tserver/logs
chown -R kudu:kudu /opt/cloudera
配置 Kudu Tablet Server Hard Memory Limit Kudu 的Tablet Server能使用的最大内存。
Tablet Server在批量写入数据时并非实时写入磁盘,而是先Cache在内存中,在flush到磁盘。
这个值设置过小时,会造成Kudu数据写入性能显著下降。对于写入性能要求比较高的集群,建议设置更大的值,比如32GB。
最后
以上就是活力金针菇最近收集整理的关于CDH 安装 Flume、Kafka、Kudu日萌社总帖:CDH 6系列(CDH 6.0、CHD6.1等)安装和使用的全部内容,更多相关CDH内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复