点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨paopaoslam
来源丨泡泡机器人SLAM
标题:
CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection
作者:Su Pang, Daniel Morris, Hayder Radha
编译:张毅Roy
审核:Lionheart,志勇

摘要

我们在利用神经网络解决3D-LiDAR和2D-Camera物体识别的问题上有非常大的进展。然而利用两个不同的模型达到单个模型那样高效的训练神经网络却非常困难。在本文中,我们提出了一种新颖的Camera-LiDAR(CLOCs)融合网络。CLOCs 融合提供了一个低复杂度的多模态融合框架,显著提高了单模态检测器的性能。CLOCs会利用在非极大值抑制(NMS)之前的产生的3D和2D检测器的输出结果(候选物体),同时会利用其几何和语义的一致性以达到更准确的检测精度。本文的实验数据为KITTI物体识别,包括3D和鸟瞰视角指标,实验结果显示出本文提出的算法相比其他算法有显着的提升,尤其在远距离的数据运用该算法上超过了现有最先进的基于融合的算法。在提交时,CLOCs在官方KITTI 排行榜中所有基于融合的方法中排名最高。我们将发布我们的代码。

相关工作

3D物体检测主要可以分为三类:(1) 2D图片,(2)3D点云,(3)图片与点云。2D图片检测很难给出准确的三维边界。3D点云检测是最近比较流行的研究方向,但是在远距离的物体检测上也有明显短板。基于多模型的融合的3D检测也有很多方向。多模型的融合方法可以大概分为三类:早期融合,深度融合,晚期融合,他们各有各的有优点和缺点。虽然来说早期融合和深度融合有最大的潜力可以利用跨模型态的信息,但是由于数据协调性或者叫对齐性非常的难以调整,需要很复杂的构架来支撑算法。而晚期融合在构架上会比较简单,而且可以容易的构建预训练和单模型检测器。

整体框架

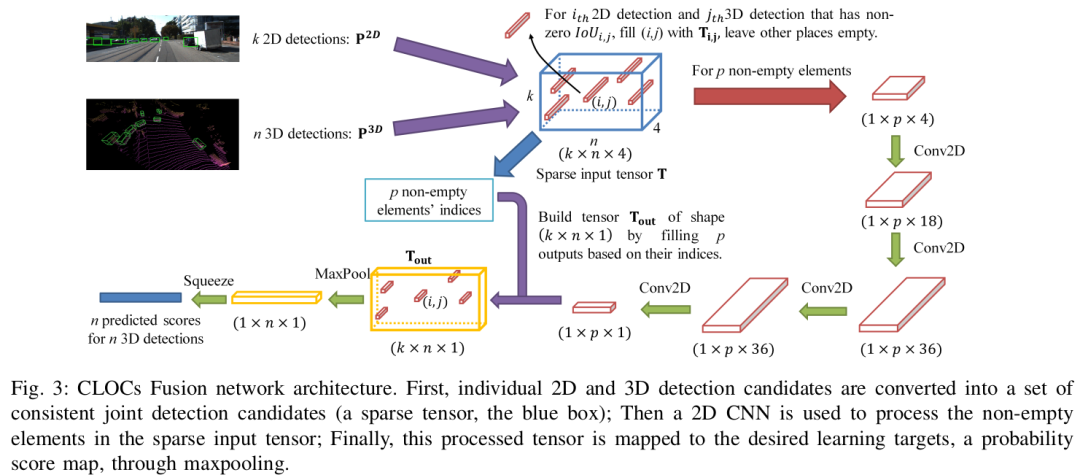
CLOCs 融合网络构架。首先将2D和3D检查后的候选物体转换为联合的检测候选物体集合,然后在疏松的输入tensor里使用2D-CNN处理非0元素。最后,这个被处理的tensor会通过最大池化被映射到期望的学习目标中。

论文关键点介绍

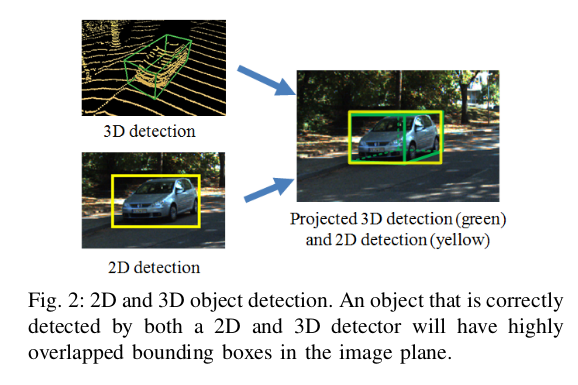
几何和语义一致性
对于给定的一帧图像和激光雷达数据可能在每个模态中存在众多有不同置信度的检测候选物体,从这些候选物体中,我们寻找多个3D检测物体和分数组成集合。融合这些检测候选者需要找到不同模态之间的联系。为此,我们构建了一个关于几何图形关联和应用语义一致性的评分机制,详细描述如下。
几何一致性
被正确检测到的物体对象通过2D和3D检测器将会有一个相似的边界框,见图2。如果在位姿上的有小的误差会减少重叠的部分。这会让一个基于图像的边界框的联合相交(IoU)的投影角的二维边界框和三维检测的边界框可以量化他们之间的几何一致性。
语义一致性
探测器可输出多个对象的类别,但我们只关联同样类别的候选物体。我们在这个阶段避免阈值检测(或使用非常低的阈值),将阈值的使用留给最终的依据得分的输出阶段。
2D的监测候选物体可以由下面公式表示:
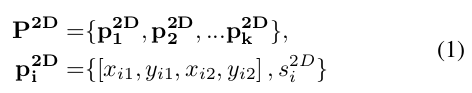
3D的检测候选物体可以由公式2表示:
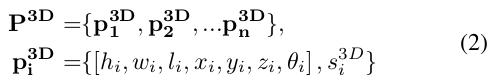
对于k个2D检测和n个3D检测,我可以建立一个k*n*4的长量tensor T,可以表示为
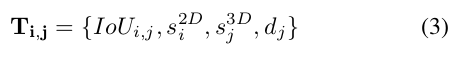
当IoU为0时,相当于这个长量不存在了,因为在空间上他们是几何不一致的。

结果

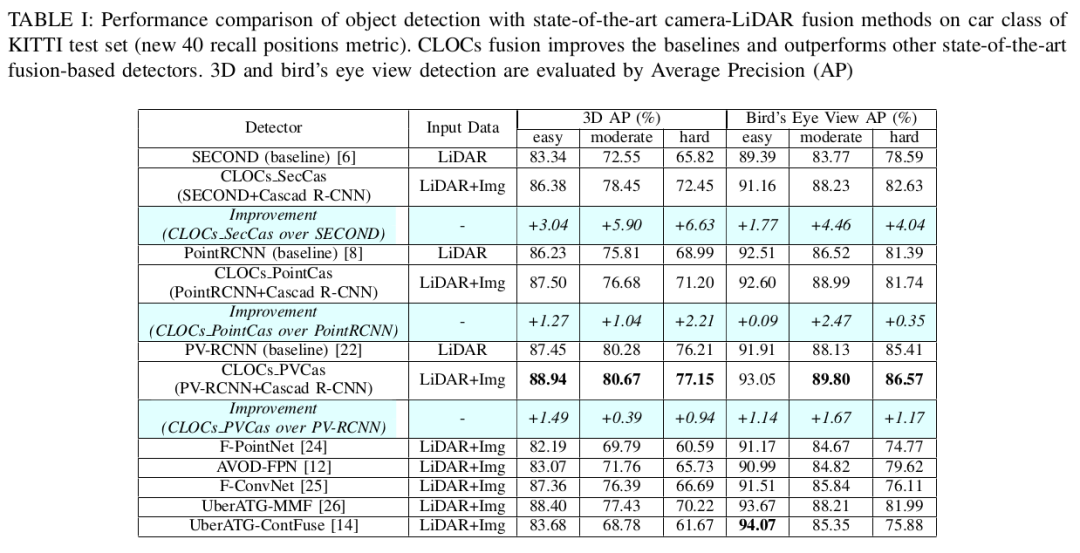
上述表格,使用KITTI数据在各个相机激光雷达融合算法的物体识别比较。可以看到CLOCs融合比其他的融合算法都可以获得更好的效果。
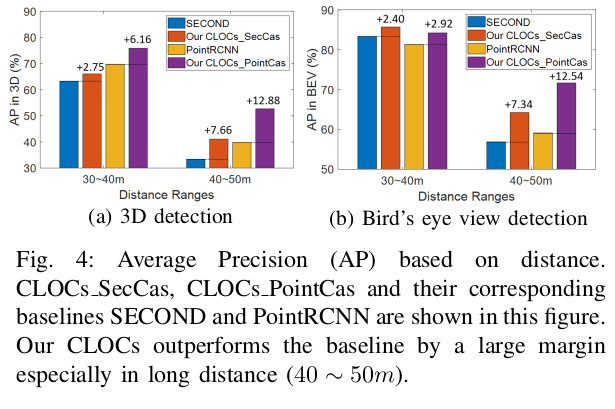
上图是根据距离的平均精确度(AP)的比较,可以看到CLOCs在长距离(40~50m)有更高的精度。

上图为本文提出的CLOCs在KITTI测试集上的结果与SECOND相比较。红色和蓝色的边框是CLOCs分别纠正了来自SECOND的错误检测和未检测的物体。绿色边框是正确的检测。每幅图像的上一行是投影到图像上的三维检测,其余的是激光雷达的三维检测点云。
Abstract
There have been significant advances in neural networks for both 3D object detection using LiDAR and 2D object detection using video. However, it has been surprisingly difficult to train networks to effectively use both modalities in a way that demonstrates gain over single-modality networks. In this paper, we propose a novel Camera-LiDAR Object Candidates (CLOCs) fusion network. CLOCs fusion provides a low-complexity multi-modal fusion framework that significantly improves the performance of single-modality detectors.
CLOCs operates on the combined output candidates before Non-Maximum Suppression (NMS) of any 2D and any 3D detector, and is trained to leverage their geometric and semantic consistencies to produce more accurate final 3D and 2D detection results. Our experimental evaluation on the challenging KITTI object detection benchmark, including 3D and bird’s eye view metrics, shows significant improvements, especially at long distance, over the state-of-the-art fusion based methods. At time of submission, CLOCs ranks the highest among all the fusion-based methods in the official KITTI leaderboard. We will release our code upon acceptance.
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近5000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 
最后
以上就是优秀彩虹最近收集整理的关于CLOCs:一种相机-激光雷达3D目标检测后融合方法的全部内容,更多相关CLOCs内容请搜索靠谱客的其他文章。








发表评论 取消回复