0 调参技巧
- 清洗数据,数据预处理,数据增广
- 是否使用预训练模型
- 使用BN
- 在过拟合后,使用正则化技巧如L1、L2、Dropout
- 对于不均匀样本,使用重采样
- 使用合适的优化器。第一,如果你关心快速收敛,使用自适应优化器,如Adam,但它可能会陷入局部极小,提供了糟糕的泛化。第二,SGD+momentum可以实现找到全局最小值,但它依赖于鲁棒初始化,而且可能比其他自适应优化器需要更长的时间来收敛。我建议你使用SGD+动量,因为它能达到更好的最佳效果。
- 学习率不小于1e-3,可以考虑使用学习率衰减
- early stop
1 使用归一化/标准化会改变数据原来的规律吗?
归一化:将数据映射到指定的范围,如:把数据映射到0~1或-1~1的范围之内处理。作用:有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。简化计算。
min-max 归一化,也叫 0-1 标准化。
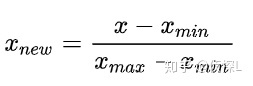
标准化:将数据变换为均值为0,标准差为1的分布,切记,并非一定是正态的。作用:提升模型的收敛速度(加快梯度下降的求解速度)。提升模型的精度(消除量级和量纲的影响)。简化计算(与归一化的简化原理相同)。
z-score 标准化
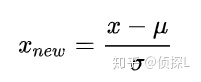
robust 标准化(RobustScaler)
MaxAbs 标准化(最大值绝对值标准化),MaxAbs具有不破坏数据结构的特点,可以用于稀疏数据。
归一化/标准化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化/标准化的前提。比如有一个很重要的性质:线性变换不会改变原始数据的数值排序。
2 如果是单纯想实现消除量级和量纲的影响,用Min-Max还是用Z-Score?
数据的分布本身就服从正态分布,使用Z-Score。有离群值的情况:使用Z-Score。
这里不是说有离群值时使用Z-Score不受影响,而是,Min-Max对于离群值十分敏感,因为离群值的出现,会影响数据中max或min值,从而使Min-Max的效果很差。相比之下,虽然使用Z-Score计算方差和均值的时候仍然会受到离群值的影响,但是相比于Min-Max法,影响会小一点。
3 离群值的应对措施
当数据中有离群点时,我们可以使用Z-Score进行标准化,但是标准化后的数据并不理想,因为异常点的特征往往在标准化后容易失去离群特征,此时就可以用RobustScaler 针对离群点做标准化处理。
4 One-hot编码的定义与作用
定义:
- one-hot标签则是顾名思义,一个长度为n的数组,只有一个元素是1.0,其他元素是0.0。用N位状态寄存器来对N个状态进行编码。
- 将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。
- 输入输出的one-hot编码。
作用:
- 独热编码用来解决类别型数据的离散值问题。
- 提升模型的非线性能力。比如用LR算法做模型,在数据处理过程中,可以先对连续变量进行离散化处理,然后对离散化后数据进行one-hot编码,最后放入LR模型中。这样可以增强模型的非线性能力。
- 为什么要特征向量要映射到欧式空间?将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
优缺点
- 优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
- 优点:非线性能力。
- 缺点:高维稀疏矩阵。一般可以用 PCA + one-hot encoding。
什么场景下使用one-hot编码
- 用:独热编码用来解决类别型数据的离散值问题。
- 用:在很多学习任务中,特征并不总是连续值,而有可能是分类值。
- 用:离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码。
- 不用:将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征本身是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
5 梯度消失 梯度爆炸
梯度消失:梯度趋近于零,网络权重无法更新或更新的很微小,网络训练再久也不会有效果。
梯度爆炸:梯度呈指数级增长,变的非常大,然后导致网络权重的大幅更新,使网络变得不稳定。
解决方法:
- 使用BN
6 Batch Normalization
BN可以固定小批量中的均值和方差,再学习出合适的偏移和缩放(可学习参数为 gamma,beta)。作用在全连接层的输出之后,激活函数前。也可以作用在全连接层的输入上。可以加速收敛速度,但是一般不改变模型精度。一般不配合dropout使用。用了BN后学习率可以稍微调大。
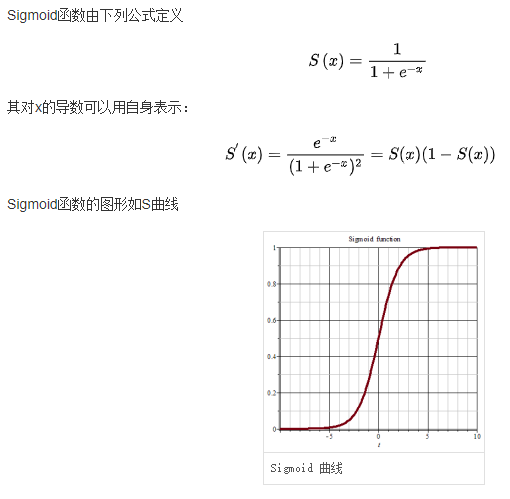
7 sigmoid激活函数
8 准确率
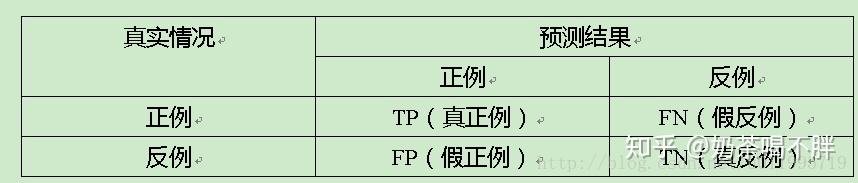
准确率(accuracy)=(TP+TN)/(TP+FN+FP+TN),在所有样本中,预测正确的概率
精确率(precision)=TP/(TP+FP),你认为的正样本中,有多少是真的正确的概率
召回率(recall)=TP/(TP+FN),正样本中有多少是被找了出来
最后
以上就是失眠水杯最近收集整理的关于机器学习面试题目整理的全部内容,更多相关机器学习面试题目整理内容请搜索靠谱客的其他文章。








发表评论 取消回复