分类算法
目录
分类算法
ID3算法
使用增益率C4.5算法
Gini指标 CART算法
CART算法(C&R算法)采用一种二分(划重点)递归分割的方法
CHAID(Chi-square Automatic Interaction Detection,卡方自动交互检测)算法
使用贝叶斯定理
支持向量机SVM
Bagging(装袋)
Boosting(提升法)
C5.0算法中引入Boosting技术以提高模型准确率。
ID3算法
信息熵:。
在构造决策树的过程中,熵定义为无序性度量很合适。
无序性?
举个例子,假设如下数据,需要构造决策树:
| 编号 | 性别 | 专业 | 体育选修是否报名健美操 |
| 001 | 男 | 信管 | 否 |
| 002 | 女 | 信管 | 是 |
| 003 | 女 | 信管 | 是 |
| 004 | 女 | 计算机 | 是 |
| 005 | 女 | 计算机 | 是 |
输入:性别、专业
输出:体育选修是否报名健美操
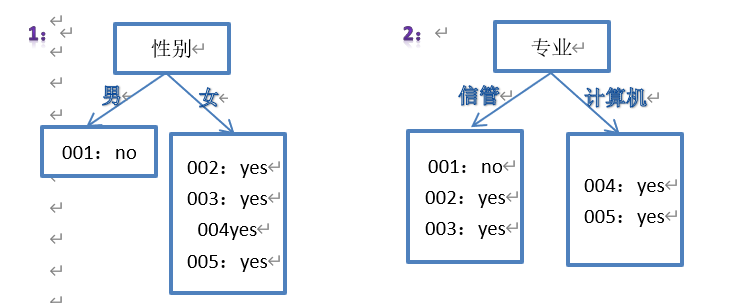
直觉上,哪个分类效果更好?
怎么个好法?怎么度量?所以我们需要一个度量值,能满足:
两个类的情况:
- 当一个节点上全都是yes 或全都是no,称为“最纯”,此时这个度量值为零;
- 当一个节点yes和no个数相同,称为“最不纯”,此时度量值是所有情况中最大的;
同样适用于多个类的情况:
找到一个属性,依据该属性划分后,
- 节点上数据的类值大部分都相同,称为“纯”,低无序性,此时度量值相对较低;
- 节点上的数据的类值均匀分布,称为“不纯”,无序性最大,此时度量值相对教高;
这个度量就把它定义成熵(信息值),单位是“位”,计算公式是:
entropy(p1,p2,…,pn) = -p1log2p1 – p2log2p2 -…-pnlog2pn
其中,p1到pn是每种情况出现的概率
则若节点全部为yes 或者 no,验证其熵为0
:为什么第一种分类比较好?
尝试使用信息熵来度量,
步骤一:得到样本分类的熵(信息值)
I(s1,s2,……,sm)=-∑Pi log2(pi) (i=1..m)
info(1,4)=entropy(1/5,4/5)=-1/5*log2(1/5)-4/5*log2(4/5)
步骤二:得到按属性(假设为A)分类过后的平均信息值(加权平均),也就是由属性划分的样本子集的熵,定义为:
E(A)= ∑j(|s1j|+ ……+|smj|)/|s| * I(s1j, ……,smj)
树1:
第一个分支,info(0,1)=entropy(0,1)= 0 位
第二个分支,info(4,0)=entropy(1,0)= 0位
平均信息值:
E(性别)=1/5 * info(0,1)+ 4/5 * info(4,0)= 0
树2:
留给大家算
E(A)的值越低说明每个子集越纯,分类效果越好
我们希望通过分裂,得到尽可能“纯”的节点,也就是说尽量降低系统的熵是我们的目标。
步骤三:得到信息增益,为步骤一结果减去步骤二结果
最终我们用信息增益(information gain)来衡量选择了该属性进行分类的分类效果
Gain(A)= I(s1,s2,……,sm) - E(A)
显然Gain(性别)> Gain(专业),则按性别分类效果比按专业效果好,而且没有继续往下分的必要性。
下一次,按照该决策树只需要知道学生性别信息就能判断他(她)体育选修是否报名健美操。
整个过程是个递归(归纳)的过程,为了说明问题
更复杂的例子:
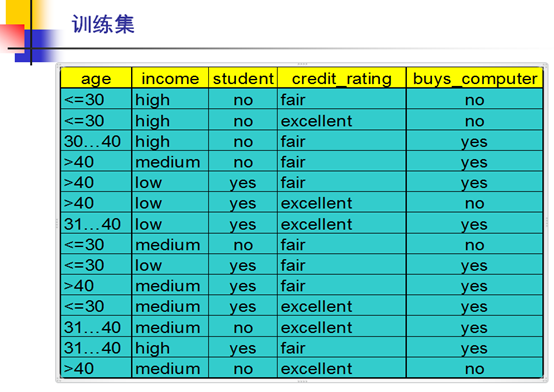
第一轮
1.
Class P: buys_computer = “yes”
Class N: buys_computer = “no”
I(p, n) = I(9, 5) =0.940
2.
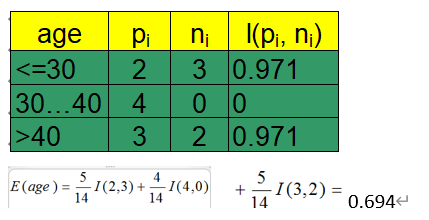
0.694
3.
Gain(age) = 0.940-0.694=0.246
同理可得:

第一轮结束:
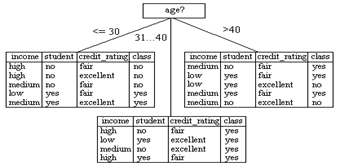
第二轮
:直觉上age<30的分支,再按哪种属性划分能分得最纯粹?
验证:age<30的分支,
1. I(2,3) = 0.971
2.
| Income | P | N | I(P,N) |
| Student | P | N | I(P,N) | Credit_r | P | N | I(P,N) |
| high | 0 | 2 | 0 |
| Yes | 2 | 0 | 0 | Fair | 1 | 2 | .. |
| Medium | 1 | 1 | 1 |
| no | 0 | 3 | 0 | excellent | 1 | 1 | 1 |
| low | 1 | 0 | 0 |
|
|
|
|
|
|
|
|
|
E(income)=2/5*0+2/5*1+1/5*0=0.4
E(student)=0
E(Credit_r)= …
3.
Gain(income) = 0.971-0.4 =0.571
Gain(student)= 0.971-0 = 0.971
Gain(Credit_r)=…
4.最终选择student属性
31-40的分支没有必要进一步划分了;
age>40的分支,直觉上?
我们要明白,不同分支再分,有可能会选择到不同属性
最终得到使用信息增益(Gain)作为选择标准的决策树:
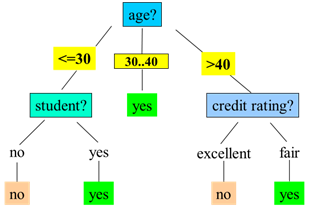
理想情况下,当所有叶节点是纯的而使过程终止,然而,可能无法到达这种结果,因为无法避免训练集包含两个具有相同属性集,但具有不同类的实例。因此,当数据不能进一步划分时,我们停止划分过程。
这个最基础的决策树算法就是ID3(Iterative Dichotomiser,迭代的二分器)
使用增益率C4.5算法
C4.5对于ID3的改进:
- 引入悲观剪枝策略进行后剪枝(悲观误差剪枝)
- 引入信息增益率作为划分标准
- 将连续特征离散化,假设 n 个样本的连续特征 A 有 m 个取值,C4.5 将其排序并取相邻两样本值的平均数共 m-1 个划分点,分别计算以该划分点作为二元分类点时的信息增益,并选择信息增益最大的点作为该连续特征的二元离散分类点
(C4.5既可以处理离散型数据,也可以处理连续型数据)
当某些属性具有大量可能值时,信息增益的计算会出现问题,最极端的例子就是标识码(主键),例如ID,所有节点都是info(0,1),E(ID)=0,则Gain(ID)必定最大,但选ID做分类属性毫无意义
改进:使用增益率Gain ratio
Gain ratio =Gain/固有信息值
固有信息值,也称为分裂信息(SplitInfo)计算所有类别个数的熵
例如age把所有属性分成3类,个数分别是5,4,5,则按age分类的固有信息值是
info(5,4,5) = 1.577
则, Gain ratio(age)=0.246/1.577
但是有时候分裂信息过小,导致增益率大,造成信息增益也大的假象,所以,现实中往往两者结合,首先选择增益率大的属性,其次增益也不能太小,至少达到平均增益的水平。
Gini指标 CART算法
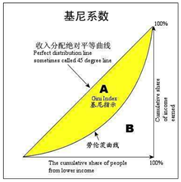
X轴:累计人口百分比;Y轴:累计收入百分比
CART算法(C&R算法)采用一种二分(划重点)递归分割的方法
Gini指数是一种不等性度量,Gini指数的一个修订形式用于度量节点的不纯性。
(度量值和无序性之间保持一定单调性)
两个公式:
Gini(D) = 1 -∑pi2
二元分类时: GiniA(D)= |D1|/|D|Gini(D1)+ |D2|/|D|Gini(D2)
还是考虑这个例子:
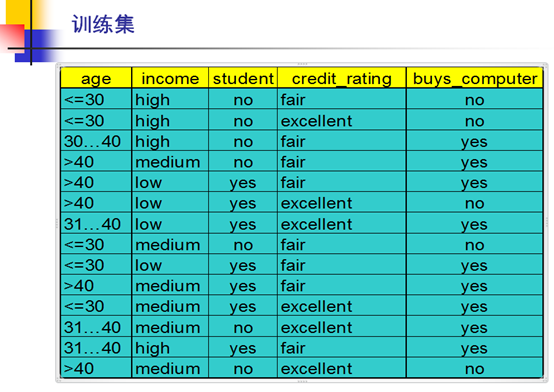
步骤一,使用Gini指标式计算分类的不纯度
设D是训练数据
Gini(D) = 1-(9/14)2-(5/14)2 = 0.459
步骤二,计算每个属性的Gini指标
income属性的Gini指标
income的分裂子集有{low,medium},{high},{low,high},{medium},{medium,high},{low}
每个分裂子集的Gini指标值都要计算,首先计算{low,medium}的指标值
D1是income属性等于low或medium的,共10个,有7个yes,3个no
D2是income属性等于high的,共4个,有2个yes,2个no
Gini income∈(low,medium) = (10/14)*(1-(7/10)2-(3/10)2) + (4/14)*(1-(2/4)2-(2/4)2)
=0.443
显然 =Gini income∈(high)
意思是,按照{low,medium}和{high}来分和按照{high}和{low,medium}来分是等价的。
同理可得Gini income∈(low,high)= Gini income∈(medium)=0.458
Gini income∈(medium,high)= Gini income∈(low)=0.450
因此,属性income最好的二分法是按照{low,medium}和{high}来分
评估属性age,可得最好分法分成{youth,senior}和{middle_aged} 0.357
Gini age∈(youth,senior) = (10/14)*(1-(5/10)2-(5/10)2) + (4/14)*(1-(4/4)2-(2/4)2)
=0.357
显然 =Gini age∈{middle_aged}
属性student 0.367
属性credit_rating 0.429
综上四个属性 age{youth,senior}和{middle_aged}分法,不纯度降低0.459-0.357=0.102,
分类效果最好,由此得到第一层决策树
此方法属于二元分裂,前面的方法属于多路分裂。
Gini指数可以同样应用于数据离散化处理。
【
通过信用卡属性判断是否为特约商户,其中有一个属性是交易金额是离散数值。
采用二分方式进行离散化,计算差异系数,差异系数可以采用Gini指数。
1)计算训练集D的gini指数
2)对每一个分割点(假设500,1000,1500,2000)分别计算各组的gini指数,并计算加权平均值;
3)计算步骤一和步骤二的差值,取差值最大的分割点
】
CHAID(Chi-square Automatic Interaction Detection,卡方自动交互检测)算法
一种基于独立统计X2(卡方)检验的属性选择度量。
具体可见《商务智能》P115
CHAID算法能够较好地处理缺失值、非线性的数据,经常被用于市场分析、生物学研究、居民卫生服务和人力资源分析等领域。
使用贝叶斯定理
贝叶斯的术语中,X是“证据”,例如这个例子n个属性的描述,再具体点比如
X = (age=youth,income=medium,student=yes,credit_rating=fair)
H是某种假设,例如元组X属于某个分类,再具体点buys_computer=yes
我们想得到的是P(H|X),也就是如果某个人age=youth,income=medium,student=yes,credit_rating=fair,那么他buys_computer=yes的概率。
贝叶斯定理是:P(H|X) = P(X|H)P(H)/P(X)
朴素(简单)贝叶斯分类
目的是使用朴素贝叶斯分类预测元组的类别。
还是那个例子,假设计算
P(buys_computer=yes | age=youth,income=medium,student=yes,credit_rating=fair)
首先,计算
P(age=youth,income=medium,student=yes,credit_rating=fair | buys_computer=yes)
可算P(age=youth|buys_computer=yes) =2/9
<=30个数:5,购买电脑的人数:2
30~40个数:4,购买电脑的人数:4
>=40个数:5,购买电脑的人数:3
P(income=medium |buys_computer=yes)=4/9
P(student=yes |buys_computer=yes)=6/9
P(credit_rating =fair|buys_computer=yes)=6/9
则P(age=youth,income=medium,student=yes,credit_rating=fair | buys_computer=yes)
=2*4*6*6/94 约等于0.044
接着计算P(buys_computer=yes)=9/14=0.0643
则 P(X|buys_computer=yes)*P(buys_computer=yes)=0.044*0.643=0.028
同理 P(X|buys_computer=no)*P(buys_computer=no) =0.019*0.357=0.007
对于每一个元组来说P(X)都是一样的,
最后得到结论,对于元组X,朴素贝叶斯分类器预测元组X的类为buys_computer=yes。
有个问题,如果碰到某个P是0怎么办?使用拉普拉斯校准!每个类个数加1个计数,对于大数据量,“校准”的概率和原来的概率很接近,这种方法有效避免0概率。
朴素贝叶斯分类器简单高效,经常被用于入侵检测和文本分类等领域,能比较有效避免对数据的过渡拟合,缺点的要求严格的条件独立性假设,但现实是属性之间一般都存在着一定的相关性。面对这个问题可以用贝叶斯网络来解决,具体可参照《商务智能》P111 。
支持向量机SVM
支持向量机(Support Vector Machine)
数据线性可分:
考虑最简单的二维二类情况
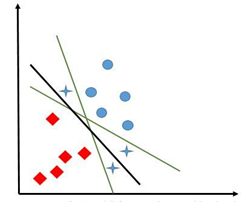
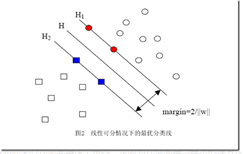
二维(两个属性)情况中,目标是找到一条直线划分出两类;如果是三维那就是找到一个平面,如果是多维,那就是找到一个“超平面”。
绿色的好还是黑色的好?
(这就是“中庸之道”的由来?)
SVM通过搜索最大边缘超平面(MMH)处理分类问题。
如何找到?通过使用一些“特殊的数学技巧”(拉格朗日改写式和KKT条件求解)
通过训练数据得到支持向量机后,使用最大超平面改写的决策边界公式,就能得到新元组的分类(公式略)。
数据非线性可分的情况:
软边缘(Soft Margin):但世界上没这么美的事,很多情况下都是“你中有我,我中有你”的混杂状态。不大可能用一个平面完美的分离两个类别。在线性不可分情况下就要考虑软边缘了。软边缘可以破例允许个别样本跑到其它类别的地盘上去。但要使用参数来权衡两端,一个是要保持最大边缘的分离,另一个要使这种破例不能太离谱。这种参数就是对错误分类的惩罚程度C。
如果实在“软”(妥协)不了,为了解决完美分离的问题,SVM还提出一种思路,就是将原始数据映射到高维空间中去,直觉上可以感觉高维空间中的数据变的稀疏,有利于“分清敌我”。那么映射的方法就是使用“核函数”。如果这种“核技术”选择得当,高维空间中的数据就变得容易线性分离了。而且可以证明,总是存在一种核函数能将数据集映射成可分离的高维数据。这里引入了黑科技“核函数”。目前研究有三种可以使用的核函数包括:h次多项式核、高斯径向基函数核、S形核。
总之,SVM三种模型
SVM有三种模型,由简至繁为
- 当训练数据训练可分时,通过硬间隔最大化,可学习到硬间隔支持向量机,又叫线性可分支持向量机
- 当训练数据训练近似可分时,通过软间隔最大化,可学习到软间隔支持向量机,又叫线性支持向量机
- 当训练数据训练不可分时,通过软间隔最大化及核技巧(kernel trick),可学习到非线性支持向量机
其他还有很多分类算法和方法就不一一列举了。
监督学习(supervised learning)和无监督学习(unsupervised learning)
监督学习:每个训练元组有提供类标号(分类)
无监督学习:每个训练元组的类标号是未知的(聚类)
Bagging(装袋)
给定d个元组的数据集D,
1)使用放回抽样(抽一个放回去,再抽)的方式得到训练集Di
2)对每个Di使用同一个算法,会得到i个分类模型Mi
3)对一个未知的元组X进行分类,每个Mi返回它的类预测,
4)分类结果是得票最高的那个
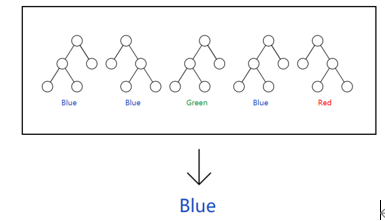
这个结果往往会提高决策树的分类准确率,但一般花费的时间会成倍增长。
对于小数据集,效果表现良好,可以被用于处理大数据集。
Boosting(提升法)
在Bagging的基础上再加上“权重”的作法,
基本思想是,当我们建立分类器时,希望它更关注上一轮被误分类的元组
给定d个元组的数据集D,
1)对每个元组赋予相等的权值1/d
2)使用有放回抽样(同一个元组可能被选中多次)得到大小为d的训练集Di,每个元组被选择的机会由它的权重决定;
3)从训练元组Di得到分类模型Mi
4)使用Di计算Mi的误差,并调整每个元组的权重:如果元组在该Mi下分类不正确,则增加权重,被分类正确,则减少权重。元组的权重反映对它们分类的困难程度
5)重复从2)开始
接着最简单的办法是仍然采用投票最高的那个Mi(每个Mi有相同的表决权)
但通常的作法是,对每个分类器的表决权赋予一个权重,分类器的误差率越低,它的准确率就越高,因此它的表决权重就当越高。
C5.0算法中引入Boosting技术以提高模型准确率。
(具体过程略)
最后
以上就是背后自行车最近收集整理的关于数据挖掘——分类算法分类算法的全部内容,更多相关数据挖掘——分类算法分类算法内容请搜索靠谱客的其他文章。








发表评论 取消回复