- 学习资料
IBM SPSS Modeler 18.0 Applications 第3章
- 应用场景
金融机构根据以往贷款申请人的信息预测申请人具有较低风险还是较高风险
- 数据源描述
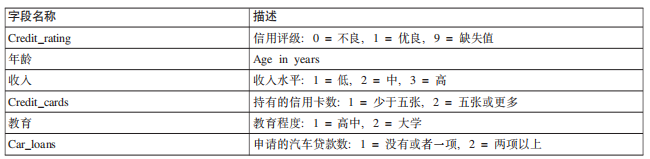
数据源名称tree_credit.sav
- 应用模型
决策树模型中的CHAID(卡方自动交互效应检测)模型
- 分析思路
采用CHAID模型,通过卡方统计计算所有输入字段对目标字段的影响显著性((1)一般计算信息增益,在决策树算法的学习过程中,信息增益是特征选择的一个重要指标,它定义为一个特征能够为分类系统带来多少信息,带来的信息越多,说明该特征越重要,相应的信息增益也就越大。(2)还有计算基尼系数,即根据每个特征进行分类,分类错误率越小,说明该特征越重要),然后由上至下作为决策树的最佳分割点,从而挖掘信用评级为良/不良的人的特征,日后采用这些特征预测申请人发生拖欠贷款的可能性。
- 设计步骤
1、选取源节点“Statistics文件”,读取外部数据源;
Variable names选择Read labels as names
Values选择Read labels as data
(这里由于数据源里的字段和值已经设置有标签,如“持有的信用卡数:1 = 少于五张,2 = 五张或更多”,所以读取标签作为字段和值)
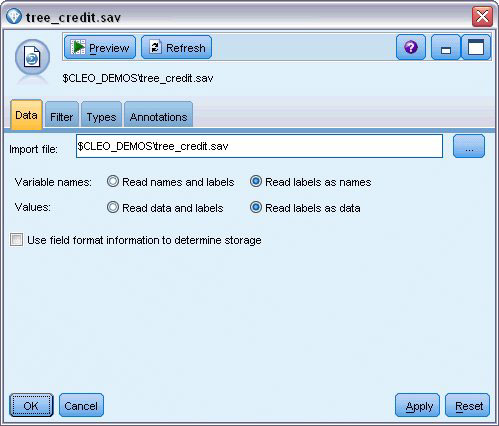
2、选择“类型”字段选项,与源节点连接起来
把Credit_rating的Role设置为Target(输出/目标),
其它字段的Role设置为Input(输入/预测变量),
所有字段的Measurement(数据类型)保持不变,
接着点击Read Valuse读取值。
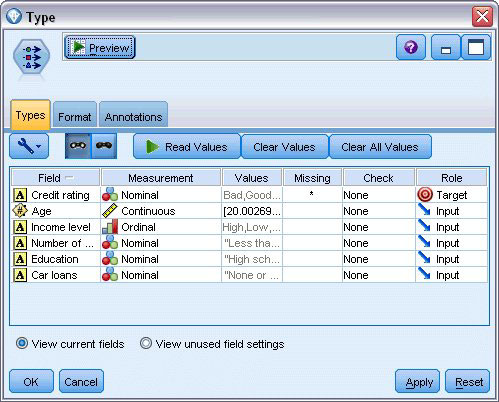
3、选择CHAID模型节点,与字段选项节点连接起来
(1)由于上一步经过“类型”字段选项的设置,CHAID的Fields选项卡将Use predefined roles使用预定义角色,即类型节点中指定的Input和Target。(也可以选择Use custom field assignments,在当前模型节点选项卡上指定Input、Targets、Weight,这里不再重新选择)
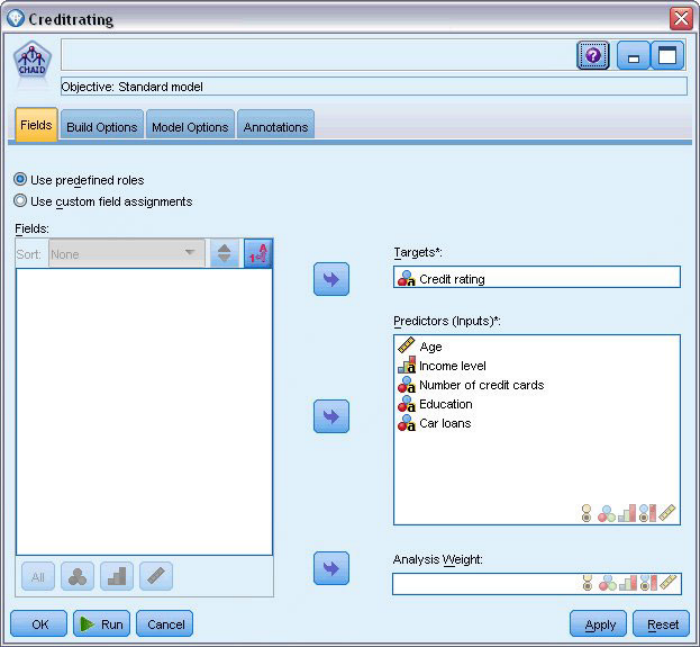
(2)点击Build Options选项卡,从左侧的导航器窗格选择Objective选项,保持默认选项Build new model构建新模型(如果是训练已有模型,选择Continue training existing model),保持默认选项Build a single tree设置决策树为单个标准决策树型,mode保持默认选项Generate model即不包含任何增强,(Launch interactive session 启动允许对模型进行微调的交互建模会话,训练CHAID树时,会开启交互式会话窗口,在交互会话中可以控制树生长和对树剪枝,避免过拟合。)
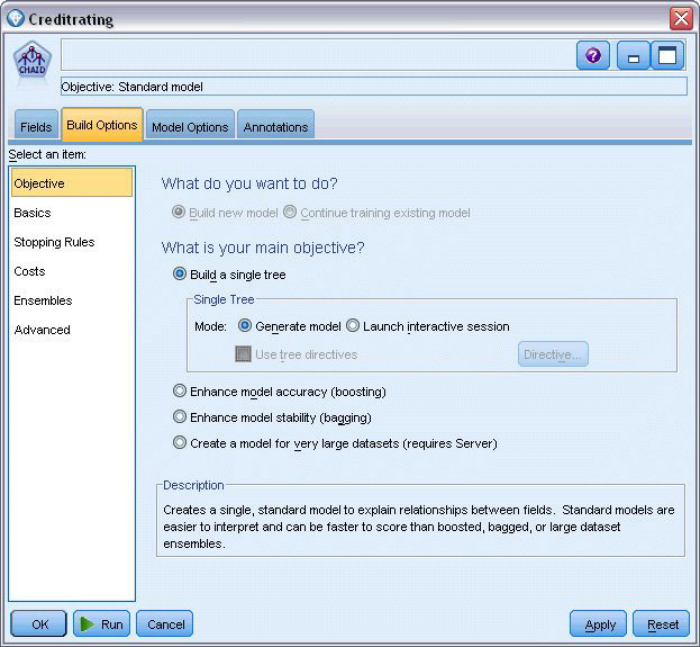
(3)从左侧的导航器窗格选择Stopping Rules选项设置停止决策树生长的规则(剪枝),
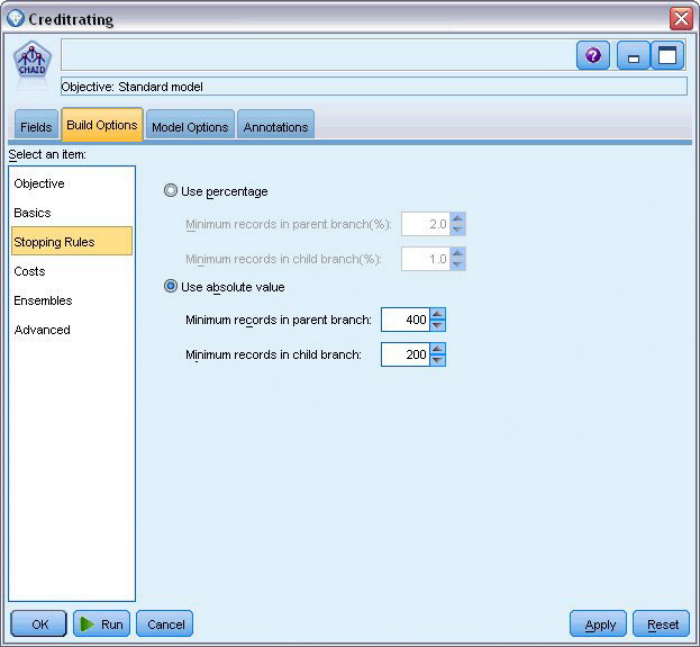
选择Use absolute value使用绝对值选项,父分支中的最小记录数设置为400,子分支中的最小记录数设置为200;(Use percentage 使用百分比,将通过设置父分支和子分支最小记录数占比来停止决策树生长)
(4)运行流,CHAID模型右击选择浏览
- 结果分析与评估
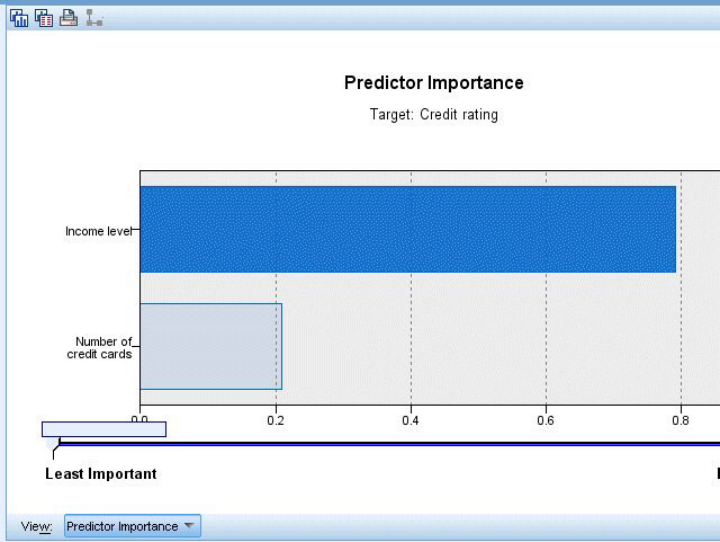
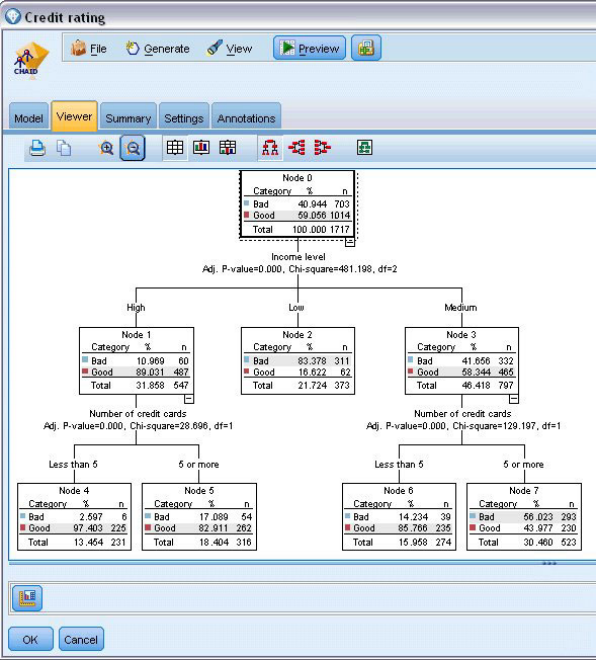
预测变量重要性图表显示对Target影响最显著贡献信息最多的Input是Income level收入水平和Number of credit cards持有信用卡数;
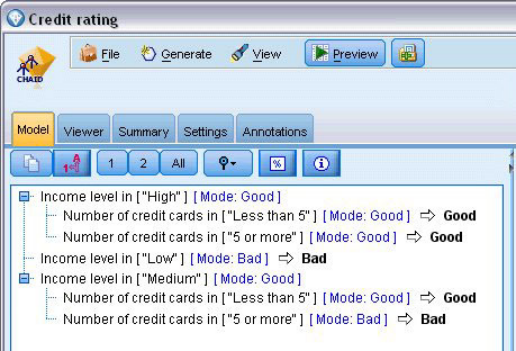
从决策树可知,影响显著性最高的Income level作为第一个最佳分割位置,次高的Number of credit cards作为第二个最佳分割位置;
决策树显示在Node0,优质贷款人比率占59%,而经过第一个最佳分割后,Node1显示具有高收入水平特征的贷款人里低风险贷款人群占89%,比率从59%上升到了89%,到了Node4显示具有高收入水平且同时具有少于5张信用卡特征的贷款人里低风险贷款人群占97%,比率从89%上升到97%。由此可以发现“高收入水平”和“持有少于5张信用卡”这两个特征可以很好地筛选出低风险贷款对象。
为了评估模型的准确度, 需要对记录进行评分, 并将模型预测的响应与实际结果进行比较。我们将对用于估算模型的同一记录进行评分,从而对观察到的响应与预测响应进行比较。
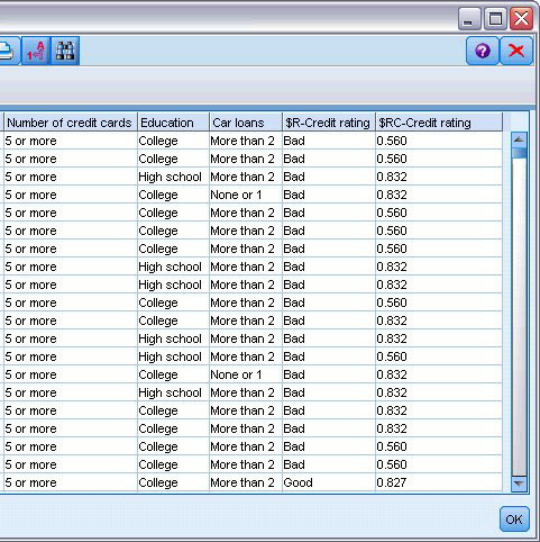
按照惯例,在评分过程中生成的字段的名称基于目标字段,但是要加上标准前缀。前缀 $G 和 $GE 由广义线性模型生成, $R 是用于本例中的 CHAID 模型所生成的预测的前缀, $RC 用于置信度值, $X 通常是使用整体生成的, 而 X R 、 XR、 XR、XS 和 SXF 在目标字段分别为“连续”、“分类”、“集合”或“标志”字段的情况下用作前缀。不同的模型类型使用不同的前缀集。(置信度值是模型自身对每个预测值的准确度的估计, 范围为 0.0到 1.0。)
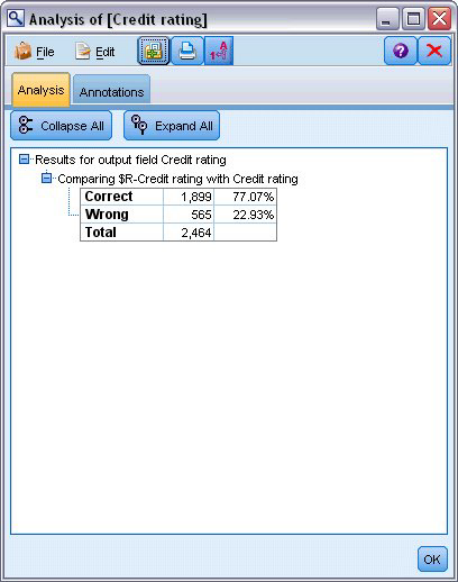
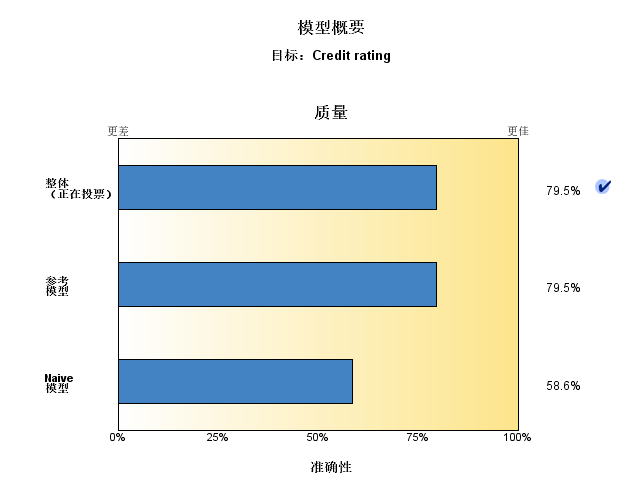
分析表明,对于2464条记录中的1899条记录(超过77%)模型预测的值与实际响应相匹配。
由于训练与测试模型的记录是相同的记录,评分的结果会受到限制如出现过拟合的情况,可以尝试改变方式,使用分区将记录数据拆分为训练数据集和测试数据集,再对模型进行训练和测试。
- 补充
Boosting算法
CHAID模型节点的Build Options选项卡下,左侧的导航器窗格Objective选项下可以选择Boosting;
Boosting是一种可将弱学习器提升为强学习器的算法,这种算法的工作机制类似:先从初始训练集训练出一个基学习器(模型1),再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多的关注,然后基于调整后的样本分布来训练下一个基学习器(模型2);如此重复进行,直至基学习器数目达到事先指定的模型数量(默认组件模型为10),最终将这些基学习器(模型1-10)进行加权结合(默认方式为投票)。
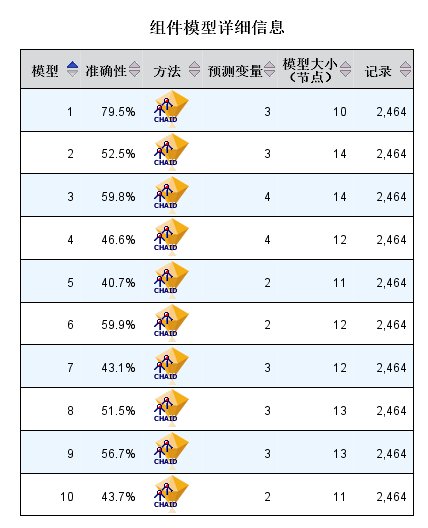
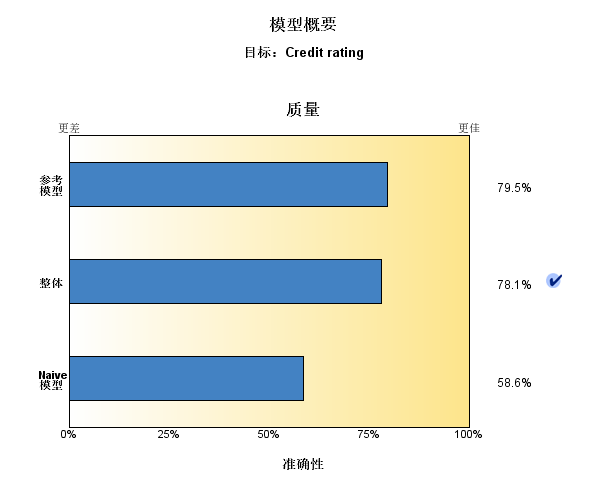
Bagging算法
Bagging 算法又称为装袋算法,Bagging 方法有很多种,其主要区别在于随机抽取训练子集的方法不同: ①. 如果抽取的数据集的随机子集是样例的随机子集,称为 Pasting ②. 如果样例抽取是有放回的,称为 Bagging ③. 如果抽取的数据集的随机子集是特征的随机子集,称作随机子空间(Random Subspaces) ④. 如果基估计器构建在对于样本和特征抽取的子集之上时,称为随机补丁(Random Patches),也就是说在 Bagging 中,一个样本可能被多次采样,也可能一直不被采样。
Bagging算法的工作机制类似分别有放回地抽取同样大小的10个样例,对应分别构造10个弱学习器(默认组件模型为10),10个弱学习器相互之间是并行独立的关系,可以同时训练,最终将10个弱学习器进行加权结合(默认方式为投票);由于这种工作机制,可以减少模型方差,增加模型稳定性,防止过拟合。
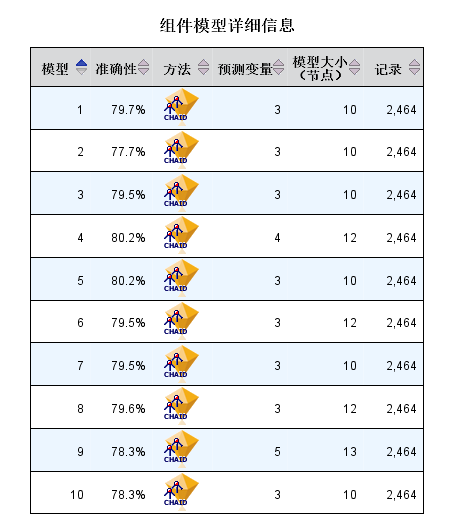
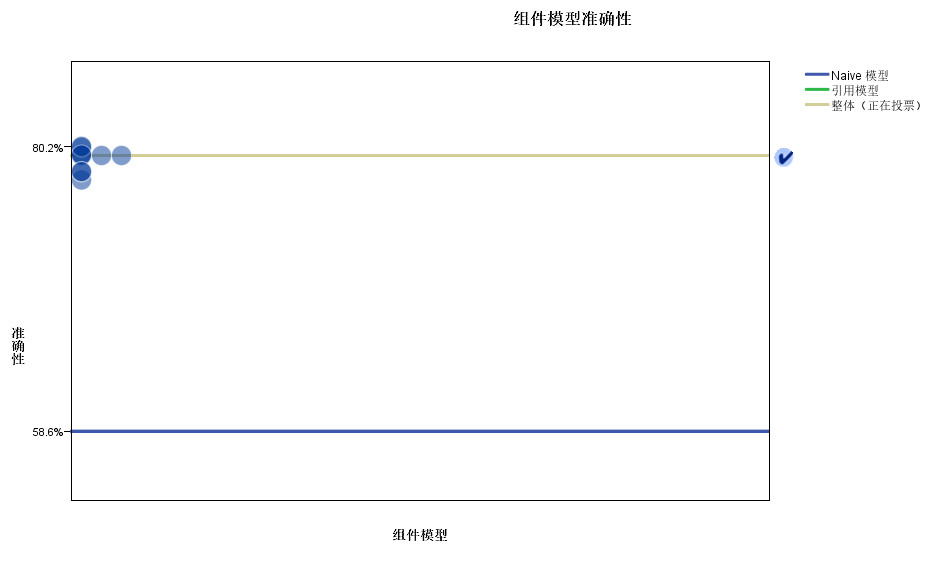
树深度
CHAID模型节点的Build Options选项卡下,左侧的导航器窗格Basics选项可以设置树生长的深度(默认为5),构造树的基本想法是随着树深度的增加,节点的信息熵迅速地降低。信息熵降低的速度越快越好(信息增益越大越好),这样我们有望得到一棵高度最矮的决策树。
信息熵计算公式:
−
∑
i
=
1
N
p
i
l
o
g
2
p
i
-displaystylesum_{i=1}^Np_ilog2p_i
−i=1∑Npilog2pi
显著性水平
Advanced可以设置分割的显著性水平(默认为0.05)即判断输入与输出之间差异是否显著的标准;
默认使用Bonferroni矫正法做多重检验矫正,将显著性水平0.05除以要比较的次数n,再作为判断显著性的值;
设定原假设为H0:输入(预测变量)与输出(目标)相互独立互不相关;
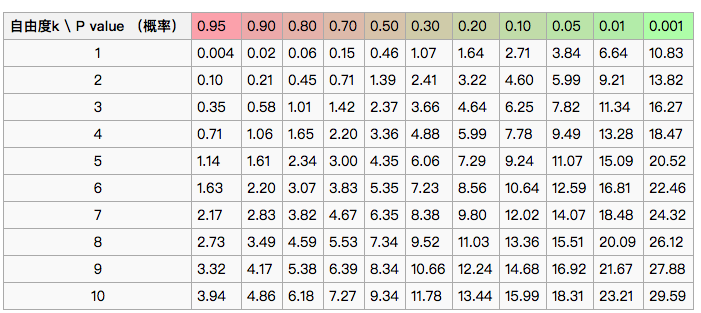
根据卡方检测计算出卡方值(观察值与理论值的之间的偏离程度),结合卡方分布和自由度,确定H0成立的情况下获得当前卡方统计量以及更极端情况的概率p,如果p<0.05,说明观察值与理论值的偏离程度大,拒绝原假设H0。
卡方检验:
x
2
=
∑
(
A
−
T
)
2
/
T
x^{2}=sum(A-T)^{2}/T
x2=∑(A−T)2/T (A为实际值,T为理论值)
Income level 卡方值为481.198,自由度df=2,远大于5.99,对应p<0.05,拒绝原假设H0
Number of credit cards 卡方值为129.197,自由度df=1,远大于3.84,对应p<0.05,拒绝原假设H0
相关系数
Advanced可以设置相关系数(默认为皮尔逊相关系数)也可以选择似然比
皮尔森相关系数是一种线性相关系数,用来反映两个变量X和Y的线性相关程度,介于-1到1之间,绝对值越大表明相关性越强。
似然比表示θ取不同值对应的似然函数的比值,比值越大越倾向于拒绝原假设H0,相关性越强。
最后
以上就是懦弱犀牛最近收集整理的关于SPSS Modeler CHAID建模学习笔记的全部内容,更多相关SPSS内容请搜索靠谱客的其他文章。








发表评论 取消回复