我是靠谱客的博主 美丽小兔子,这篇文章主要介绍场景文本编辑(文本图像风格迁移)场景文本编辑outlinearchitectureloss functionmetricsDatasetstrain resulttestproblems,现在分享给大家,希望可以做个参考。
场景文本编辑
场景文本编辑也叫文本图像风格迁移,在保留原始字体、颜色、大小和背景纹理的同时,对场景图像中的文本进行交换。
比较新的相关研究大概找到了三篇文章
- 1.Editing-Text-in-the-Wild
CVPR2019,有开源代码 - 2.Scene-Text-Editor-using-Font-Adaptive-Neural-Network
CVPR2020 有开源代码 - 3.SwapText: Image Based Texts Transfer in Scenes
CVPR2020 目前还没有开源代码
本人当前复现了SRNet网络(Editing-Text-in-the-Wild), 同时也正在复现STEFANN网络(Scene-Text-Editor-using-Font-Adaptive-Neural-Network)
对于论文的解读,感兴趣可以仔细看看论文,下面就贴一些我所做的工作,SRNet网络效果不是很好,下一步计划复现STEFANN网络
outline
从以下几点来介绍
1.网络结构
2.损失函数
3.评估指标
4.数据集
5.模型训练
6.模型测试
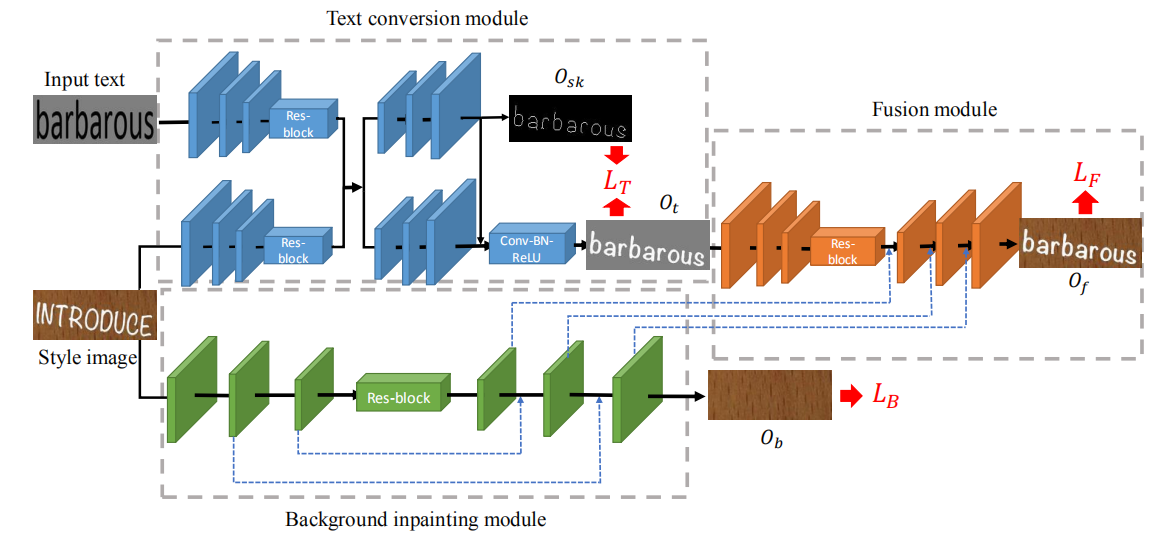
architecture
loss function

metrics
- MSE
- PSNR
- SSIM
Datasets
- 合成数据
- style image、target image、foreground text、text skeleton、background
- text image:将图像高放缩到64,保持宽高比
- 训练集:50000张图片
- 测试集:500张图片
- 真实数据集
- 来自 ICDAR 2013(自然场景文本数据集),主要用于英语文字检测和识别
- 训练集:229张图片
- 测试集:233张图片
- 通过将文字区域裁剪掉,将裁剪区域送入训练好的网络,来进行文本图片迁移
- 注意
- 在数据集使用过程中,使用合成数据训练模型,真实数据用于测试模型
train result
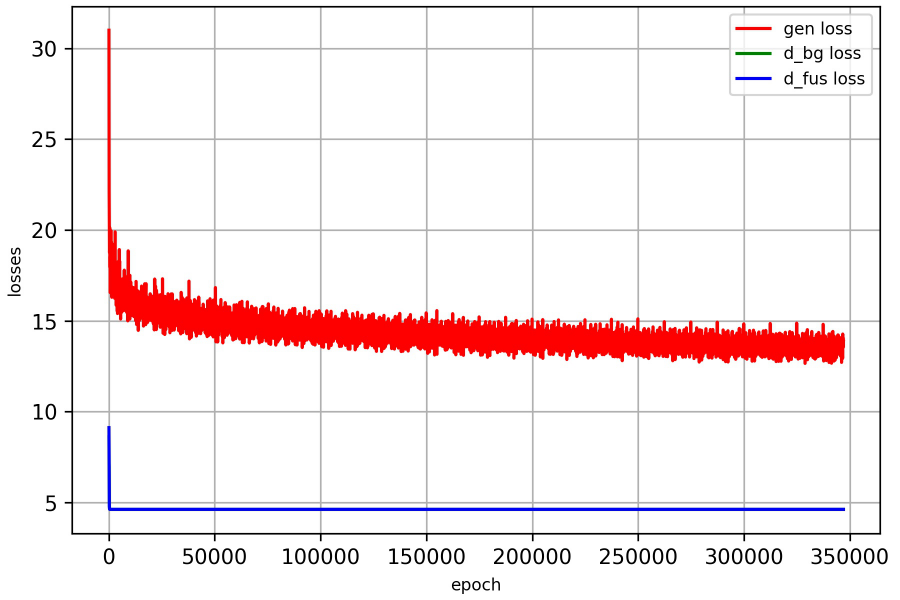
SRNet网络代码作者说,他训练了10个小时迭代了180k-200k次,网络就收敛了,同时loss收敛值为9.0左右,并且达到了论文的效果。我训练了350k次,loss收敛值在14左右。
test
代码里面自带的测试图片

自制测试图片

problems
- 模型收敛的loss值比较高,待优化!!!
- 模型训练使用合成的数据,图片背景与文字形态需要多样化,提高模型的泛华能力;
- 模型预测输出的图片尺寸比较小,往往小于风格图片, 分辨率较低;
- 模型预测输出的中间图片比较乱(如foreground text、text skeleton、background),与GT的差距比较大。
最后
以上就是美丽小兔子最近收集整理的关于场景文本编辑(文本图像风格迁移)场景文本编辑outlinearchitectureloss functionmetricsDatasetstrain resulttestproblems的全部内容,更多相关场景文本编辑(文本图像风格迁移)场景文本编辑outlinearchitectureloss内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复