/**
* @author wangdaopo
* @email 3168270295@qq.com
*/
影响音频质量和稳定性的因素
音质好坏的评价,响度、音高、音色,
测试,你的语音引擎是基本可用的,客观评测软件是RMAA(RightMark Audio Analyzer;比较适合开发者自己去做,在上线前自测的一些方法
频率与音色的听音训练 及 训练音乐听觉
语音通信中提高音质的方法
音频软件开发中的debug方法和工具
-
影响音频质量和稳定性的因素到底有哪些 实时语音到底有哪些特征?
0.通话中语音信息丢失了,这个对话是根本不能继续下去的
1.网络随机性(丢包 延时 抖动):都会导致听感滞后或者断续;网络对音频质量的影响是非常直观的,如果承载音频信息的语音包在网络传输的过程中丢失,晚到,或者不均匀的到,就会造成我们常说的丢包,延时和抖动。另外值得一提的是,除了在传输层引起的丢包抖动,最后一公里(Last Mile)的问题(路由器,移动数据网络等)也会引起丢包抖动
实时语音的问题很难去定位 语音卡顿,到底是什么原因? 问题多源性:你首先想到的肯定是网络,网络会卡顿。 其实还有别的原因会引起卡顿,比如设备CPU负荷很高时,录放音调度有问题,也会导致声音的卡顿。更隐性的问题,比如回声消除,
2.设备 (声学设计,计算能力):听感体验很大程度受到录放音设备的制约,扬声器之间的耦合很大,或者扬声器的非线性很大,导致你的算法不能很好贯通在上面,导致听感上有一些卡顿、毛刺的问题。
3.物理环境 (密闭环境,噪声, 啸叫等)比如我在一个很吵的环境和你打电话,或者我在很小的房间跟你打电话感觉是不一样的;还有远场拾音,比如做电视应用,必须要在2米以外收音,这个时候麦克风的拾音效果决定了音频听到的体验
听音
建议对通话进行录音,这样可以在测试后重听和标注,更好的分析问题。如果测试的引擎不带录音的话,可以在外放的而环境通过外部设备来录制。
一般我们先在较好的网络状态下测试音频的基础质量,然后慢慢增加丢包率来测试一个引擎抗丢包的边界。
音频软件开发中的debug方法和工具
1 log
2 最小系统法
做一个软件系统时刚开始是一个最小系统,即缺了任何一个模块,系统不能用。后来加上一个个功能使系统完备。在写代码时我们可以加上一些标志位使这些后加的功能enable或者disable。这有助于后面出现问题时排查。下图是语音通信的软件框图,最小系统是采集播放编解码网络发送接收等,没有这些不能通话。而前处理的一些模块(AEC/ANS/AGC等)则不是最小系统里面的,它们是后来一步步加上去的。假设系统出问题了,我们先disable前处理的诸多模块,形成最小系统,看有没有问题,有说明问题在最小系统里,再继续调查。没有的话先把AEC使能看有没有问题,有说明问题在AEC里,没有说明问题在ANS或者AGC里。如没有问题继续使能ANS看是否有问题,有说明问题在ANS里,没有说明问题在AGC里。经过这几步基本定位问题在哪个模块里,后面再结合其他方法直到找到根本原因。
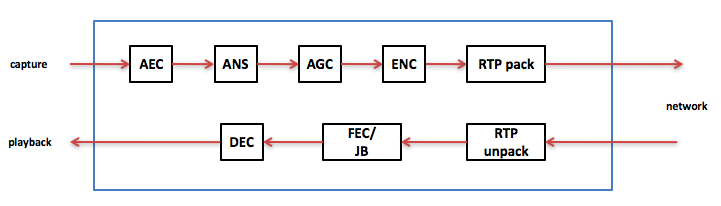
音频开发时不管是voice还是music好多问题是音频听下来不对,这时就要用音频特有的debug方法了。
3 dump音频数据
Dump音频数据就是把音频数据dump出来用工具(比如CoolEdit, 后面讲工具时会具体讲)播放,或者看波形,或者看频谱,看是否正确。一般是找几个可能的dump点,进模块前一个dump点, 出模块后一个dump点。如果进模块前dump出来的数据是好的,而出模块后的音频数据是坏的,那么问题就出在这个模块了,再一步步排查,最终找到把音频数据写坏的地方。还是以上面的语音通信软件框图为例,在AEC前设一个dump点,AEC后再设一个dump点,如果AEC前的音频数据是好的,AEC后的音频数据不好了,问题肯定出在AEC里。
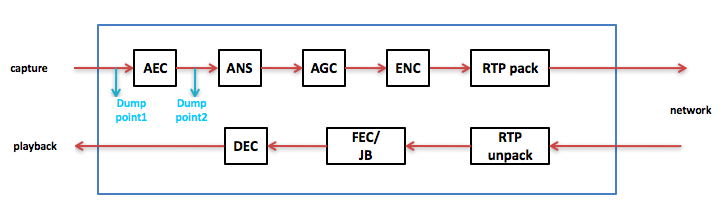
Dump音频数据也有几种不同的方法,在不同的场合用不同的方法。
a)把音频数据写进指定的文件里,问题复现后把这个文件导出来用工具分析。
b)把音频数据放进RTP包里发送到指定的IP地址上,用抓包工具(比如wireshark, 后面讲工具时具体讲)抓到这些包。由于是PCM数据,在wireshark上可以直接听或者看波形。这多用于语音通信场景。
c)有时候有些模块对自己是黑盒的,比如在linux下kernel space的音频驱动对做use space的来说就是黑盒。在use space里调查下来音频数据没问题,但是最终从扬声器或者耳机出来的音频是有问题的,这时可以用一根音频线一头连着出问题的设备的耳机,另一头连着电脑,复现问题,用CoolEdit把出问题时的音频录下来,先听确认问题出在这个黑盒模块里,然后看波形,是否有规律,如果有规律,好查一些,没规律再具体问题具体分析。
4 loopback音频数据
loopback音频数据就是形成回环,从而来排查问题。还是以上面的语音通信软件框图为例,有几种不同层次的loopback,见下图:
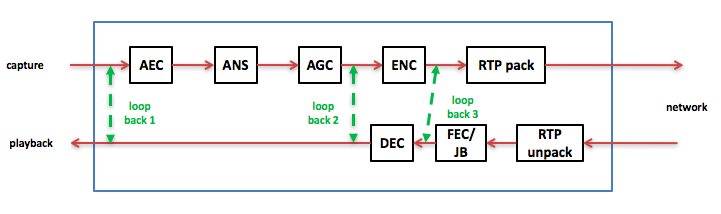
1) 把采集和播放形成loopback,即把采集到的音频数据立刻payback出来,听下来是好的说明音频驱动没问题,不好说明问题在音频驱动里面。
2) 把前处理后的数据和播放形成loopback,即把ANS后的PCM数据直接播放出来,听下来是好的说明前处理没问题,不好说明问题在前处理里面。
3) 把编码和解码形成loopback,即把编码后的码流立刻放进解码器得到pcm数据再playback出来,听下来是好的说明问题出在网络侧,不好说明问题出在编解码里面。
通过上面几个loopback基本上可以定位问题出在哪个模块里,再在这个模块里仔细调查直到找到根本原因。
5,工具
上面讲方法时提到了几个工具,如CoolEdit,下面具体讲。
1)CoolEdit / Audition
这应该算是做音频开发的必备工具了。以前叫CoolEdit,后来被Adobe收购重新包装后形成了Audition。我个人还是习惯于用CoolEdit,原因一是用习惯了,二是CoolEdit可以保存成PCM文件,而Audition却不可以,做音频开发的保存成PCM文件最方便。
用CoolEdit可以听音频是否正常,也可以看波形,在出问题时看波形是否有规律,还可以看频谱。同时还可以生成一些特定的音频文件用于去调试。比如调试音频算法时用一个时间相对较长的(> 1秒)的音频文件会很不方便,主要是因为log多,不便于分析。算法通常一帧为10ms或者20ms,需要几帧就可以调试算法了。这时用CoolEdit做一个几十ms的PCM文件给算法调试用。再比如用CoolEdit做一个20HZ到20000HZ的扫频文件作为某个算法或者某个系统的输入,看这个算法或者系统的频响如何。
CoolEdit的具体使用可以看help文件,或者看网上的文章,这里就不详细讲了。
2)Wireshark
Wireshark主要用于语音通信场景,抓网络上的语音包。当然它也可以抓其他类型的包,在做音频开发时就是抓语音相关的RTP/RTCP包了。抓到包后可以看某个具体包的RTP/RTCP属性,比如sequence number/time stamp等,从而去分析定位问题等。Wireshark也可以分析丢包率等,还可以播放codec 为g711的语音包,当然还有其他用途,这里就不一一说了,有需求的可以到网上看具体的文章。
3)mediainfo
Mediainfo主要用于音乐场景,用它可以看到一个音乐文件(例如MP3)的属性,有采样率/声道数/codec类型/码率等。如果在log中看到的打印值和mediainfo中显示的值对不上,说明读取音乐文件属性的代码有问题。
4)GoldWave
GoldWave也主要用于音乐场景,用它来做采样率/codec/码率等的转换。支持的采样率、codec、码率都特别多,对调试有不少帮助。例如某个系统要支持采样率为11025HZ的音乐文件,但是市面上的音乐文件一般为44.1KHZ或者48KHZ的,这就需要专门的工具去做转换,从而得到想要的文件。然后拿这个文件去调试测试看系统是否支持采样率为11025HZ的音乐文件。
-
在音质好坏的评价中,最重要的是这四个方面的对比,把这四点的思路理顺了,在选择或评测时就不至于会无从下手:
1、音色的“冷”、“暖” 选择。
2、音场的“空间感”和“定位感”对比。
3、平衡度的“左右声道音量及分离程度”和“三频量感平衡”对比。
4、解析力的三频质感和层次感、细节还原能力对比。
看起来是少,但实际上涉及的面很广,要运用起来还真不简单呢!
一、选择音色:暖色调的音色听起来温和闲适(欧洲的产品大多数声音偏暖),适合听古典乐;而冷色调听起来则冷酷干脆(亚洲的产品大多数声音偏冷),适合听摇滚乐
二、对比声场 :感觉空间越大、定位越准确就越好。
(1)空间感 倘若想要听到立体的空间感只能多听多想,
在 欣 赏音乐时可以闭上眼睛,想象自己正坐在观众席上,声音是从舞台上传来的。请把音量尽量调小,你会发现这时声 音离 你远了——原来你坐在剧场的后排!
(2)定位感
定位感就是说能否准确分辨出声音的位置。
就要比较各种声音定位的准确性:比如听流行歌曲,一听就知道人在前面,鼓在人后面,吉他在左,钢琴在右,更进一步,听出他们相距多远,很明显就在这个位置,OK!
三、对比平衡度
这是要比较两个声道的音量平衡、声道分离度和三频量感平衡。这正像作画时也要顾及色彩平衡一样。
(1)声道音量平衡、声道分离度
对比声道音量平衡,就是对比左右声道音量是否一样。
对比声道分离度,就是对比本来只是左(右)声道的声音,右(左)声道是否也在凑热闹。
这个其实不重要,因为至今我还没见过有哪个产品能牛逼到声音不均衡也敢出来卖的地步。这个一般在使用仪器的客观评测中才看得出差别。
(2)三频量感平衡
这 个 是说高频、中频和低频的音量是否一致,
我们说的频段分为极低频(20Hz—40Hz)、低频(40Hz—80Hz)、中低频(80Hz— 160Hz)、 中频(160Hz—1280Hz)、中高频(1280Hz—2560Hz)、高频(2560Hz—5120Hz)、极高频(5120Hz — 20000Hz)。 比如大家平时说,低音真爽,可能就是说低音的量感很足,低音被突出了,这样不好吗?好,但从还原音质的角度看,就是失真了。
高频量感不足,听起来会觉得压抑;中频量感不足,听起来则不够结实;低频量感不足,听起来就显得平淡。一般来说,三频量感越均衡,声音就越有层次,但不是绝对,下面我会说到。
四、解析力
如果说上面三个要点说的都是横向的,主要抓整体感觉,对比较为简单,那么解析力这项说的就是纵向的,要抓住整体的一个点深究,就是对细节处理能力。这像一幅好的画作,不是画完就好,还要有优秀的细节。在解析力方面,我们要比较三频的质感、音乐的层次感和细节还原能力。
(1)三频质感,质感说的是质量的好坏。高频主要对比透明感——透明感比较抽象,在同一个频率,小提琴的音色比二胡要透明,而钢琴的音色则比小提琴更透明。透明的声音是明亮清澈的,反之则会感觉暗淡和毛刺。声音不是越透明越好,但决不能不透明。 中频主要对比结象力——就是要感觉声音是否结实饱满,有没有底气不足或飘来荡去定位不准(再通俗说就是真实感一定要强)。 低频要比较密度、力度和清晰度——鼓声是否清晰有力、下潜是否底气十足等都要考虑进去。
(2)层次感
声音是否有层次,是由多项因素决定的,声音层次分明的机器对细节的再现能力自然更强。
对比层次感,主要应该考虑三项(这也是音质的最低要求):声音是否清晰细腻、三频的质感和量感是否平衡、乐曲中最大音量与最小音量的落差。
(3)细节还原能力
比 如 人声的齿音、乐器的泛音等等。关于细节还原能力,还有“空气感”一说,这是个只能意会不能言传的微妙感觉,好象声音在传播到你耳朵的途中带动的空气震动
-
其中响度、音高、音色可以在主观上用来描述具有振幅、频率和相位三个物理量的任何复杂的声音,故又称为声音“三要素”;而在多种音源场合,人耳掩蔽效应等特性更重要,它是心理声学的基础。
1.响度 响度,又称声强或音量 人耳对响度的感觉有一个从闻阈到痛阈的范围。
人耳对3kHz—5kHz声音最敏感,幅度很小的声音信号都能被人耳听到,而在低频区(如小于800Hz)和高频区(如大于5kHz)人耳对声音的灵敏度要低得多。通常200Hz--3kHz语音声压级以60dB—70dB为宜,频率范围较宽的音乐声压以80dB—90dB最佳。
正常人听觉的强度范围为0dB—140dB(也有人认为是-5dB—130dB)。固然,超出人耳的可听频率范围(即频域)的声音,即使响度再大,人耳也听不出来(即响度为零)。但在人耳的可听频域内,若声音弱到或强到一定程度,人耳同样是听不到的。
当声音减弱到人耳刚刚可以听见时,此时的声音强度称为“听阈”。
一般以1kHz纯音为准进行测量,人耳刚能听到的声压为0dB(通常大于0.3dB即有感受)、声强为10-16W/cm2 时的响度级定为0口方。而当声音增强到使人耳感到疼痛时,这个阈值称为“痛阈”。以1kHz纯音为准来进行测量,使人耳感到疼痛时的声压级约达到140dB左右。
闻阈和痛阈是随声压、频率变化的。闻阈和痛阈随频率变化的等响度曲线(弗莱彻—芒森曲线)之间的区域就是人耳的听觉范围。
通常认为,对于1kHz纯音,0dB—20dB为宁静声,30dB--40dB为微弱声,50dB—70dB为正常声,80dB—100dB为响音声,110dB—130dB为极响声。
而对于1kHz以外的可听声,在同一级等响度曲线上有无数个等效的声压—频率值,例如,200Hz的30dB的声音和1kHz的10dB的声音在人耳听起来具有相同的响度,这就是所谓的“等响”。小于0dB闻阈和大于140dB痛阈时为不可听声,即使是人耳最敏感频率范围的声音,人耳也觉察不到。
一般应特别重视加强低频音量。通常200Hz--3kHz语音声压级以60dB—70dB为宜,频率范围较宽的音乐声压以80dB—90dB最佳。
2.音高 音高也称音调,表示人耳对声音调子高低的主观感受。客观上音高大小主要取决于声波基频的高低,频率高则音调高,反之则低,单位用赫兹(Hz)表示 人耳对频率的感觉同样有一个从最低可听频率20Hz到最高可听频率别20kHz的范围。响度的测量是以1kHz纯音为基准,同样,音高的测量是以40dB声强的纯音为基准。实验证明,音高与频率之间的变化并非线性关系,除了频率之外,音高还与声音的响度及波形有关。音高的变化与两个频率相对变化的对数成正比。在音乐声学中,音高的连续变化称为滑音. 根据人耳对音高的实际感受,人的语音频率范围可放宽到80Hz--12kHz,乐音较宽,效果音则更宽。
3.音色 音色又称音品,由声音波形的谐波频谱和包络决定。声音波形的基频所产生的听得最清楚的音称为基音,各次谐波的微小振动所产生的声音称泛音。单一频率的音称为纯音,具有谐波的音称为复音。每个基音都有固有的频率和不同响度的泛音,借此可以区别其它具有相同响度和音调的声音。声音波形各次谐波的比例和随时间的衰减大小决定了各种声源的音色特征,其包络是每个周期波峰间的连线,包络的陡缓影响声音强度的瞬态特性。声音的音色色彩纷呈,变化万千,高保真(Hi—Fi)音响的目标就是要尽可能准确地传输、还原重建原始声场的一切特征,使人们其实地感受到诸如声源定位感、空间包围感、层次厚度感等各种临场听感的立体环绕声效果。
有的开发者说,他们自己做了实时语音的功能,在自己的测试中觉得没有问题,在公司测得都很好,也通过了。上线后,收到很多用户反馈:为什么你的语音这么卡,为什么有回声,为什么会有杂音?。他们才发现这些问题其实并不是这么容易定位的,也不能像平时我们解BUG那样快速修复这样的问题。再追溯回来他们发现这背后跟很多网络相关的优化、音频底层的算法都有很大的关系,这一块他们自己也解决不了,所以就会出现比较尴尬的局面。
当我们有一个语音引擎在手里,我们已经调通了,出声了,到上线究竟还有多远?
音频很重要
-
测试你的语音引擎是基本可用的,客观评测软件是RMAA(RightMark Audio Analyzer;比较适合开发者自己去做,在上线前自测的一些方法
这么多复杂的问题,业界一般怎么处理?
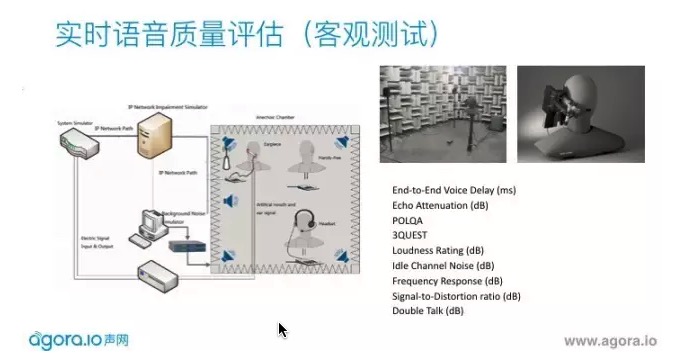
手机公司会有很大的消声室,是用来规避一些不确定外界声源的影响。还需要有人工头、人工嘴和人工耳做高保真的放音和收音,四周有高保真的音响放出自由场的噪声源,模拟不同网络状况。会测试回声,语音在干净或噪声环境下的得分,双降的性能。每个手机出场之前都会做这样的测试。
但这一般开发者来说门槛很高,这样一套设备很贵,我们有没有更经济合理的方法做测试?
1.客观测试-关于音质评价 比较牛B的客观评测软件是RMAA(RightMark Audio Analyzer),一般客观评测评讲的是下面六个参数(以RMAA的评测项目 为例)
当我们搭建好了实验室的环境,根据3GPP的标准,我们可以通过这套环境来定量的测量到一些端到端的音频指标了。同样以ACQUA为例,我们可以测量但不限于:
End-to-End Voice Delay(ms):端到端延时,记录从RD到DUT的端到端的语音延时,涵盖设备和网络的延时。
Echo Attenuation(dB):回声抑制,测量回声被抑制了多少,单位是分贝,一般>60dB的数值回声就不太容易被感知到了。
POLQA: ITU较新的评估语音质量的指标,是以前PESQ的升级版,可以测量32KHz的采样率的语音。一般都通俗的把这类语音质量的评分称为MOS分,1-5分越高说明语音质量越好。
3QUEST: 同样是类似MOS分的语音质量测量,但是专门在噪声环境下进行,噪声声场需要有严格规定,噪声序列还需要参考相关标准。
Loudness Rating (dB):响度评分,测量人工耳可以声压级(SPL), 一般在[-20,20]范围内比较理想。
Idle Channel Noise (dB):空闲信道噪声,测量在没有语音活跃的状态下噪声的舒适度。这个值一般不高于-50dB
Frequency Response (dB): 频响, 在相关标准中有频响曲线的掩蔽区间,测量分对应的是真实频响高于掩蔽区间的分贝数,所以越高越好。
Signal-to-Distortion ratio (dB):信号失真比,在MFE记录下语音信号和失真直接的比值,数值越高说明语音保真度越高。
Double Talk (dB):双讲,记录下语音在近端远端同时说话的时候的抑制情况,分数越低,说明双讲透明度越高,也就是语音的保留度更好。
我们也总结了一下,声网在实践中觉得比较适合开发者自己去做,在上线前自测的一些方法,这里也按我们之前提到的三个归类,网络、设备和物理环境讲一下。
首先,网络部分。
有TC跟NetEM,都可以模拟,如果具体步骤不清楚的同学,可以查看这个教程。
你还在靠“喂喂喂”来测语音通话质量吗,看完这篇文章你就能掌握正确姿势。 https://blog.csdn.net/ljh081231/article/details/54944782/
这里面可能不能涵盖所有的丢包,但是基本上也能测到语音在不同丢包下的表现,可以测到引擎的极限在哪里。声网的引擎基本现在做到在TC下,30%的丢包是无感的,70%的丢包可以正常的通话。
还有一个比较重要的是:跨运营商的测试。这一点很多客户是不重视的,自己在公司内用P2P测觉得很好,一上线就有很多问题。在中国,跨运营商的丢包,或者2G、3G、4G移动网络下会有很多问题,建议大家在这方面做足够测试再上线。
其次,设备的问题。
大家在一些平板电脑测试觉得声学很好,调的也很好,底层也有算法。但是,到安卓之后就变得非常的麻烦。很多低端的安卓机,底层录音的通路没有调好,底噪很大。而且,声学设计不够好,有很多非线性的问题需要适配。而这些问题如果只是在一个比较高端的机器上测,可能是不会体现的。所以,如果你的目标用户中有很多这样的机型,那么一定要在测试中把这一块覆盖好。同时,在听筒、耳机、外放、蓝牙,也需要去测,这些都是会影响用户的体验的细节。、
第三,物理场景。
我们其实没有办法覆盖非常多的场景,建议去下载一些语音降噪的序列、噪声的序列,是免费的,可以在不同的信噪比情况下用来测试。远场拾音,只要测一下不同的说话距离就能感觉到不同的体验。
我相信通过这三步的测试,你的语音引擎是基本可用的。
另外,稍微讲一下一些技术细节。

我们常说的3A引擎是指:回声消除、降噪和自动增益控制,这是所有音频引擎中必须有的模块。在测回声时,需要留意降完回声之后残留的程度;双讲透明度,就是两个人同时说话的时候会有多少声音可以透过去;稳定性是指在安卓上这些CPU比较高的情况之下可以稳定运行的一个时间,收敛时间。 降噪,我降噪完声音的残留噪声的程度和收敛时间。自动增益控制关注两个点,第一收音距离多远,第二,你把声音推大,杂音也会推大,这个部分有没有做特殊的处理?不然有人会说,你的这个声音是很大,但是背景音一起推起来了,这时需要一些算法来做的更好。如果在1米、2米情况下不用AGC声音已经非常小,这里面必须有算法支持它。

上图的三个算法也是比较特殊场景下的算法,声网在这三块也做了比较多的工作。
可懂度增强:如果我在很噪杂的环境,对方传过来的声音是不吵的,但是我听着还是很累,因为我旁边有很多让我分心的声音。这个时候,我们需要去评估现在的环境下的有多噪杂,从而调整下行的信号让你听得更清楚。
盲源分离:指的是我们刚才的降噪说得是平稳噪声,对应在数学上也是用统计模型来做。但是在非平稳信号下,可能需要有多麦技术来定位主讲人声源在哪,主要收主讲人的声音,其他的声音屏蔽。
啸叫抑制:真实环境中并不是很多。在做音频测试时,如果两个手机开着外放,你就会听到很尖锐的杂音一直响。这怎么办?其实很简单,只要把一台插上耳机,把回环的通路打断就不会叫。声网自己做了啸叫抑制的模块,两个手机都外放,即使不插耳机,我们也会把检测到的尖锐杂音自动压下来。
如果做的应用是比较特殊的场景,比如直播、游戏,我们还有特殊的点需要注意。
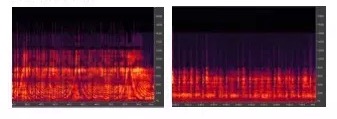
做直播,推流基本用44.1K,但声音有效采样取到多少才是真正重要的。左图是32K的采样,右图那个虽然是44.1K的声源,但其实有效频率是8K,实际听到的声音会变闷的。
ASMR,就是用立体声录音去给听众听到空间感的音频。那声网在手机平台上,第一个做到立体声录音和播放。这意味着,主播可以现在拿着这个立体声的设备走到街上,一辆车开过去,其实直播的听众戴了耳机就能感觉到从左到右的效果。
再讲一下游戏,很特殊的场景。拿一个枪战类的游戏举例,在3D环境里可以听到周围有队友开枪,可以听到哪边交火。如果玩家开了实时语音,自己开着外放。那么玩家开枪的声音通过他的外放再被收回去,这部分回声消除由于没有参考信号就做不了。这个声音传过去会影响对方的判断,直接降低玩家的游戏体验。
上线只是一个开始,上线之后,语音的碎片化问题还会不断出现。那么就需要做两方面的统计。
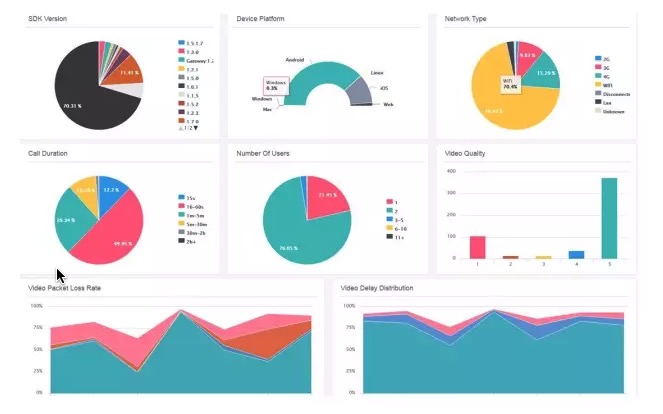
全局监控。来反馈全局质量,是不是大部分用户都比较好?上图是声网做的一个统计,反应每天使用用户大概比例,用什么网络什么系统,音频视频打分如何,丢包率如何?如果你不是使用声网的服务,你自己也需要做这样一套系统,来改进服质量 。
个例分析。全局反馈良好,但依然有用户报问题,我的声音听不到怎么办?声网在实践当中做了这样一套系统,可以根据用户ID去查详细的通话信息:包括一些码率、CPU的情、音频录音大小可以自己看得到,这样子就能定位问题。
以下是现场提问
提问:我问一个关于降噪的问题,你刚才的演示PPT里面没有很清楚,降噪之后背景噪声是消除越干净越好?还是应该是有一定的率?
陈若非:降噪有一个很大的问题,你压得越多噪声越低,语音失真也越大,这是必然的。如果你有一个噪音,失真率很小,如果压得很多,非常干净,这个声音频率上会特别高,听起来尖尖的,不是很舒服。所以这需要你在实践中自己去调到一个你认为最好的点,没有绝对,我不知道这样回答有没有回答你的问题?
网络,设备,物理环境都会影响音频质量,测试评估不要局限于单一环境。
全面的评估一个实时语音引擎需要科学的测试环境搭建和主客观测试流程。
要自己实现实时语音通话功能需要对音频有深入的研究和理解,不要轻信集成开源项目可以一劳永逸。
如果没有足够的开发资源和时间成本来自研实时语音引擎,尽量选择对音频有理解,有售后,靠谱的供应商。
-
频率与音色的听音训练 及 训练音乐听觉
低音频段 LF: 20-200Hz
如果低音频段比较丰满,则音色给人的感觉是浑厚,有空间感。这个频段整个房间包括家具都有共振的频率,因而与房间的大小与家具摆设很有关系。如果这个频段的成分过多和幅度太大(相比于其他频段),会使人感到声音浑浊不清,因而降低了语言和音乐的清晰度。如果这个频段的成分缺乏,音色就会显得单薄。苍白。
中低音频段MID LF:200-600Hz
这个频段是人声和主要乐器的主音区基音的频段。如果这个频段的音色比较丰满则音色显得比较圆润而有力度。因为基音频率丰满了,音乐的表现力度就强,声音就有力。如果这个频段的成分太多强度太大了,音乐就会显得生硬,不自然。因为基音成分过强,相对泛音成分就变弱了,因而音色就缺乏润滑度。如果这个频段的东西缺乏,音乐就会显得软弱无力空虚,音色发散,高低音不合拢,唱歌的歌声就显得中气不足。
中高音频段MID HF:600Hz-6KHz
这是一个人耳听觉比较灵敏的频段。因而影响音乐的明亮度、清晰度和透明度。如果这个频段的成分太多强度太强,音乐就显得尖利,变得呆板;如果这个频段的东西缺 乏,则音乐就显暗淡、朦胧,好像音被蒙上一层薄纱。
高音频段HF:6-20KHz
这个频段的声音强度影响音乐的表现力和细节。如来这个频段的泛音强度适中,音乐的鲜明。相对于前三频段,此频段的电平强度最弱,但对音色的影响却是最大的。可见这个频段的重要。如果这个频段的成分太多和强度太高,声音就尖沙、刺耳、嘶哑;如果这个频段的东西缺乏,音乐就缺乏个性和韵味。
下面再具体看看不同音乐频率细节对音乐音质音色的影响。
20-60Hz此频段影响音乐的空间感。因为音乐的基音大多在这个频段上,并且此频段的频率与房间或厅堂的谐振频率重叠。如果此频段表现充足,会使人感到音场广阔,犹如置身于大堂之中的感觉;如果此频段成分过强,会产生嗡嗡的低频共振声,影响语言的清晰度和可懂度;如果此频段缺乏,音色就显得空虚。
60-100 Hz 此频段影响声音的浑厚度,也是低音的基音区。如果此频段频率适中,音色就浑厚感强;如果此频段过强.声色会出现低频共振声或轰鸣声,如果此频段缺乏,音色就显得无力。
100-150 Hz频段 此频段影响音乐的丰满度。如果此频段成分适中,会产生一种房间的空间感和浑厚感;如果此频段过强,音乐会见得浑浊,语言清晰度变差;如果此频段缺乏,音乐就显得单薄、苍白。
150-300Hz频率 此频段影响声音的力度,特别是男声声音的力度它是男声声音低音的基频频率,同时也是乐音中和弦的根音频率。如果其成分过强,声音就显得生硬不自然;如果其缺乏,音乐会显得发软、发飘,语言则变得软棉棉。
300-500Hz频率 此频段是语言的主要区的频率。如果此频段的幅度丰满,语言就有力度,如果此频段成分过强,音色就显得单调;如果其缺乏,声音就显得空洞、不坚实。
-
语音通信中提高音质的方法
语音通信是实时通信,影响语音质量的因素很多,大致可把这些因素分成两大类:一类是回声噪声等周围环境因素导致语音质量差,另一类是丢包延时等网络环境因素导致语音质量差。这两类因素由于成因不一样,解决方法也不一样。下面就讲讲用哪些方法来提高语音质量
首先看由于周围环境因素导致语音质量差的解决方法。这类方法主要是用信号处理算法来提高音质,不同的因素有不同的处理算法,用回声消除算法把回声消除掉,用噪声抑制算法把噪声抑制住,用自动增益控制算法把音量调整到一个期望的值。这些都是信号处理领域比较专业的算法,好在现在webRTC已经开源,也包括这些算法(AEC/ANS/AGC)。我们只要把这些算法用好就有非常不错的效果。这些算法的调试中AEC相对复杂一些,我在前面的文章中(音频处理之回声消除及调试经验https://www.cnblogs.com/talkaudiodev/p/7441433.html)专门写过怎么调试,有兴趣的可以去看一看。ANS/AGC相对简单,先在Linux下做一个小应用程序验证算法的效果,有可能要调一下参数,找一个相对效果较好的值。验证算法的过程也是熟悉算法怎么使用的过程,对后面把算法应用到方案中是有好处的。
再来看由于网络环境因素导致语音质量差的解决方法。网络环境因素主要包括延时、乱序、丢包、抖动等,又有多种方法来提高音质,主要有抖动缓冲区(Jitter Buffer)、丢包补偿(PLC)、前向纠错(FEC)、重传等,
1,Jitter Buffer
Jitter Buffer主要针对乱序、抖动因素,主要功能是把乱序的包排好序,同时把包缓存一些时间(几十毫秒)来消除语音包间的抖动使播放的更平滑。(音频传输之Jitter Buffer设计与实https://www.cnblogs.com/talkaudiodev/p/8025242.html)中专门写过Jitter Buffer 的设计和实现,有兴趣的可以去看一看

JB在生命周期里也有两种状态:prefetching(预存取)和processing(处理中),只有在processing时才能从JB中取到语音帧。初始化时把状态置成prefetching,当在JB中的语音包个数达到指定的值时便把状态切到processing。如果从JB里取不到语音帧了,它将又回到prefetching。等buffer里语音包个数达到指定值时又重新回到processing状态。
首先看PUT操作。RTP包有包头和负载(payload),为了便于处理,将包头和payload在buffer中分开保存,保存包头中相关属性的叫attribute buffer,保存payload的叫payload buffer。下图是JB里存RTP包的buffer关系图:
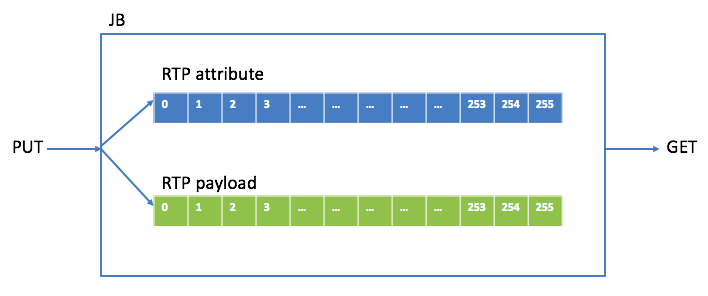
要明确哪几种类型的RTP包会被PUT进JB,我最初设计JB时类型有G711/G722/G729/SID(静音包)/RFC2833(DTMF包)。
G711/G722十毫秒payload是80个字节,G729十毫秒payload是10个字节
为了确定payload buffer中一个block的大小(取这些类型中最大的,80个字节),
attribute buffer中一个block的大小是固定的,即要保存的属性的个数(这些属性主要用于控制payload的存放和读取,有media type(G711/G722/G729/SID/RFC2833),sequence number,timestamp,ssrc,payload size,相对应的存放payload的buffer block指针等。
每个RTP的包头占一个attribute buffer block,
但每个RTP的payload有可能占几个payload buffer block,这跟media type 和packet time有关,
例如一个packet time为20ms的G711包,就需要两个payload buffer block,attribute buffer block和payload buffer block之间有一个映射关系。将attribute buffer block和payload buffer block个数都定为256(index从0到255,设定256是为了早到的包绝不会把前面的包给覆盖掉,如果block个数小了则有可能),这样JB 里最少可以存2560ms的语音数据。
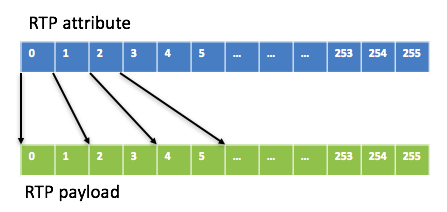
至于JB里最多能放多少个包(即容量capacity),这取决于media type和packet time。如果media type是G711/G7
22, capacity = 256*10/packet time,例如当packet time为20ms时,capacity是128,即最多放128个包。这样attribute buffer和payload buffer的映射关系如下图:
从网络上来的RTP包有可能是乱序的,PUT操作要把这些乱序的包(attribute & payload)放在buffer里正确的block里,这主要依靠attribute里的sequence number和timestamp做判断。RTP协议里sequence number数据类型是unsigned short,范围是0~65535,就存在从65535到0的转换,这增加了复杂度。对于收到的RTP包,首先要看它是否来的太迟(相对于上一个已经取出的包),太迟了就要把这个包主动丢弃掉。设上一个已经取出的包的sequence number为 last_got_senq,timestamp 为last_got_timestamp,当前收到的将要放的包的sequence number为 cur_senq,timestamp 为cur_timestamp,当前包的sequence number与上一个取走的sequence number的gap为delta_senq,则delta_senq可以根据下面的逻辑关系得到。

如果delta_senq小于1,就可以认为这个包来的太迟,就要主动丢弃掉。由于我们的buffer足够大(256个block),如果包早到了也会被放到对应的position上,不会把相应位置上的还没取走的覆盖掉。
接下来看怎么把包放到正确的位置上。对于收到的第一个包,它的位置(position,范围是0 ~ capacity-1)是sequence number % capacity。后面的包放的position依赖于它上一个已放好的包的position。设上一个已放好的包的sequence number为 last_put_senq,timestamp 为last_put_timestamp,position为last_put_position,当前收到的将要放的包的sequence number为 cur_senq,timestamp 为cur_timestamp,position为cur_position,当前的包的sequence number与上一个放好的sequence number的gap为delta_senq,则cur_position可以根据下面的逻辑关系得到。

得到了当前包的position后就可以把包头里的timestamp等放到相应的attribute buffer block里了,payload根据算好的占几个block放到相应的那几个block上(有可能填不满block,不过没关系,取payload时是根据index取的)。如果放进对应block时发现里面已经有包了并且sequence number一样,说明这个包是重复包,就要把这个包主动丢弃掉。
再来看GET操作。每次从JB里不是取一个包,而是取1帧(能编解码的最小单位,通常是10ms,也有例外,比如AMR-WB是20ms),这主要是因为播放loop是10ms一次(每次都是取一帧语音数据播放)。取时总是从head上取,开始时head为第一个放进JB的包的position,每取完一个包(几帧)后head就会向后移一个位置。如果到某个位置时它的block里没有包,就说明这个包丢了,这时取出的就是payload大小就是0,告诉后续的decoder要做PLC。不同类型的包取法不一样,下面分别加以介绍。
再来看一下在哪些情况下需要reset JB,让JB在初始状态下开始运行。
1)当收到的语音包的媒体类型(G711/G722/G729,不包括SID/RFC2833等)变了,就认为来了新的stream,需要reset JB。
2)当收到的语音包的SSRC变了,就认为来了新的stream,需要reset JB。
3)当收到的语音包的packet time变了,就认为来了新的stream,需要reset JB。
前面说过JB是语音通信接收侧最重要的模块之一,当然它也是容易出问题的模块之一。出问题不怕,关键是怎么快速定位问题。对于JB来说,需要知道当前的运行状态以及一些统计信息等。如果这些信息正常,就说明问题很大可能不是由JB引起的,不正常则说明有很大的可能性。这些信息主要如下:
1)JB当前运行状态:prefetching / processing
2)JB里有多少个缓存的包
3)从JB中取帧的head的位置
4)缓冲区的capacity是多少
5)网络丢包的个数
6)由于来的太迟而被主动丢弃的包的个数
7)由于JB里已有这个包而被主动丢弃的包的个数
8)进prefetching状态的次数(除了第一次)
上面就是JB设计的主要思想,在实现时还有很多细节需要注意,这里就不一一详细说了。我第一次设计实现JB是在2011年,当时从设计实现到调试完成(指标是:bulk call > 10000次,long call time > 60 小时,各种场景下的各种codec的语音质量要达标)总共花了近三个月,还是在对JB有基础的情况下,要是没基础花的时间更多。从设计到能打电话时间不长,主要是后面要过bulk call/long call/voice quality。有好多情况设计时没考虑到,这也是一个迭代的过程,当调试完成了设计也更完整了。最初设计时只支持G711/G722/G729这三种codec,但是机制定了。后来系统要支持AMR-WB,JB这部分根据现有的机制再加上AMR-WB特有的很快就调好了。
2,FEC
FEC主要针对丢包这种因素。FEC属于信道编码。语音上利用FEC来做补偿主要是在发端对发出的RTP包(几个为一组,称为原始包)FEC编码生成冗余包发给收端,收端收到冗余包后结合FEC解码得到原始的RTP包从而把丢掉的RTP包补上。至于生成几个冗余包,这取决于收方反馈过来的丢包率。例如原始包5个为一组,丢包率为30%,经过FEC编码后需要生成两个冗余包,把这7个包都发给对方。对方收到原始包和冗余包的个数和只要达到5个就可以通过FEC完美复原出5个原始包,这5个原始包中丢掉的就通过这种方式补偿出来了。原始RTP包有包头和payload,冗余包中还要加上一个FEC头(在RTP头和payload中间),FEC头结构如下:

其中Group first Sequence number是指这一组原始包中第一个的sequence number,original count是指一组原始包的个数,redundant count是指生成的冗余包的个数,Redundant index是指第几个冗余包。冗余包有自己的payload type 和sequence number,要在SIP的SDP中告诉对方冗余包的payload type是多少,对方收到这个payload type的包后就做冗余包处理。
FEC不依赖与语音包内的payload,对于丢失的包能精确的复原出来。但是它也有缺点,一是它要累积到指定数量的包才能精确的复原,这就增加了时延;二是它要产生冗余包发送给对方,增加了流量。
3,PLC
PLC也主要针对丢包因素。它本质上是一种信号处理方法,利用前面收到的一个或者几个包来近似的产生出当前丢的包。产生补偿包的技术有很多种,比如基音波形复制(G711 Appendix A PLC用的就是这种技术)、波形相似叠加技术(WSOLA)、基音同步叠加(PSOLA)技术等,这些都很专业,有兴趣可以找相关的文章看看。对codec而言,如果支持PLC功能,如G729,就不需要再在外部加PLC功能了,只需要对codec做相应的配置,让它的PLC功能使能。如果不支持PLC功能,如G711,就需要在外部实现PLC。
PLC对小的丢包率(< 15%)有比较好的效果,大的丢包率效果就不好了,尤其是连续丢包,第一个丢的包补偿效果还不错,越到后面丢的包效果越差。
把Jitter Buffer、FEC、PLC结合起来就可以得到如下的接收侧针对网络环境因素的提高音质方案:
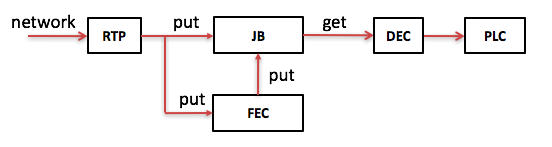
从网络收到的RTP包如是原始包不仅要PUT进JB,还要PUT进FEC。如是冗余包则只PUT进FEC,在FEC中如果一组包中原始包的个数加上冗余包的个数达到指定值就开始做FEC解码得到丢失的原始包,并把那些丢失的原始包PUT进JB。在需要的时候把语音帧从JB中GET出解码并有可能做PLC。
4,重传
重传也主要针对丢包这种因素,把丢掉的包再重新传给对方,一般都是采用按需重传的方法。我在用重传的方法时是这样做的:接收方把收到的包排好序后放在buffer里,如果收到RTP包头中的sequence number能被5整除(即模5),就统计一下这个包前面未被播放的包有哪些没收到(即buffer里相应位置为空), 采用比特位的方式记录下来(当前能被5整除的包的前一个包用比特位0表示,丢包置1,不丢包置0,比特位共16位(short型),所以做多可以看到前16个包是否有丢包),然后组成一个控制包(控制包的payload有两方面信息:当前能被5整除的包的sequence number(short型)以及上面组成的16位的比特位)发给对方,让对方重发这些包。接收方收到这个控制包后就能解析出哪些包丢了,然后重传这些包。在控制包的payload里面也可以把每个丢了的包的sequence number发给对方,这里用比特位主要是减小payload大小,省流量。
在实际使用中重传起的效果不大,主要是因为经常重传包来的太迟,已经错过了播放窗口而只能主动丢弃了。它是这些方法中效果最差的一个。
- 参考:
靠“喂喂喂”来测试实时语音质量靠谱吗?https://blog.csdn.net/agora_cloud/article/details/53007099
你还在靠“喂喂喂”来测语音通话质量吗,看完这篇文章你就能掌握正确姿势。 https://blog.csdn.net/agora_cloud/article/details/51851392
声音“三要素”---响度(loudness),音高(pitch),音色(timbre)
https://blog.csdn.net/junllee/article/details/7217435
关于音质评价
https://blog.csdn.net/junllee/article/details/6070881
频率与音色的听音训练 及 训练音乐听觉
https://blog.csdn.net/weixin_43153548/article/details/82731907
语音通信中提高音质的方法
https://blog.csdn.net/david_tym/article/details/80698478
音频软件开发中的debug方法和工具
https://www.cnblogs.com/talkaudiodev/p/7400252.html
最后
以上就是高挑帅哥最近收集整理的关于分析评估和定位声音质量我们也总结了一下,声网在实践中觉得比较适合开发者自己去做,在上线前自测的一些方法,这里也按我们之前提到的三个归类,网络、设备和物理环境讲一下。频率与音色的听音训练 及 训练音乐听觉语音通信中提高音质的方法的全部内容,更多相关分析评估和定位声音质量我们也总结了一下,声网在实践中觉得比较适合开发者自己去做,在上线前自测的一些方法,这里也按我们之前提到的三个归类,网络、设备和物理环境讲一下。频率与音色的听音训练内容请搜索靠谱客的其他文章。








发表评论 取消回复